Modell mit AI Toolkit für VS Code konvertieren
Modellkonvertierung ist eine integrierte Entwicklungsumgebung, die Entwicklern und KI-Ingenieuren hilft, vortrainierte Machine-Learning-Modelle auf ihrer lokalen Windows-Plattform zu konvertieren, zu quantisieren, zu optimieren und zu bewerten. Sie bietet eine optimierte End-to-End-Erfahrung für Modelle, die von Quellen wie Hugging Face konvertiert wurden, sie optimiert und die Inferenz auf lokalen Geräten mit NPUs, GPUs und CPUs ermöglicht.
Voraussetzungen
- VS Code muss installiert sein. Befolgen Sie diese Schritte, um VS Code einzurichten.
- Die AI Toolkit-Erweiterung muss installiert sein. Weitere Informationen finden Sie unter AI Toolkit installieren.
Projekt erstellen
Die Erstellung eines Projekts in der Modellkonvertierung ist der erste Schritt zur Konvertierung, Optimierung, Quantisierung und Bewertung von Machine-Learning-Modellen.
-
Öffnen Sie die AI Toolkit-Ansicht und wählen Sie Modelle > Konvertierung, um die Modellkonvertierung zu starten.
-
Starten Sie ein neues Projekt, indem Sie Neues Modellprojekt auswählen.
-
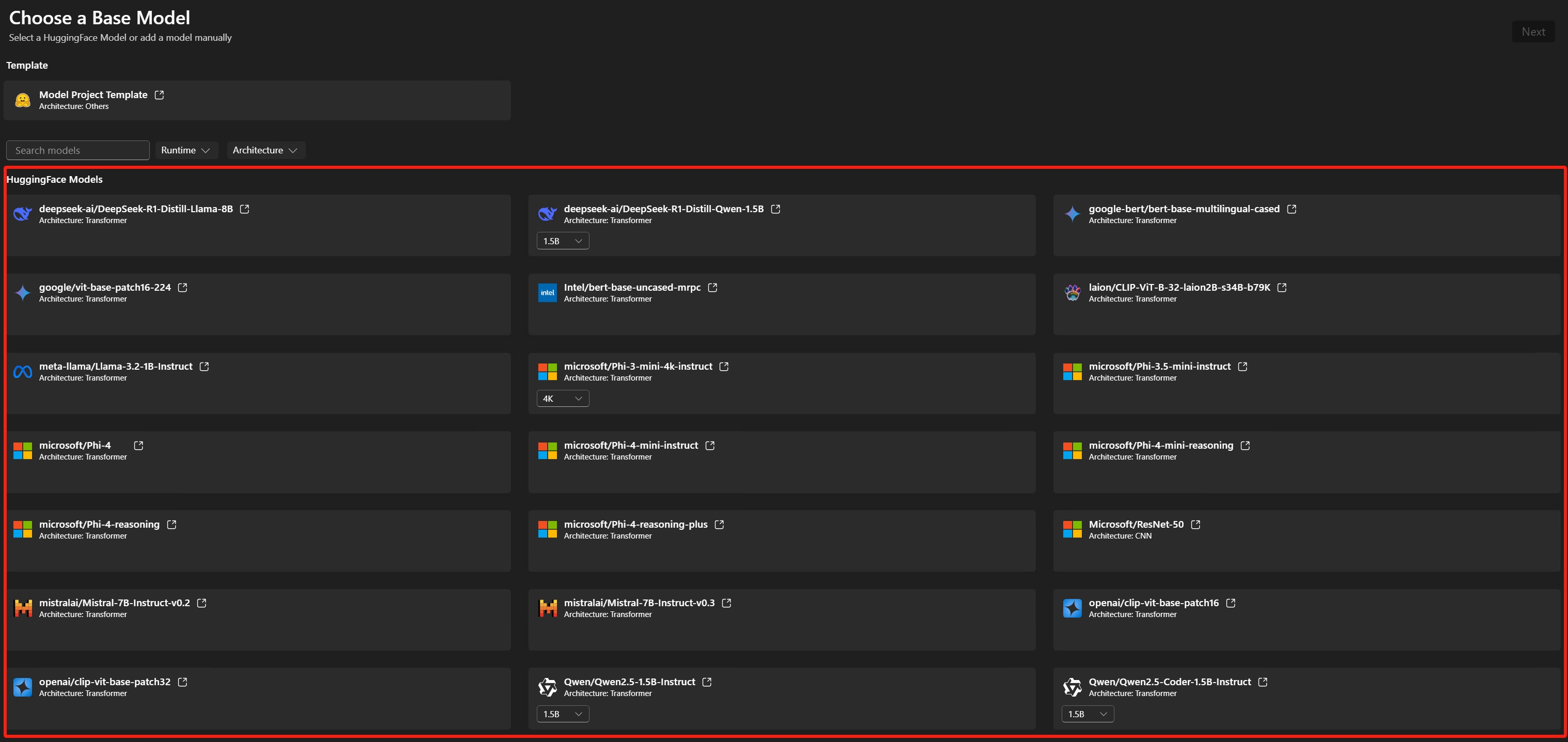
Basismodell auswählen
Hugging Face Modell: Wählen Sie das Basismodell mit vordefinierten Rezepten aus der unterstützten Modellliste aus.Modellvorlage: Wenn das Modell nicht im Basismodell enthalten ist, wählen Sie eine leere Vorlage für Ihre benutzerdefinierten Rezepte (fortgeschrittenes Szenario).
