LoRA-Feinabstimmung für Phi Silica
Sie können Low Rank Adaptation (LoRA) verwenden, um das Phi Silica-Modell feinabzustimmen und seine Leistung für Ihren spezifischen Anwendungsfall zu verbessern. Durch die Verwendung von LoRA zur Optimierung von Phi Silica, dem lokalen Sprachmodell von Microsoft Windows, können Sie genauere Ergebnisse erzielen. Dieser Prozess umfasst das Trainieren eines LoRA-Adapters und dessen anschließende Anwendung während der Inferenz zur Verbesserung der Modellgenauigkeit.
Phi Silica-Funktionen sind in China nicht verfügbar.
Voraussetzungen
- Sie haben einen Anwendungsfall identifiziert, um die Antwort von Phi Silica zu verbessern.
- Sie haben ein Bewertungskriterium ausgewählt, um zu entscheiden, was eine "gute Antwort" ist.
- Sie haben die Phi Silica-APIs ausprobiert und sie erfüllen Ihr Bewertungskriterium nicht.
Trainieren Sie Ihren Adapter
Um einen LoRA-Adapter für die Feinabstimmung des Phi Silica-Modells mit Windows 11 zu trainieren, müssen Sie zuerst einen Datensatz generieren, den der Trainingsprozess verwendet.
Datensatz für die Verwendung mit einem LoRA-Adapter generieren
Um einen Datensatz zu generieren, müssen Sie die Daten in zwei Dateien aufteilen
train.json: wird zum Trainieren des Adapters verwendet.test.json: wird zur Bewertung der Leistung des Adapters während und nach dem Training verwendet.
Beide Dateien müssen im JSON-Format vorliegen, wobei jede Zeile ein separates JSON-Objekt darstellt, das ein einzelnes Sample repräsentiert. Jedes Sample sollte eine Liste von Nachrichten enthalten, die zwischen einem Benutzer und einem Assistenten ausgetauscht wurden.
Jedes Nachrichtenobjekt erfordert zwei Felder
content: der Text der Nachricht.role: entweder"user"oder"assistant", was den Absender angibt.
Siehe folgende Beispiele
{"messages": [{"content": "Hello, how do I reset my password?", "role": "user"}, {"content": "To reset your password, go to the settings page and click 'Reset Password'.", "role": "assistant"}]}
{"messages": [{"content": "Can you help me find nearby restaurants?", "role": "user"}, {"content": "Sure! Here are some restaurants near your location: ...", "role": "assistant"}]}
{"messages": [{"content": "What is the weather like today?", "role": "user"}, {"content": "Today's forecast is sunny with a high of 25°C.", "role": "assistant"}]}
Trainings-Tipps
- Am Ende jeder Sample-Zeile ist kein Komma erforderlich.
- Fügen Sie so viele hochwertige und vielfältige Beispiele wie möglich ein. Für beste Ergebnisse sammeln Sie mindestens ein paar Tausend Trainings-Samples in Ihrer
train.json-Datei. - Die Datei
test.jsonkann kleiner sein, sollte aber die Arten von Interaktionen abdecken, die Ihr Modell voraussichtlich handhaben wird. - Erstellen Sie
train.json- undtest.json-Dateien mit jeweils einem JSON-Objekt pro Zeile, die jeweils ein kurzes Hin und Her-Gespräch zwischen einem Benutzer und einem Assistenten enthalten. Die Qualität und Menge Ihrer Daten wirken sich stark auf die Effektivität Ihres LoRA-Adapters aus.
Trainieren eines LoRA-Adapters
Um einen LoRA-Adapter zu trainieren, benötigen Sie die folgenden erforderlichen Voraussetzungen
- Azure-Abonnement mit verfügbarem Kontingent in Azure Container Apps.
- Wir empfehlen die Verwendung von A100-GPUs oder besser, um einen Feinabstimmungsauftrag effizient auszuführen.
- Prüfen Sie, ob Sie verfügbares Kontingent im Azure-Portal haben. Wenn Sie Hilfe bei der Suche nach Ihrem Kontingent benötigen, siehe Kontingente anzeigen.
