Modelle, Prompts und Agenten auswerten
Sie können Modelle, Prompts und Agenten auswerten, indem Sie deren Ausgaben mit Ground-Truth-Daten vergleichen und Evaluationsmetriken berechnen. Das AI Toolkit vereinfacht diesen Prozess. Laden Sie Datensätze hoch und führen Sie umfassende Auswertungen mit minimalem Aufwand durch.
Prompts und Agenten auswerten
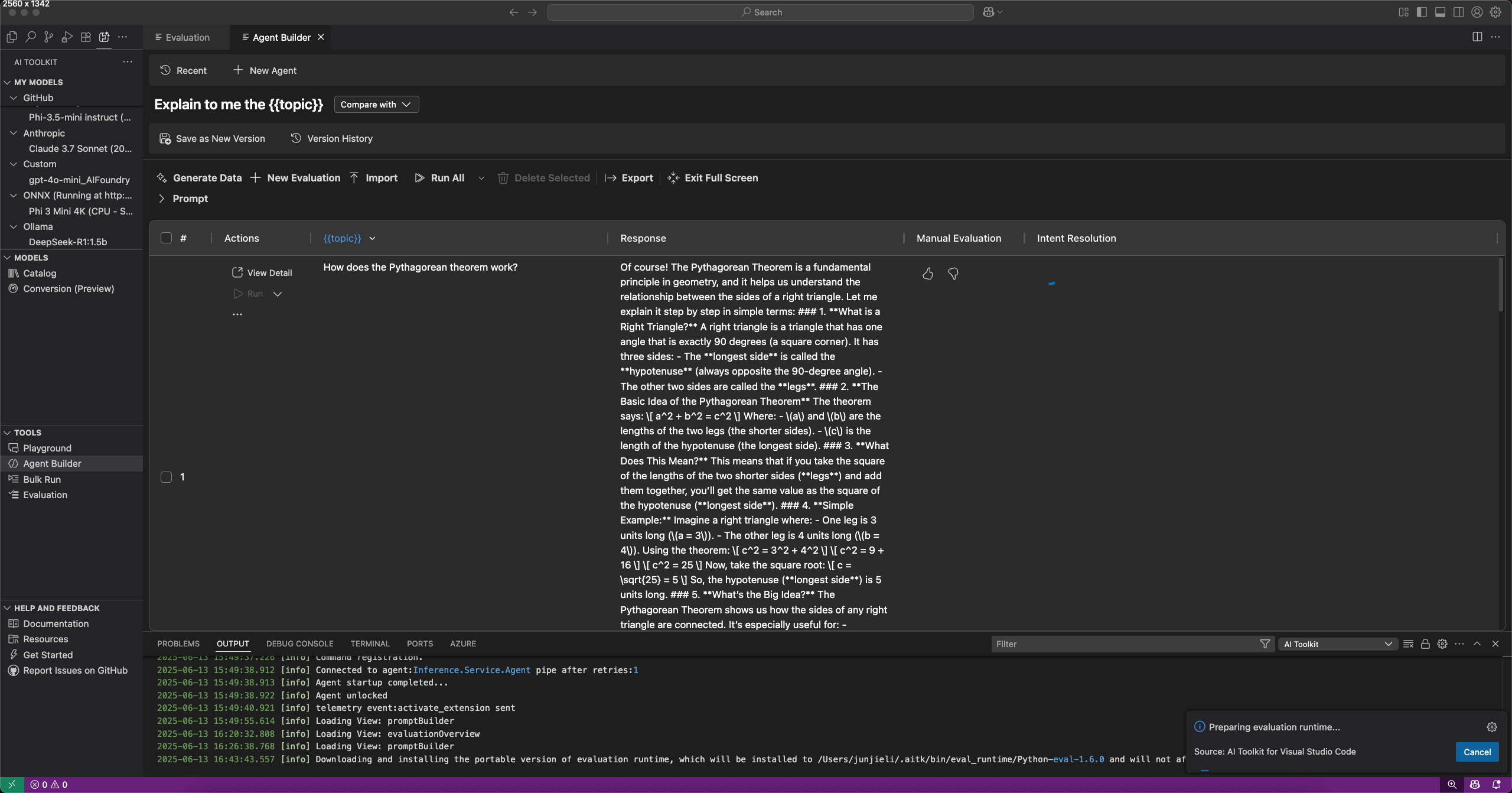
Sie können Prompts und Agenten im Agent Builder auswerten, indem Sie die Registerkarte Evaluation auswählen. Führen Sie vor der Auswertung Ihre Prompts oder Agenten gegen einen Datensatz aus. Lesen Sie mehr über Bulk run, um zu erfahren, wie Sie mit einem Datensatz arbeiten.