-
Projektdetails eingeben: ein eindeutiger Projektordner und ein Projektname.
Ein neuer Ordner mit dem angegebenen Projektnamen wird an dem von Ihnen ausgewählten Speicherort für die Projektdateien erstellt.
Wenn Sie zum ersten Mal ein Modellprojekt erstellen, kann die Einrichtung der Umgebung eine Weile dauern. Es ist in Ordnung, wenn Sie die Einrichtung nicht abschließen. Sie können die Umgebung bei Bedarf erneut einrichten.

Jedes Projekt enthält eine README.md-Datei. Wenn Sie sie schließen, können Sie sie über den Arbeitsbereich wieder öffnen. 
Unterstützte Modelle
Die Modellkonvertierung unterstützt derzeit eine wachsende Liste von Modellen, darunter Top-Hugging-Face-Modelle im PyTorch-Format. Die detaillierte Modellliste finden Sie unter: Modellliste
(Optional) Modell zu einem bestehenden Projekt hinzufügen
-
Modellprojekt öffnen
-
Wählen Sie Modelle > Konvertierung und dann im rechten Bereich Modelle hinzufügen.
-
Wählen Sie ein Basismodell oder eine Vorlage aus und klicken Sie dann auf Hinzufügen.
Ein Ordner mit den neuen Modelldateien wird im aktuellen Projektordner erstellt.
(Optional) Neues Modellprojekt erstellen
-
Modellprojekt öffnen
-
Wählen Sie Modelle > Konvertierung und dann im rechten Bereich Neues Projekt.
-
Alternativ können Sie das aktuelle Modellprojekt schließen und ein neues Projekt erstellen von Grund auf.
(Optional) Modellprojekt löschen
-
Öffnen Sie das Modellprojekt und wählen Sie Modelle > Konvertierung.
-
Wählen Sie in der Ansicht oben rechts die drei Punkte (...) und dann Löschen, um das aktuell ausgewählte Modellprojekt zu löschen.
Workflow ausführen
Die Ausführung eines Workflows in der Modellkonvertierung ist der Kernschritt, der das vortrainierte ML-Modell in ein optimiertes und quantisiertes ONNX-Modell umwandelt.
-
Wählen Sie in VS Code Datei > Ordner öffnen, um den Modellprojektordner zu öffnen.
-
Workflow-Konfiguration überprüfen
- Wählen Sie Modelle > Konvertierung
- Wählen Sie die Workflow-Vorlage aus, um das Konvertierungsrezept anzuzeigen.