Befolgen Sie diese Schritte, um einen Arbeitsbereich zu erstellen und einen Feinabstimmungsauftrag zu starten
-
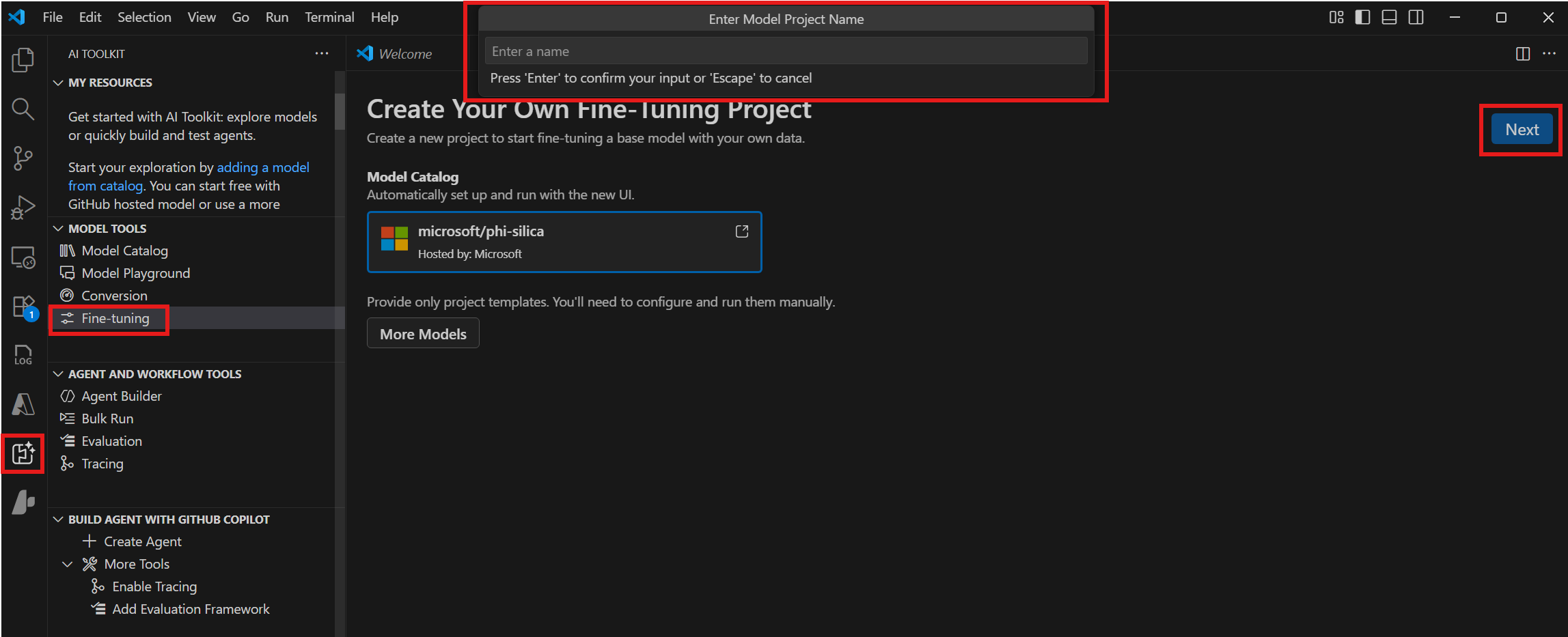
Navigieren Sie zu Model Tools > Fine-tuning und wählen Sie New Project.
-
Wählen Sie "microsoft/phi-silica" aus dem Model Catalog und wählen Sie Next.
-
Wählen Sie im Dialogfenster einen Projektordner und geben Sie einen Projektnamen ein. Ein neues VS Code-Fenster wird für das Projekt geöffnet.