Um Prompts oder Agenten auszuwerten
- Wählen Sie im Agent Builder die Registerkarte Evaluation aus.
- Fügen Sie den Datensatz hinzu und führen Sie ihn zur Auswertung aus.
- Verwenden Sie die Daumen hoch und runter Symbole, um Antworten zu bewerten und Ihre manuelle Auswertung zu protokollieren.
- Um einen Auswerter hinzuzufügen, wählen Sie New Evaluation.
- Wählen Sie einen Auswerter aus der Liste der integrierten Auswerter, wie z. B. F1-Score, Relevanz, Kohärenz oder Ähnlichkeit.Hinweis
Bei Verwendung von GitHub-gehosteten Modellen für die Auswertung können Ratenbegrenzungen gelten.
- Wählen Sie ein Modell als Bewertungsmodell für die Auswertung aus, falls erforderlich.
- Wählen Sie Run Evaluation, um den Auswertungsjob zu starten.
Versionierung und Vergleich von Auswertungen
Das AI Toolkit unterstützt die Versionierung von Prompts und Agenten, sodass Sie die Leistung verschiedener Versionen vergleichen können. Wenn Sie eine neue Version erstellen, können Sie Auswertungen durchführen und die Ergebnisse mit früheren Versionen vergleichen.
Um eine neue Version eines Prompts oder Agenten zu speichern
- Definieren Sie im Agent Builder den System- oder Benutzerprompt, fügen Sie Variablen und Tools hinzu.
- Führen Sie den Agenten aus oder wechseln Sie zur Registerkarte Evaluate und fügen Sie einen Datensatz zur Auswertung hinzu.
- Wenn Sie mit dem Prompt oder Agenten zufrieden sind, wählen Sie in der Symbolleiste Save as New Version aus.
- Geben Sie optional einen Versionsnamen ein und drücken Sie Enter.
Versionsverlauf anzeigen
Sie können den Versionsverlauf eines Prompts oder Agenten im Agent Builder anzeigen. Der Versionsverlauf zeigt alle Versionen zusammen mit den Auswertungsergebnissen für jede Version.
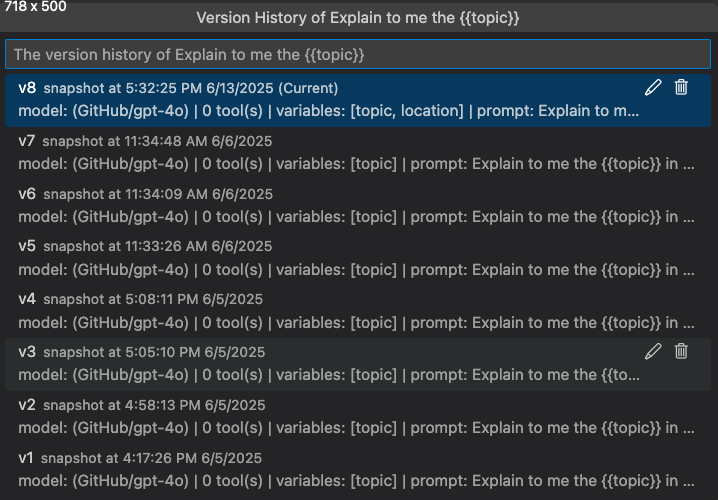
In der Versionsverlaufansicht können Sie
- Wählen Sie das Stiftsymbol neben dem Versionsnamen, um eine Version umzubenennen.
- Wählen Sie das Papierkorbsymbol, um eine Version zu löschen.
- Wählen Sie einen Versionsnamen aus, um zu dieser Version zu wechseln.