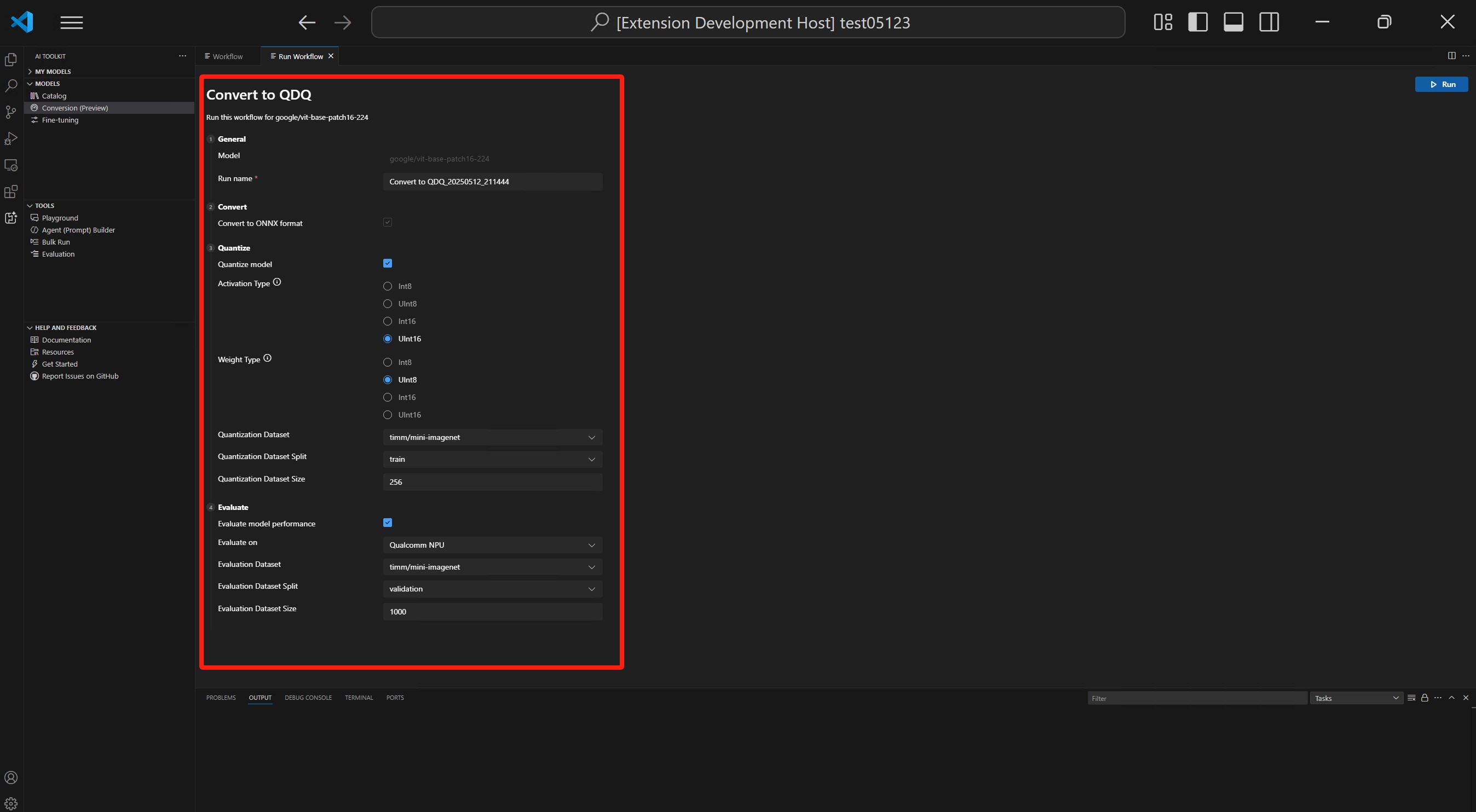
Konvertierung
Der Workflow führt immer den Konvertierungsschritt aus, der das Modell in das ONNX-Format umwandelt. Dieser Schritt kann nicht deaktiviert werden.
Quantisierung
In diesem Abschnitt können Sie die Parameter für die Quantisierung konfigurieren.
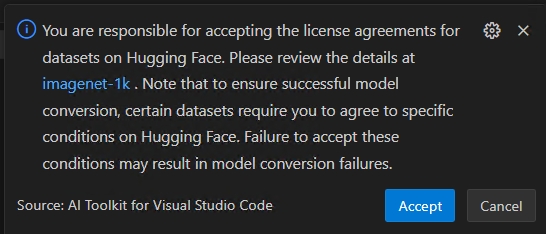
WichtigHugging Face Compliance-Hinweise: Während der Quantisierung benötigen wir Kalibrierungsdatensätze. Möglicherweise werden Sie aufgefordert, Lizenzbedingungen zu akzeptieren, bevor Sie fortfahren. Wenn Sie die Benachrichtigung verpasst haben, wird der laufende Prozess unterbrochen und wartet auf Ihre Eingabe. Stellen Sie sicher, dass Benachrichtigungen aktiviert sind und Sie die erforderlichen Lizenzen akzeptieren.