-
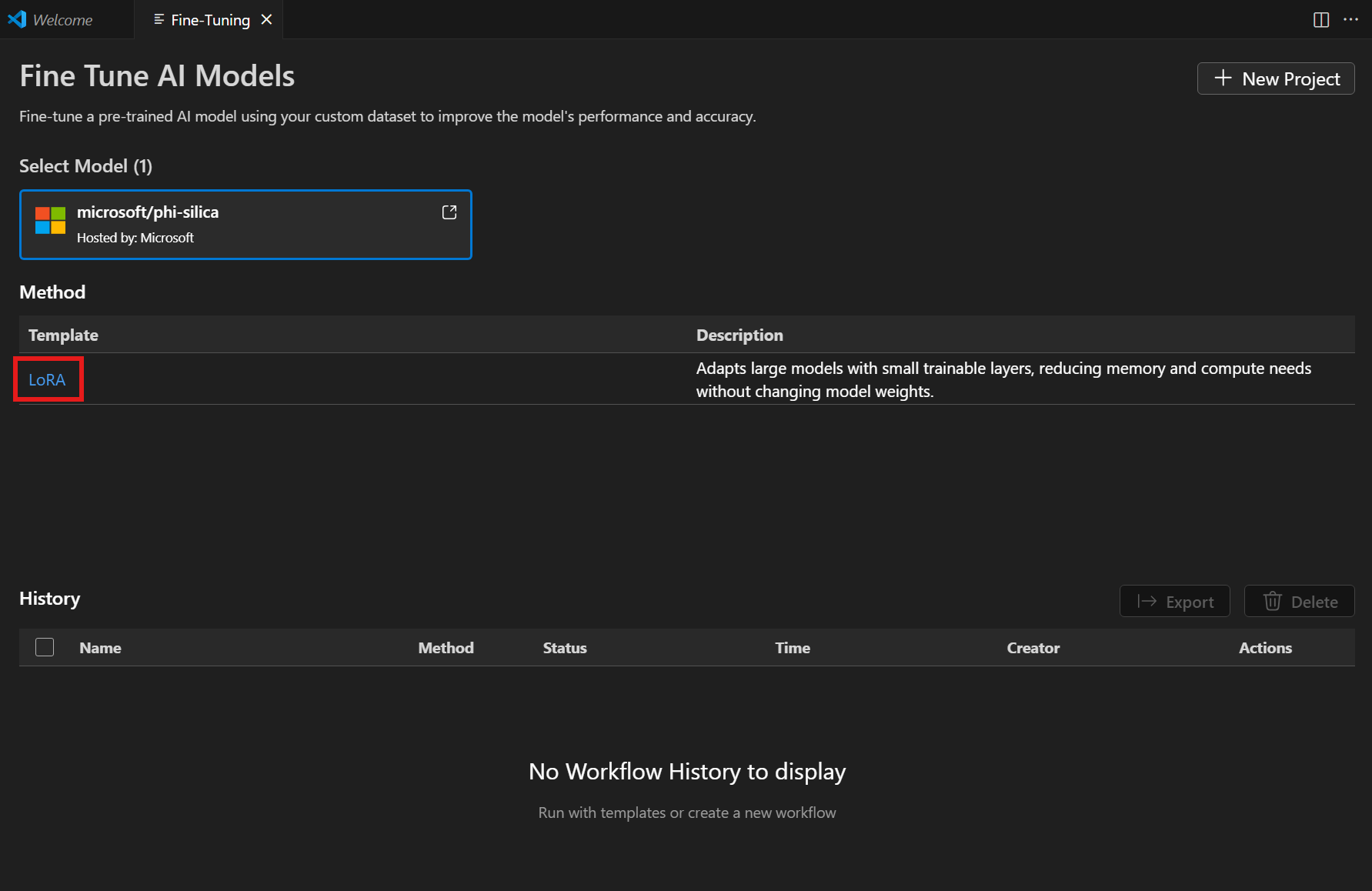
Wählen Sie "LoRA" aus der Liste Method.
-
Unter Data > Training Dataset name und Test Dataset name wählen Sie Ihre Dateien
train.jsonundtest.jsonaus. -
Wählen Sie Run with Cloud.
-
Wählen Sie im Dialogfenster das Microsoft-Konto aus, mit dem Sie auf Ihr Azure-Abonnement zugreifen möchten.
-
Sobald Ihr Konto ausgewählt ist, wählen Sie eine Ressourcengruppe aus dem Abonnement-Dropdownmenü.
-
Beachten Sie, dass Ihr Feinabstimmungsauftrag erfolgreich gestartet wird und einen Auftragsstatus anzeigt.
Verwenden Sie die Schaltfläche Refresh, um den Status manuell zu aktualisieren. Ein Feinabstimmungsauftrag dauert im Durchschnitt etwa 45 bis 60 Minuten.