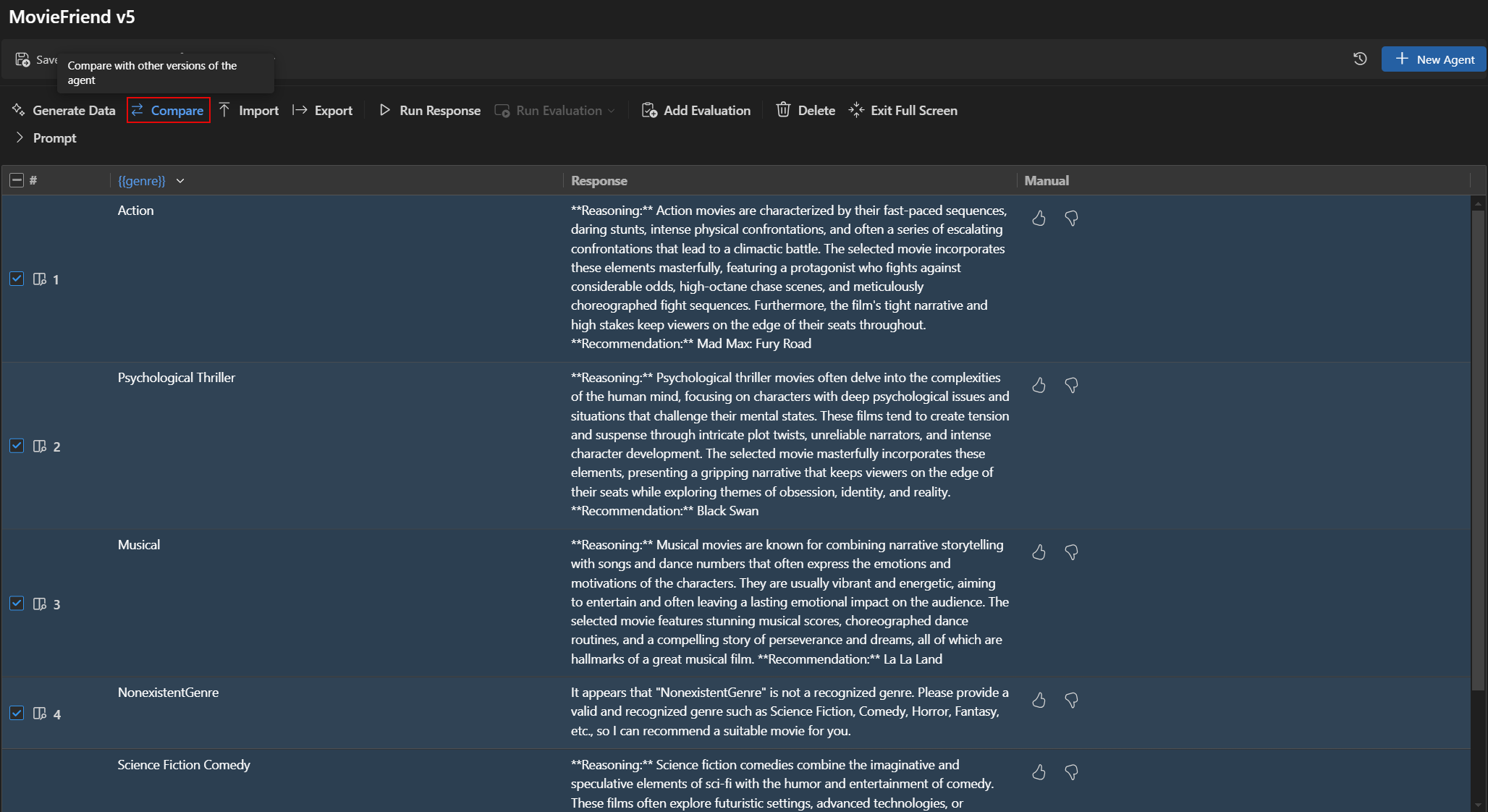
Auswertungsergebnisse zwischen Versionen vergleichen
Sie können Auswertungsergebnisse verschiedener Versionen im Agent Builder vergleichen. Die Ergebnisse werden in einer Tabelle angezeigt, die die Punktzahlen für jeden Auswerter und die Gesamtpunktzahl für jede Version zeigt.
Um Auswertungsergebnisse zwischen Versionen zu vergleichen
- Wählen Sie im Agent Builder die Registerkarte Evaluation aus.
- Wählen Sie in der Auswertungssymbolleiste Compare aus.
- Wählen Sie aus der Liste die Version aus, mit der Sie vergleichen möchten.Hinweis
Die Vergleichsfunktion ist nur im Vollbildmodus des Agent Builders verfügbar, um die Auswertungsergebnisse besser sichtbar zu machen. Sie können den Abschnitt Prompt erweitern, um die Modell- und Promptdetails anzuzeigen.
- Die Auswertungsergebnisse für die ausgewählte Version werden in einer Tabelle angezeigt, die es Ihnen ermöglicht, die Punktzahlen für jeden Auswerter und die Gesamtpunktzahl für jede Version zu vergleichen.