-
Aktivierungstyp: Dies ist der Datentyp, der zur Darstellung der Zwischenausgaben (Aktivierungen) jeder Schicht in der neuronalen Netzwerkschicht verwendet wird.
-
Gewichtungstyp: Dies ist der Datentyp, der zur Darstellung der erlernten Parameter (Gewichte) des Modells verwendet wird.
-
Quantisierungsdatensatz: Kalibrierungsdatensatz für die Quantisierung.
Wenn Ihr Workflow einen Datensatz verwendet, der eine Lizenzvereinbarungsprüfung auf Hugging Face erfordert (z. B. ImageNet-1k), werden Sie aufgefordert, die Bedingungen auf der Datensatzseite zu akzeptieren, bevor Sie fortfahren. Dies ist für die Einhaltung gesetzlicher Vorschriften erforderlich.
-
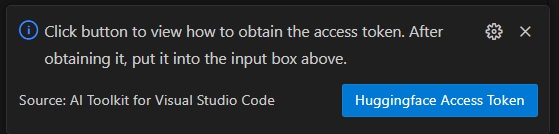
Wählen Sie die Schaltfläche HuggingFace Access Token, um Ihr Hugging Face Access Token zu erhalten.
-
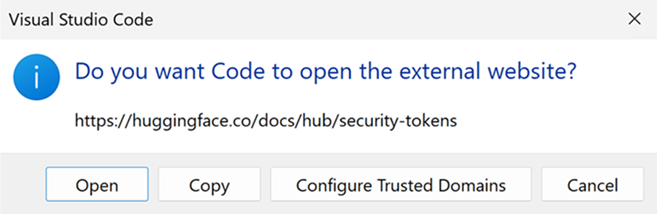
Wählen Sie Öffnen, um die Hugging Face-Website zu öffnen.
-
Holen Sie sich Ihren Token auf dem Hugging Face-Portal und fügen Sie ihn in Quick Pick ein. Drücken Sie Enter.

-
-
Quantisierungsdatensatz-Split: Datensätze können verschiedene Splits wie Validierung, Training und Test haben.
-
Quantisierungsdatensatzgröße: Die Anzahl der Daten, die zur Quantisierung des Modells verwendet werden.
Weitere Informationen zu Aktivierungs- und Gewichtungstypen finden Sie unter Datentyp-Auswahl.
Sie können diesen Abschnitt auch deaktivieren. In diesem Fall wird der Workflow das Modell nur in das ONNX-Format konvertieren, aber nicht quantisieren.
Bewertung
In diesem Abschnitt müssen Sie den auszuführenden Anbieter (EP) für die Bewertung auswählen, unabhängig von der Plattform, auf der das Modell konvertiert wurde.
- Bewerten auf: Das Zielgerät, auf dem Sie das Modell bewerten möchten. Mögliche Werte sind
- Qualcomm NPU: Um dies zu verwenden, benötigen Sie ein kompatibles Qualcomm-Gerät.
- AMD NPU: Um dies zu verwenden, benötigen Sie ein Gerät mit einer unterstützten AMD NPU.
- Intel CPU/GPU/NPU: Um dies zu verwenden, benötigen Sie ein Gerät mit einer unterstützten Intel CPU/GPU/NPU.
- NVIDIA TRT für RTX: Um dies zu verwenden, benötigen Sie ein Gerät mit einer Nvidia-GPU, die TensorRT für RTX unterstützt.
- DirectML: Um dies zu verwenden, benötigen Sie ein Gerät mit einer GPU, die DirectML unterstützt.
- CPU: Jede CPU kann funktionieren.
- Evaluierungsdatensatz: Datensatz für die Evaluierung.
- Evaluierungsdatensatz-Split: Datensätze können verschiedene Splits wie Validierung, Training und Test haben.
- Evaluierungsdatensatzgröße: Die Anzahl der Daten, die zur Bewertung des Modells verwendet werden.
Sie können diesen Abschnitt auch deaktivieren. In diesem Fall wird der Workflow das Modell nur in das ONNX-Format konvertieren, aber nicht bewerten.
-
Workflow ausführen, indem Sie Ausführen auswählen.