-
Sobald der Auftrag abgeschlossen ist, haben Sie die Möglichkeit, den neu trainierten LoRA-Adapter herunterzuladen, indem Sie auf Download klicken, und Show Metrics auswählen, um die Feinabstimmungsmetriken zu überprüfen.

Empfehlungen zur LoRA-Feinabstimmung
Auswahl von Hyperparametern
Die Standardhyperparameter für die LoRA-Feinabstimmung sollten eine vernünftige Basis-Feinabstimmung zum Vergleichen liefern. Wir haben unser Bestes getan, um Standardwerte zu finden, die für die meisten Anwendungsfälle und Datensätze gut funktionieren.
Wir haben jedoch die Flexibilität belassen, Parameter nach Belieben zu durchsuchen.
Trainings-Hyperparameter
Unser Standard-Parameter-Suchraum wäre
| Parametername | Min | Max | Verteilung |
|---|---|---|---|
| learning_rate | 1e-4 | 1e-2 | Log-uniform |
| weight_decay | 1e-5 | 1e-1 | Log-uniform |
| adam_beta1 | 0.9 | 0.99 | Uniform |
| adam_beta2 | 0.9 | 0.999 | Uniform |
| adam_epsilon | 1e-9 | 1e-6 | Log-uniform |
| num_warmup_steps | 0 | 10000 | Uniform |
| lora_dropout | 0 | 0.5 | Uniform |
Wir durchsuchen auch den Lernraten-Scheduler und wählen entweder linear_with_warmup oder cosine_with_warmup. Wenn der Parameter num_warmup_steps auf 0 gesetzt ist, können Sie die Optionen linear oder kosinus-förmig äquivalent verwenden.
Die Lernrate, der Lernraten-Scheduler und die Anzahl der Aufwärmschritte interagieren miteinander. Wenn Sie zwei Werte fixieren und den dritten variieren, erhalten Sie bessere Einblicke, wie sie die Ergebnisse des Trainings auf Ihrem Datensatz verändern.
Die Parameter weight_decay und lora_dropout dienen dazu, Überanpassung zu kontrollieren. Wenn Sie feststellen, dass Ihr Adapter schlecht von Ihrem Trainingsdatensatz auf Ihren Evaluationsdatensatz generalisiert, versuchen Sie, die Werte dieser Parameter zu erhöhen.
Die adam_ parameters beeinflussen, wie der Adam-Optimizer während der Trainingsschritte funktioniert. Für weitere Informationen zu diesem Optimizer siehe zum Beispiel die PyTorch-Dokumentation.
Viele der anderen bereitgestellten Parameter sind analog zu ihren gleichnamigen Gegenstücken in der PEFT-Bibliothek. Für weitere Informationen dazu siehe die Transformer-Dokumentation.
Daten-Hyperparameter
Die Daten-Hyperparameter train_nsamples und test_nsamples steuern, wie viele Samples für das Training und die Tests verwendet werden sollen. Die Verwendung von mehr Samples aus Ihrem Trainingsdatensatz ist normalerweise eine gute Idee. Die Verwendung von mehr Test-Samples liefert weniger verrauschte Testmetriken, aber jeder Evaluationslauf dauert länger.
Die Parameter train_batch_size und test_batch_size steuern, wie viele Samples pro Batch für das Training bzw. Testen verwendet werden sollen. Sie können normalerweise mehr Batches für Tests als für das Training verwenden, da die Ausführung eines Testbeispiels weniger GPU-Speicher benötigt als ein Trainingsbeispiel.
Die Parameter train_seqlen und test_seqlen steuern die Länge der Trainings- und Testsequenzen. Im Allgemeinen gilt: je länger, desto besser, bis Sie die Grenzen des GPU-Speichers erreichen. Die Standardwerte sollten eine gute Balance bieten.
Auswahl eines System-Prompts
Die Strategie, die sich bei der Auswahl eines System-Prompts für das Training als gut erwiesen hat, besteht darin, ihn recht einfach zu halten (1 oder 2 Sätze), während das Modell gleichzeitig dazu ermutigt wird, Ausgaben im gewünschten Format zu erzeugen. Wir haben auch festgestellt, dass die Verwendung eines etwas anderen System-Prompts für Training und Inferenz die Ergebnisse verbessern kann.
Je stärker sich Ihre gewünschte Ausgabe von der Basisversion des Modells unterscheidet, desto mehr kann Ihnen ein System-Prompt helfen.