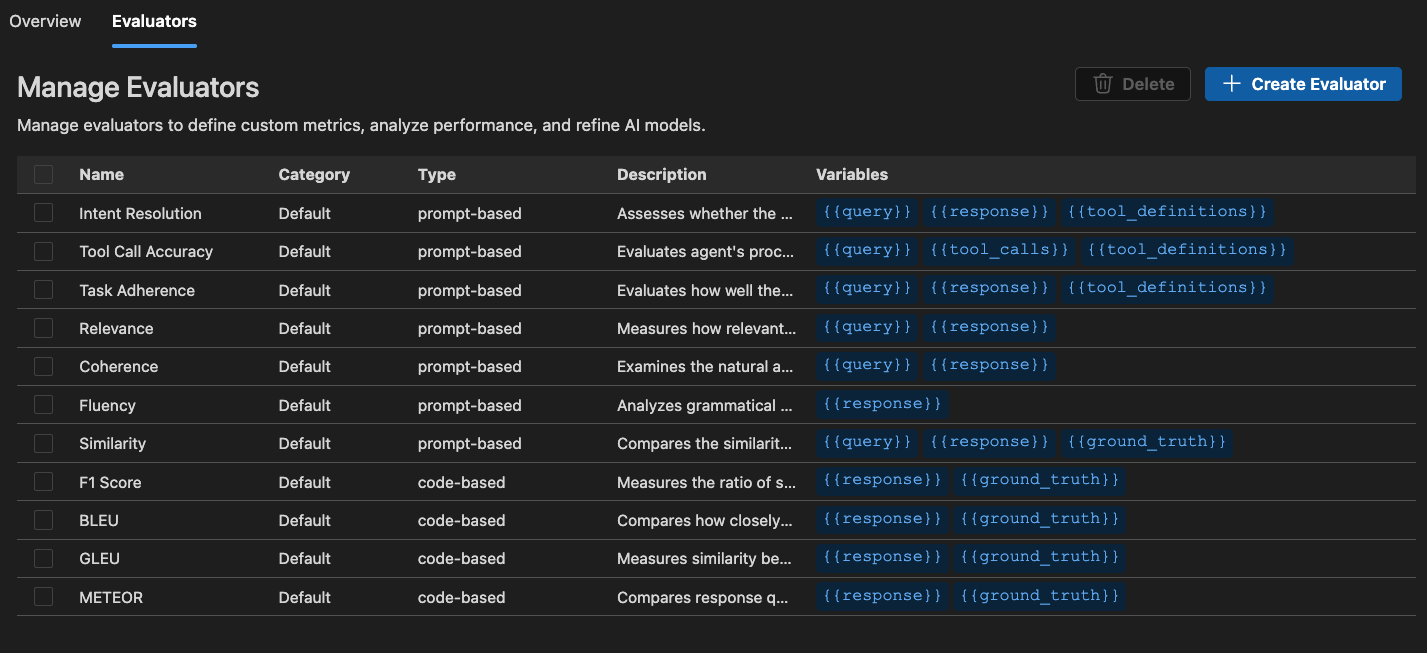
Integrierte Auswerter
Das AI Toolkit bietet eine Reihe von integrierten Auswertern zur Messung der Leistung Ihrer Modelle, Prompts und Agenten. Diese Auswerter berechnen verschiedene Metriken basierend auf Ihren Modellausgaben und Ground-Truth-Daten.
Für Agenten
- Intent Resolution: Misst, wie genau der Agent Benutzerabsichten identifiziert und adressiert.
- Task Adherence: Misst, wie gut der Agent identifizierte Aufgaben ausführt.
- Tool Call Accuracy: Misst, wie gut der Agent die richtigen Tools auswählt und aufruft.
Für allgemeine Zwecke
- Kohärenz: Misst die logische Konsistenz und den Fluss von Antworten.
- Flüssigkeit: Misst die Qualität und Lesbarkeit natürlicher Sprache.
Für RAG (Retrieval Augmented Generation)
- Retrieval: Misst, wie effektiv das System relevante Informationen abruft.
Für textuelle Ähnlichkeit
- Ähnlichkeit: KI-gestützte Messung der textuellen Ähnlichkeit.
- F1-Score: Harmonisches Mittel aus Präzision und Recall bei Token-Überlappungen zwischen Antwort und Ground Truth.
- BLEU: Bilingual Evaluation Understudy-Score für die Übersetzungsqualität; misst Überlappungen von N-Grammen zwischen Antwort und Ground Truth.
- GLEU: Google-BLEU-Variante für die Bewertung auf Satzebene; misst Überlappungen von N-Grammen zwischen Antwort und Ground Truth.
- METEOR: Metric for Evaluation of Translation with Explicit Ordering; misst Überlappungen von N-Grammen zwischen Antwort und Ground Truth.