Ein Standard-Auftragsname wird mit dem Workflow-Namen und dem Zeitstempel generiert (z. B.
bert_qdq_2025-05-06_20-45-00) zur einfachen Nachverfolgung.Während der Ausführung des Auftrags können Sie den Auftrag Abbrechen, indem Sie den Statusindikator oder das Drei-Punkte-Menü unter Aktion im Verlaufs-Board auswählen und dann Ausführung stoppen auswählen.
Hugging Face Compliance-Hinweise: Während der Quantisierung benötigen wir Kalibrierungsdatensätze. Möglicherweise werden Sie aufgefordert, Lizenzbedingungen zu akzeptieren, bevor Sie fortfahren. Wenn Sie die Benachrichtigung verpasst haben, wird der laufende Prozess unterbrochen und wartet auf Ihre Eingabe. Stellen Sie sicher, dass Benachrichtigungen aktiviert sind und Sie die erforderlichen Lizenzen akzeptieren.
-
(Optional) Modellkonvertierung in der Cloud ausführen
Cloud-Konvertierung ermöglicht es Ihnen, Modellkonvertierung und -quantisierung in der Cloud auszuführen, wenn Ihr lokaler Computer nicht über genügend Rechen- oder Speicherkapazität verfügt. Sie benötigen ein Azure-Abonnement, um Cloud-Konvertierung zu nutzen.
-
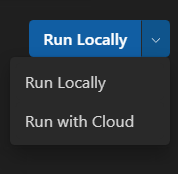
Wählen Sie Mit Cloud ausführen aus dem Dropdown-Menü oben rechts. Beachten Sie, dass der Abschnitt Bewertung deaktiviert ist, da die Cloud-Umgebung keine Zielprozessoren für die Inferenz hat.
-
AI Toolkit prüft zuerst, ob Azure-Ressourcen für die Cloud-Konvertierung vorbereitet sind. Falls erforderlich, werden Sie nach Ihrem Azure-Abonnement und Ihrer Ressourcengruppe zur Bereitstellung von Azure-Ressourcen aufgefordert.

-
Nach Abschluss der Bereitstellung wird die Bereitstellungskonfiguration in
model_lab.workspace.provision.configim Stammordner Ihres Arbeitsbereichs gespeichert. Diese Informationen werden zwischengespeichert, um Azure-Ressourcen wiederzuverwenden und den Cloud-Konvertierungsprozess zu beschleunigen. Wenn Sie neue Ressourcen verwenden möchten, löschen Sie diese Datei und führen Sie die Cloud-Konvertierung erneut aus. -
Ein Azure Container App (ACA)-Auftrag wird ausgelöst, um die Cloud-Konvertierung auszuführen. Für einen laufenden Auftrag können Sie
- Wählen Sie den Statuslink aus, um zur Azure ACA Job Execution History-Seite zu navigieren.
- Wählen Sie Protokolle aus, um zu Azure Log Analytics zu navigieren.
- Wählen Sie die Schaltfläche Aktualisieren, um den aktuellen Auftragsstatus abzurufen.

-
Wenn Sie keine GPU für die LLM-Modellkonvertierung zur Verfügung haben, können Sie Mit Cloud ausführen verwenden. Die Option „Mit Cloud ausführen“ unterstützt nur Modellkonvertierung und -quantisierung. Sie müssen das konvertierte Modell für die Bewertung auf Ihren lokalen Computer herunterladen.
Mit Cloud ausführen unterstützt keine Modellkonvertierung mit DirectML- oder NVIDIA TRT für RTX-Workflows.
Die Spalte Empfohlen zeigt den empfohlenen Workflow an, je nachdem, ob Ihr Gerät bereit ist, das konvertierte Modell auszuführen oder nicht. Sie können trotzdem den Workflow auswählen, den Sie bevorzugen. Modellkonvertierung und -quantisierung: Sie können Workflows auf jedem Gerät ausführen, außer für LLM-Modelle. Die Quantisierungskonfiguration ist nur für NPU optimiert. Es wird empfohlen, diesen Schritt zu deaktivieren, wenn das Zielsystem keine NPU ist.
LLM-Modellquantisierung: Wenn Sie LLM-Modelle quantisieren möchten, ist eine Nvidia-GPU erforderlich.
Wenn Sie das Modell auf einem anderen Gerät mit GPU quantisieren möchten, können Sie die Umgebung selbst einrichten. Informationen finden Sie unter Manuelle GPU-Konvertierung. Beachten Sie, dass nur der Schritt „Quantisierung“ eine GPU benötigt. Nach der Quantisierung können Sie das Modell auf NPU oder CPU bewerten.