Wenn Sie zum Beispiel nur eine geringfügige Stiländerung am Basismodell trainieren, wie z. B. die Verwendung vereinfachter Sprache, um jüngere Leser anzusprechen, benötigen Sie möglicherweise gar keinen System-Prompt.
Wenn Ihre gewünschte Ausgabe jedoch eine strukturiertere Form hat, sollten Sie den System-Prompt verwenden, um das Modell teilweise dorthin zu bringen. Wenn Sie also eine JSON-Tabelle mit bestimmten Schlüsseln benötigen, könnte der erste Satz Ihres System-Prompts beschreiben, wie eine Modellantwort aussehen sollte, wenn sie in Klartext erfolgt. Der zweite Satz könnte dann genauer das Format der JSON-Tabelle angeben. Die Verwendung des ersten Satzes beim Training und dann beider Sätze bei der Inferenz könnte Ihnen die gewünschten Ergebnisse liefern.
Parameter
Die Liste aller Parameter, die feinabgestimmt werden können, ist hier angehängt. Wenn ein Parameter nicht in der Benutzeroberfläche der Workflow-Seite angezeigt wird, fügen Sie ihn manuell zu <your_project_path>/<model_name>/lora/lora.yaml hinzu.
[
################## Basic config settings ##################
{
"groupId": "data",
"fields": [
{
"name": "system_prompt",
"type": "Optional",
"defaultValue": null,
"info": "Optional system prompt. If specified, the system prompt given here will be prepended to each example in the dataset as the system prompt when training the LoRA adapter. When running inference the same (or a very similar) system prompt should be used. Note: if a system prompt is specified in the training data, giving a system prompt here will overwrite the system prompt in the dataset.",
"label": "System prompt"
},
{
"name": "varied_seqlen",
"type": "bool",
"defaultValue": false,
"info": "Varied sequence lengths in the calibration data. If False (default), training examples will be concatenated together until they are finetune_[train/test]_seqlen tokens long. This makes memory usage more consistent and predictable. If True, each individual example will be truncated to finetune_[train/test]_seqlen tokens. This can sometimes give better training performance, but also gives unpredictable memory usage. It can cause `out of memory` errors mid training, if there are long training examples in your dataset.",
"label": "Allow varied sequence length in data"
},
{
"name": "finetune_dataset",
"type": "str",
"defaultValue": "wikitext2",
"info": "Dataset to finetune on.",
"label": "Dataset name or path"
},
{
"name": "finetune_train_nsamples",
"type": "int",
"defaultValue": 4096,
"info": "Number of samples to load from the train set for finetuning.",
"label": "Number of finetuning samples"
},
{
"name": "finetune_test_nsamples",
"type": "int",
"defaultValue": 128,
"info": "Number of samples to load from the test set for finetuning.",
"label": "Number of test samples"
},
{
"name": "finetune_train_batch_size",
"type": "int",
"defaultValue": 4,
"info": "Batch size for finetuning training.",
"label": "Training batch size"
},
{
"name": "finetune_test_batch_size",
"type": "int",
"defaultValue": 8,
"info": "Batch size for finetuning testing.",
"label": "Test batch size"
},
{
"name": "finetune_train_seqlen",
"type": "int",
"defaultValue": 2048,
"info": "Maximum sequence length for finetuning training. Longer sequences will be truncated.",
"label": "Max training sequence length"
},
{
"name": "finetune_test_seqlen",
"type": "int",
"defaultValue": 2048,
"info": "Maximum sequence length for finetuning testing. Longer sequences will be truncated.",
"label": "Max test sequence length"
}
]
},
{
"groupId": "finetuning",
"fields": [
{
"name": "early_stopping_patience",
"type": "int",
"defaultValue": 5,
"info": "Number of evaluations with no improvement after which training will be stopped.",
"label": "Early stopping patience"
},
{
"name": "epochs",
"type": "float",
"defaultValue": 1,
"info": "Number of total epochs to run.",
"label": "Epochs"
},
{
"name": "eval_steps",
"type": "int",
"defaultValue": 64,