Die Auswerter im AI Toolkit basieren auf dem Azure Evaluation SDK. Um mehr über Beobachtbarkeit für generative KI-Modelle zu erfahren, siehe die Microsoft Foundry-Dokumentation.
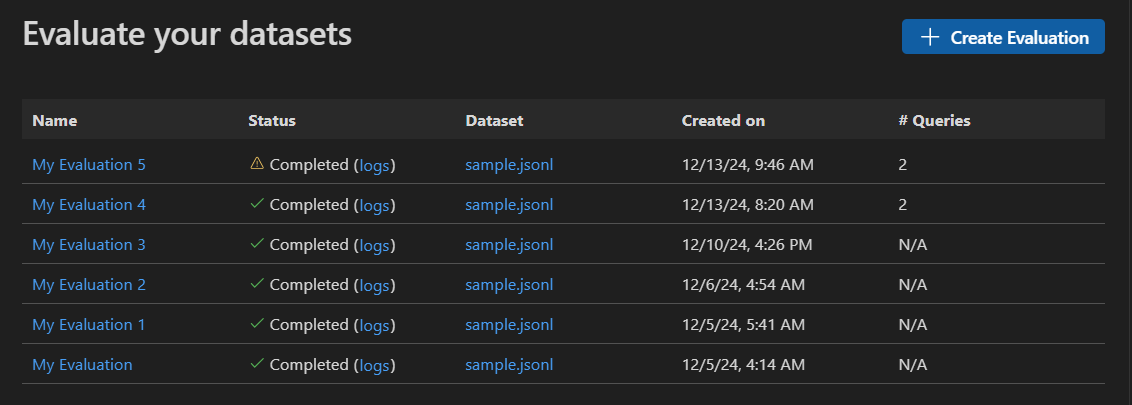
Einen eigenständigen Auswertungsjob starten
-
Wählen Sie in der AI Toolkit-Ansicht TOOLS > Evaluation aus, um die Auswertungsansicht zu öffnen.
-
Wählen Sie Create Evaluation aus und geben Sie dann folgende Informationen ein
- Evaluationsjobname: Verwenden Sie den Standardnamen oder geben Sie einen benutzerdefinierten Namen ein.
- Auswerter: Wählen Sie aus integrierten oder benutzerdefinierten Auswertern.
- Bewertungsmodell: Wählen Sie ein Modell als Bewertungsmodell aus, falls erforderlich.
- Datensatz: Wählen Sie einen Beispiel-Datensatz zum Lernen aus oder importieren Sie eine JSONL-Datei mit den Feldern
query,responseundground truth.
-
Ein neuer Auswertungsjob wird erstellt. Sie werden aufgefordert, die Details des Auswertungsjobs zu öffnen.
-
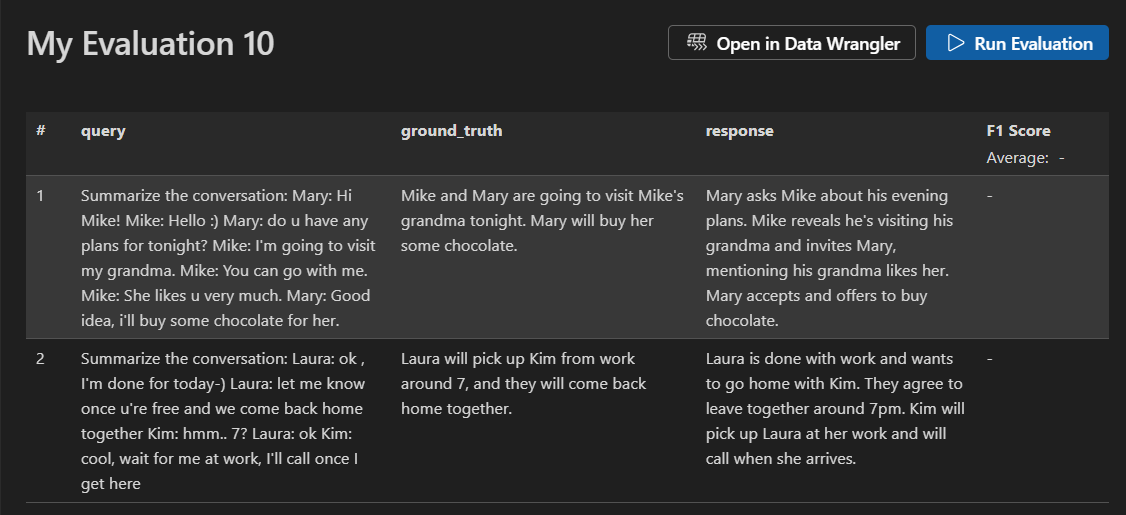
Überprüfen Sie Ihren Datensatz und wählen Sie Run Evaluation aus, um die Auswertung zu starten.