Tipps zur Neubewertung
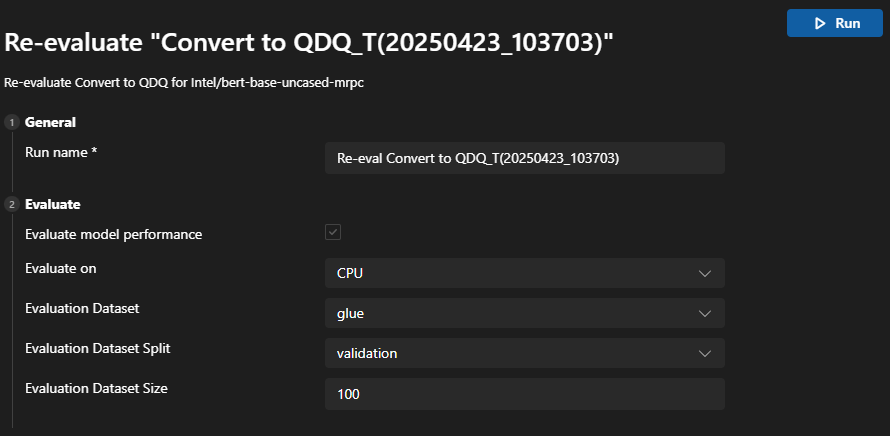
Nachdem ein Modell erfolgreich konvertiert wurde, können Sie die Neubewertungsfunktion verwenden, um die Bewertung erneut durchzuführen, ohne das Modell zu konvertieren.
Gehen Sie zum Verlaufs-Board und finden Sie den Modelllauf-Auftrag. Wählen Sie das Drei-Punkte-Menü unter Aktion, um das Modell neu zu bewerten.
Sie können verschiedene EPs oder Datensätze für die Neubewertung auswählen.
Tipps für fehlgeschlagene Aufträge
Wenn Ihr Auftrag abgebrochen oder fehlgeschlagen ist, können Sie den Auftragsnamen auswählen, um den Workflow anzupassen und den Auftrag erneut auszuführen. Um versehentliche Überschreibungen zu vermeiden, erstellt jede Ausführung einen neuen Verlaufsordner mit seiner eigenen Konfiguration und seinen Ergebnissen.
Einige Workflows erfordern möglicherweise, dass Sie sich zuerst bei Hugging Face anmelden. Wenn Ihr Auftrag mit einer Ausgabe wie huggingface_hub.errors.LocalTokenNotFoundError: Token is required ('token=True'), but no token found. You need to provide a token or be logged in to Hugging Face with 'hf auth login' or 'huggingface_hub.login' fehlgeschlagen ist, navigieren Sie zu https://huggingface.co/settings/tokens und folgen Sie den Anweisungen, um den Anmeldevorgang abzuschließen, und versuchen Sie es dann erneut.
Wenn Ihre Neubewertung mit der Warnung Microsoft Visual C++ Redistributable is not installed fehlgeschlagen ist, müssen Sie die folgenden Pakete manuell installieren
- Microsoft Visual C++ Redistributable
- (Optional für ARM64) Laden Sie es von Microsoft C++ Build Tools herunter. Überprüfen Sie während der Installation auch die Workload
Desktopentwicklung mit C++.
Ergebnisse anzeigen
Das Verlaufs-Board in Konvertierung ist Ihr zentrales Dashboard für die Nachverfolgung, Überprüfung und Verwaltung aller Workflow-Ausführungen. Jedes Mal, wenn Sie eine Modellkonvertierung und -bewertung durchführen, wird ein neuer Eintrag im Verlaufs-Board erstellt – so wird vollständige Nachverfolgbarkeit und Reproduzierbarkeit gewährleistet.
-
Finden Sie die Workflow-Ausführung, die Sie überprüfen möchten. Jede Ausführung wird mit einem Statusindikator (z. B. Erfolgreich, Abgebrochen) aufgeführt.
-
Wählen Sie den Ausführungsnamen aus, um die Konvertierungskonfigurationen anzuzeigen.
-
Wählen Sie die Protokolle unter dem Statusindikator aus, um Protokolle und detaillierte Ausführungsergebnisse anzuzeigen.