"info": "Number of training steps to perform before each evaluation.",
"label": "Steps between evaluations"
},
{
"name": "save_steps",
"type": "int",
"defaultValue": 64,
"info": "Number of steps after which to save model checkpoint. This _must_ be a multiple of the number of steps between evaluations.",
"label": "Steps between checkpoints"
},
{
"name": "learning_rate",
"type": "float",
"defaultValue": 0.0002,
"info": "Learning rate for training.",
"label": "Learning rate"
},
{
"name": "lr_scheduler_type",
"type": "str",
"defaultValue": "linear",
"info": "Type of learning rate scheduler.",
"label": "Learning rate scheduler",
"optionValues": [
"linear",
"linear_with_warmup",
"cosine",
"cosine_with_warmup"
]
},
{
"name": "num_warmup_steps",
"type": "int",
"defaultValue": 400,
"info": "Number of warmup steps for learning rate scheduler. Only relevant for a _with_warmup scheduler.",
"label": "Scheduler warmup steps (if supported)"
}
]
}
################## Advanced config settings ##################
{
"groupId": "advanced",
"fields": [
{
"name": "seed",
"type": "int",
"defaultValue": 42,
"info": "Seed for sampling the data.",
"label": "Random seed"
},
{
"name": "evaluation_strategy",
"type": "str",
"defaultValue": "steps",
"info": "Evaluation strategy to use.",
"label": "Evaluation strategy",
"optionValues": [
"steps",
"epoch",
"no"
]
},
{
"name": "lora_dropout",
"type": "float",
"defaultValue": 0.1,
"info": "Dropout rate for LoRA.",
"label": "LoRA dropout"
},
{
"name": "adam_beta1",
"type": "float",
"defaultValue": 0.9,
"info": "Beta1 hyperparameter for Adam optimizer.",
"label": "Adam beta 1"
},
{
"name": "adam_beta2",
"type": "float",
"defaultValue": 0.95,
"info": "Beta2 hyperparameter for Adam optimizer.",
"label": "Adam beta 2"
},
{
"name": "adam_epsilon",
"type": "float",
"defaultValue": 1e-08,
"info": "Epsilon hyperparameter for Adam optimizer.",
"label": "Adam epsilon"
},
{
"name": "num_training_steps",
"type": "Optional",
"defaultValue": null,
"info": "The number of training steps there will be. If not set (recommended), this will be calculated internally.",
"label": "Number of training steps"
},
{
"name": "gradient_accumulation_steps",
"type": "int",
"defaultValue": 1,
"info": "Number of updates steps to accumulate before performing a backward/update pass.",
"label": "gradient accumulation steps"
},
{
"name": "eval_accumulation_steps",
"type": "Optional",
"defaultValue": null,
"info": "Number of predictions steps to accumulate before moving the tensors to the CPU.",
"label": "eval accumulation steps"
},
{
"name": "eval_delay",
"type": "Optional",
"defaultValue": 0,
"info": "Number of epochs or steps to wait for before the first evaluation can be performed, depending on the eval_strategy.",
"label": "eval delay"
},
{
"name": "weight_decay",
"type": "float",
"defaultValue": 0.0,
"info": "Weight decay for AdamW if we apply some.",
"label": "weight decay"
},
{
"name": "max_grad_norm",
"type": "float",
"defaultValue": 1.0,
"info": "Max gradient norm.",
"label": "max grad norm"
},
{
"name": "gradient_checkpointing",
"type": "bool",
"defaultValue": false,
"info": "If True, use gradient checkpointing to save memory at the expense of slower backward pass.",
"label": "gradient checkpointing"
}
]
}
]
Ändern Sie das Azure-Abonnement und die Ressourcengruppe
Wenn Sie das Azure-Abonnement und die Ressourcengruppe, die zuvor festgelegt wurden, ändern möchten, können Sie diese in der Datei <your_project_path>/model_lab.workspace.provision.config aktualisieren oder entfernen.
Inferenz mit dem Phi Silica LoRA-Adapter
Die Phi Silica APIs sind Teil einer Limited Access Feature (siehe LimitedAccessFeatures class). Für weitere Informationen oder um ein Unlock-Token anzufordern, verwenden Sie bitte das LAF Access Token Request Form.
Die Inferenz mit dem Phi Silica LoRA-Adapter wird derzeit nur auf Copilot+ PCs mit ARM-Prozessoren unterstützt.
Verwenden Sie Windows AI APIs zur Inferenz: Phi Silica mit LoRA-Adapter