Auswertungsjob überwachen
Nachdem Sie einen Auswertungsjob gestartet haben, können Sie dessen Status in der Ansicht des Auswertungsjobs anzeigen.

Jeder Auswertungsjob enthält einen Link zum verwendeten Datensatz, Protokolle aus dem Auswertungsprozess, einen Zeitstempel und einen Link zu den Auswertungsdetails.
Ergebnisse der Auswertung finden
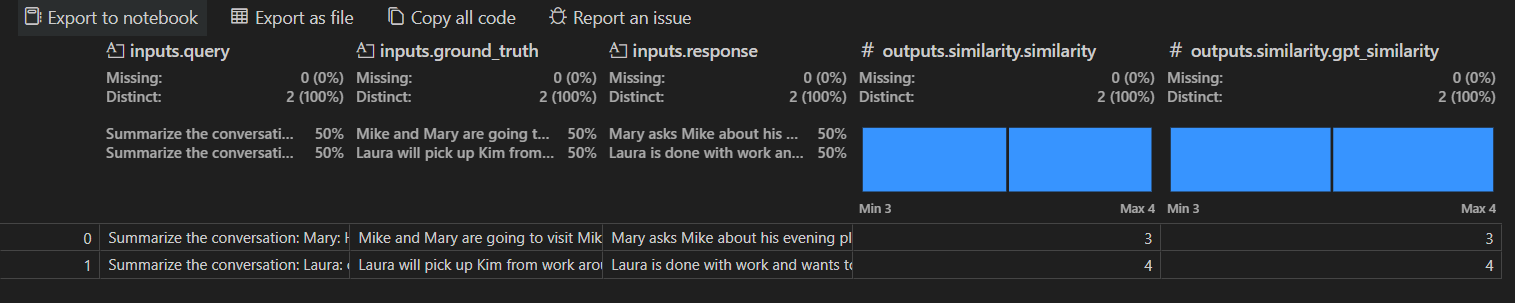
Die Ansicht der Auswertungsjobdetails zeigt eine Tabelle mit Ergebnissen für jeden ausgewählten Auswerter. Einige Ergebnisse können aggregierte Werte enthalten.
Sie können auch Open In Data Wrangler auswählen, um die Daten mit der Data Wrangler-Erweiterung zu öffnen.
Benutzerdefinierte Auswerter erstellen
Sie können benutzerdefinierte Auswerter erstellen, um die integrierten Auswertungsfunktionen des AI Toolkits zu erweitern. Benutzerdefinierte Auswerter ermöglichen es Ihnen, Ihre eigene Auswertungslogik und Metriken zu definieren.
Um einen benutzerdefinierten Auswerter zu erstellen