-
Sobald das Modell erfolgreich konvertiert wurde, können Sie die Bewertungsergebnisse unter Metriken anzeigen. Metriken wie Genauigkeit, Latenz und Durchsatz werden neben jeder Ausführung angezeigt.

-
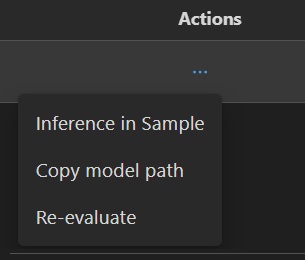
Sie können das Drei-Punkte-Menü unter Aktion auswählen, um mit dem konvertierten Modell zu interagieren.
Pfad des konvertierten Modells kopieren
- Wählen Sie Modellpfad kopieren aus dem Dropdown-Menü. Der Ausgabepfad des konvertierten Modells, z. B.
c:/{workspace}/{model_project}/history/{workflow}/model/model.onnx, wird in Ihre Zwischenablage kopiert. Für LLM-Modelle wird der Ausgabeordner kopiert.
Beispiel-Notebook für Modellinferenz verwenden
- Wählen Sie Inferenz in Beispiel aus dem Dropdown-Menü.
- Python-Umgebung auswählen
- Sie werden aufgefordert, eine virtuelle Python-Umgebung auszuwählen. Die Standardlaufzeit ist:
C:\Users\{user_name}\.aitk\bin\model_lab_runtime\Python-WCR-win32-x64-3.12.9. - Beachten Sie, dass die Standardlaufzeit alles Notwendige enthält, andernfalls installieren Sie manuell requirements.txt.
- Sie werden aufgefordert, eine virtuelle Python-Umgebung auszuwählen. Die Standardlaufzeit ist:
- Das Beispiel wird in einem Jupyter Notebook gestartet. Sie können die Eingabedaten oder Parameter anpassen, um verschiedene Szenarien zu testen.
Bei Modellen, die Cloud-Konvertierung verwenden, wählen Sie nach dem Status Erfolgreich das Cloud-Download-Symbol aus, um das Ausgabemodell auf Ihren lokalen Computer herunterzuladen. 
Um das Überschreiben vorhandener lokaler Dateien, wie z. B. Konfigurations- oder verlaufsbezogene Dateien, zu vermeiden, werden nur fehlende Dateien heruntergeladen. Wenn Sie eine saubere Kopie herunterladen möchten, löschen Sie zuerst den lokalen Ordner und laden Sie ihn dann erneut herunter.
Modellkompatibilität: Stellen Sie sicher, dass das konvertierte Modell die angegebenen EPs in den Inferenzbeispielen unterstützt.
Beispielort: Inferenzbeispiele werden zusammen mit den Ausführungsartefakten im Verlaufsordner gespeichert.
Exportieren und mit anderen teilen
Gehen Sie zum Verlaufs-Board. Wählen Sie Exportieren, um das Modellprojekt mit anderen zu teilen. Dies kopiert das Modellprojekt ohne den Verlaufsordner. Wenn Sie Modelle mit anderen teilen möchten, wählen Sie die entsprechenden Aufträge aus. Dies kopiert den ausgewählten Verlaufsordner, der das Modell und seine Konfiguration enthält.
Was Sie gelernt haben
In diesem Artikel haben Sie gelernt, wie Sie
- Erstellen Sie ein Modellkonvertierungsprojekt in AI Toolkit für VS Code.
- Konfigurieren Sie den Konvertierungs-Workflow, einschließlich Quantisierungs- und Bewertungseinstellungen.
- Führen Sie den Konvertierungs-Workflow aus, um ein vortrainiertes Modell in ein optimiertes ONNX-Modell umzuwandeln.
- Zeigen Sie die Ergebnisse der Konvertierung an, einschließlich Metriken und Protokollen.
- Verwenden Sie das Beispiel-Notebook für Modellinferenz und -tests.
- Exportieren und teilen Sie das Modellprojekt mit anderen.
- Bewerten Sie ein Modell mit unterschiedlichen Ausführungsanbietern oder Datensätzen neu.
- Bearbeiten Sie fehlgeschlagene Aufträge und passen Sie Konfigurationen für erneute Ausführungen an.
- Verstehen Sie die unterstützten Modelle und ihre Anforderungen für Konvertierung und Quantisierung.