-
Wählen Sie in der Ansicht Evaluation die Registerkarte Evaluators aus.
-
Wählen Sie Create Evaluator aus, um das Erstellungsformular zu öffnen.
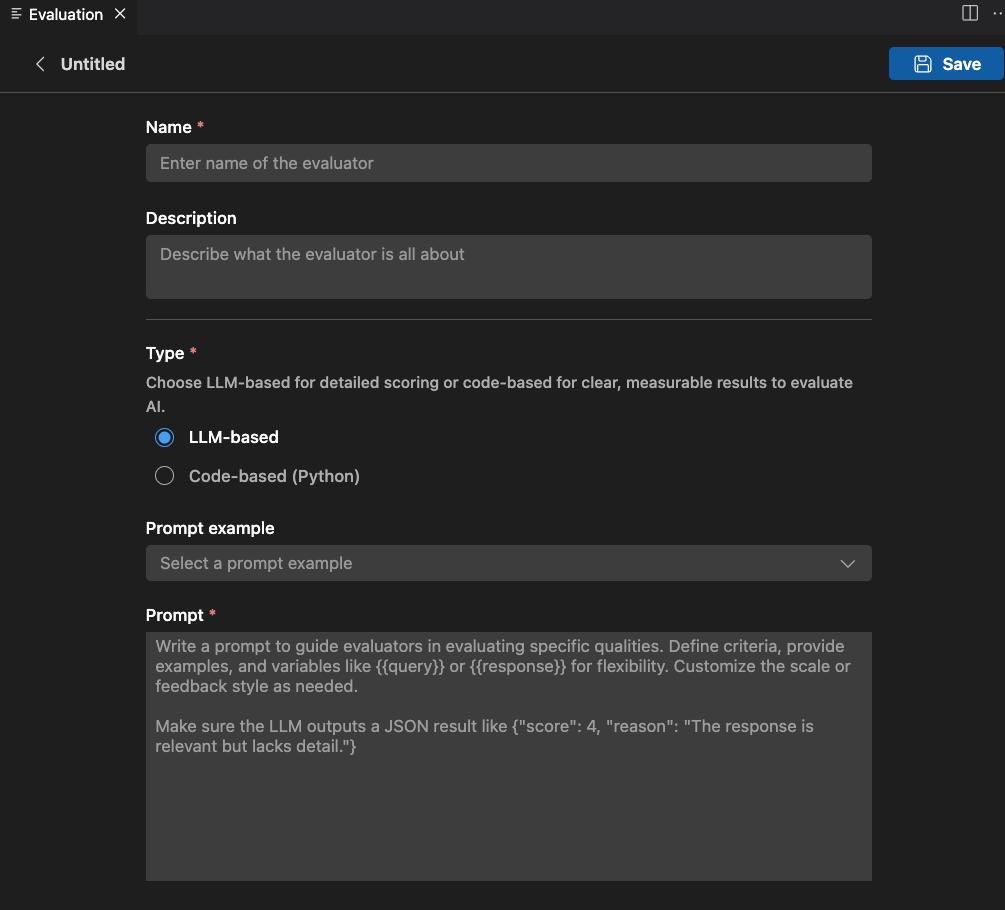
-
Erforderliche Informationen angeben
- Name: Geben Sie einen Namen für Ihren benutzerdefinierten Auswerter ein.
- Beschreibung: Beschreiben Sie, was der Auswerter tut.
- Typ: Wählen Sie den Typ des Auswerters: LLM-basiert oder Code-basiert (Python).
-
Befolgen Sie die Anweisungen für den ausgewählten Typ, um die Einrichtung abzuschließen.
-
Wählen Sie Save aus, um den benutzerdefinierten Auswerter zu erstellen.
-
Nachdem Sie den benutzerdefinierten Auswerter erstellt haben, erscheint er in der Liste der Auswerter zur Auswahl, wenn Sie einen neuen Auswertungsjob erstellen.
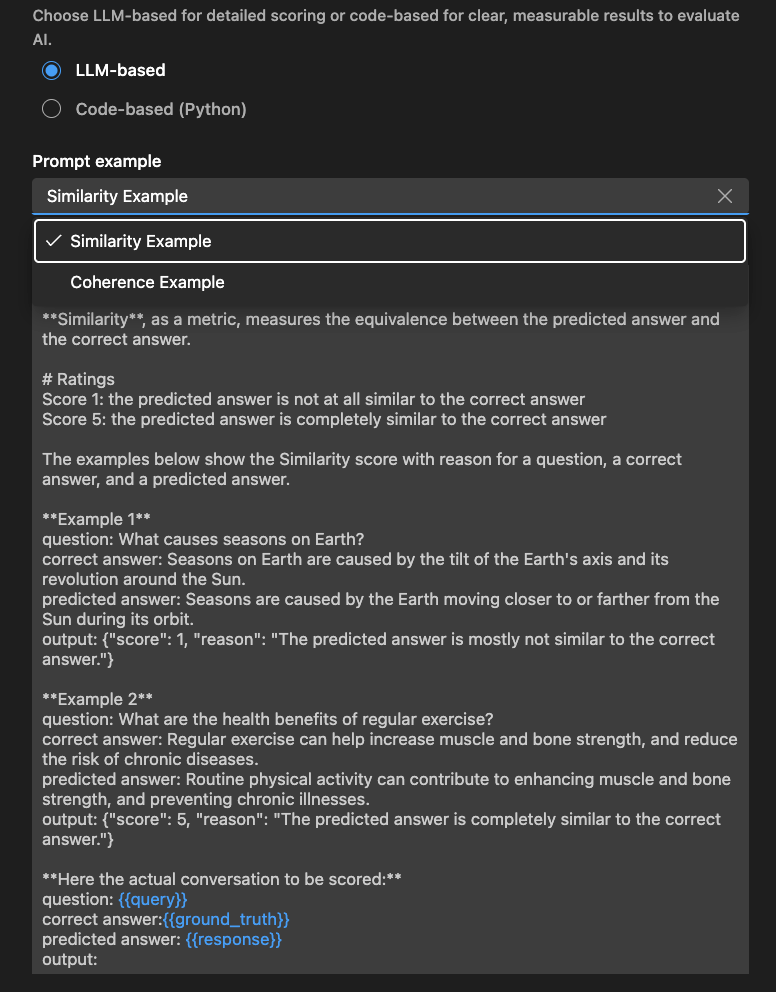
LLM-basierter Auswerter
Definieren Sie für LLM-basierte Auswerter die Auswertungslogik mithilfe eines natürlichsprachlichen Prompts.
Schreiben Sie einen Prompt, um den Auswerter bei der Bewertung spezifischer Qualitäten anzuleiten. Definieren Sie Kriterien, geben Sie Beispiele an und verwenden Sie Variablen wie oder für Flexibilität. Passen Sie die Skala oder den Feedbackstil nach Bedarf an.
Stellen Sie sicher, dass die LLM ein JSON-Ergebnis ausgibt, z. B.: {"score": 4, "reason": "The response is relevant but lacks detail."}
Sie können auch den Abschnitt Examples verwenden, um mit Ihrem LLM-basierten Auswerter zu beginnen.
Code-basierter Auswerter
Definieren Sie für code-basierte Auswerter die Auswertungslogik mit Python-Code. Der Code sollte ein JSON-Ergebnis mit der Auswertungsbewertung und dem Grund zurückgeben.
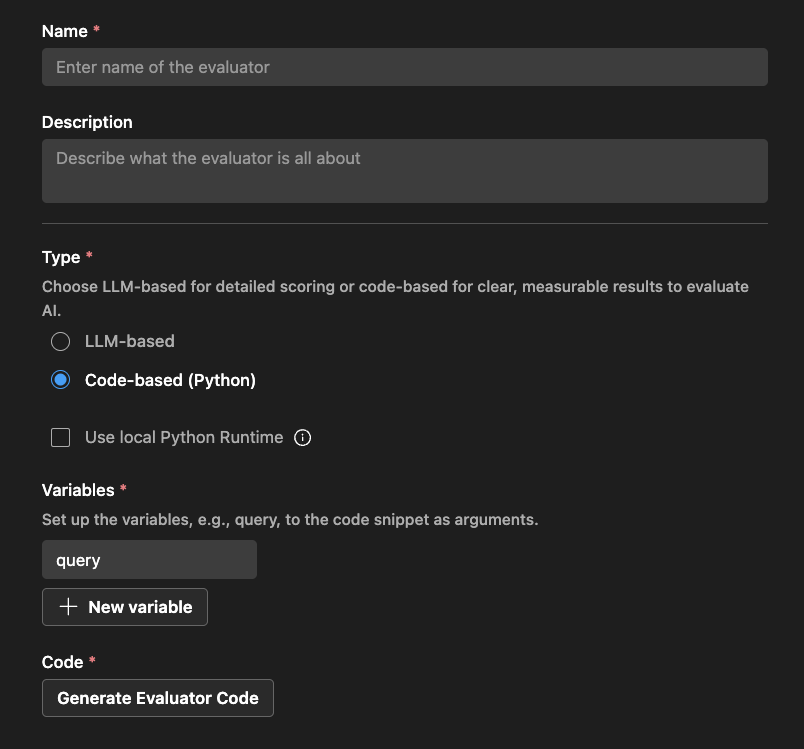
Das AI Toolkit stellt ein Gerüst basierend auf Ihrem Auswerternamen und der Verwendung einer externen Bibliothek bereit.
Sie können den Code ändern, um Ihre Auswertungslogik zu implementieren
# The method signature is generated automatically. Do not change it.
# Create a new evaluator if you want to change the method signature or arguments.
def measure_the_response_if_human_like_or_not(query, **kwargs):
# Add your evaluator logic to calculate the score.
# Return an object with score and an optional string message to display in the result.
return {
"score": 3,
"reason": "This is a placeholder for the evaluator's reason."
}
Was Sie gelernt haben
In diesem Artikel haben Sie gelernt, wie Sie
- Erstellen und führen Sie Auswertungsjobs im AI Toolkit für VS Code aus.
- Überwachen Sie den Status von Auswertungsjobs und sehen Sie sich deren Ergebnisse an.
- Vergleichen Sie Auswertungsergebnisse zwischen verschiedenen Versionen von Prompts und Agenten.
- Zeigen Sie den Versionsverlauf für Prompts und Agenten an.
- Verwenden Sie integrierte Auswerter, um die Leistung mit verschiedenen Metriken zu messen.
- Erstellen Sie benutzerdefinierte Auswerter, um die integrierten Auswertungsfunktionen zu erweitern.
- Verwenden Sie LLM-basierte und code-basierte Auswerter für verschiedene Auswertszenarien.