Erste Schritte mit Data Wrangler in VS Code
Data Wrangler ist ein codezentriertes Werkzeug zur Anzeige und Bereinigung von Daten, das in VS Code und VS Code Jupyter Notebooks integriert ist. Es bietet eine reichhaltige Benutzeroberfläche zur Anzeige und Analyse Ihrer Daten, zeigt aufschlussreiche Spaltenstatistiken und Visualisierungen an und generiert automatisch Pandas-Code, während Sie die Daten bereinigen und transformieren.
Im Folgenden finden Sie ein Beispiel dafür, wie Sie Data Wrangler aus dem Notebook öffnen, um die Daten mit den integrierten Operationen zu analysieren und zu bereinigen. Anschließend wird der automatisch generierte Code zurück in das Notebook exportiert.
Dieses Dokument behandelt, wie Sie
- Data Wrangler installieren und einrichten
- Data Wrangler aus einem Notebook starten
- Data Wrangler aus einer Datendatei starten
- Data Wrangler zur Erkundung Ihrer Daten verwenden
- Data Wrangler zur Durchführung von Operationen und Bereinigungen an Ihren Daten verwenden
- Den Data Wrangling-Code bearbeiten und in ein Notebook exportieren
- Fehlerbehebung und Feedback geben
Richten Sie Ihre Umgebung ein
- Wenn Sie dies noch nicht getan haben, installieren Sie Python. WICHTIG: Data Wrangler unterstützt nur Python Version 3.8 oder höher.
- Installieren Sie Visual Studio Code.
- Die Data Wrangler-Erweiterung installieren
Wenn Sie Data Wrangler zum ersten Mal starten, werden Sie gefragt, mit welchem Python-Kernel Sie sich verbinden möchten. Außerdem wird Ihr Computer und Ihre Umgebung überprüft, um festzustellen, ob die erforderlichen Python-Pakete, wie z. B. Pandas, installiert sind.
Hier ist eine Liste der erforderlichen Versionen für Python und Python-Pakete, zusammen mit der Angabe, ob sie von Data Wrangler automatisch installiert werden.
| Name | Mindestanforderung | Automatisch installiert |
|---|---|---|
| Python | 3.8 | Nein |
| pandas | 0.25.2 | Ja |
Wenn diese Abhängigkeiten in Ihrer Umgebung nicht gefunden werden, versucht Data Wrangler, sie für Sie mit pip zu installieren. Wenn Data Wrangler die Abhängigkeiten nicht installieren kann, ist die einfachste Problemumgehung, pip install manuell auszuführen und dann Data Wrangler erneut zu starten. Diese Abhängigkeiten sind für Data Wrangler erforderlich, damit es Python- und Pandas-Code generieren kann.
Data Wrangler öffnen
Sie befinden sich jederzeit in Data Wrangler in einer isolierten Umgebung, d. h. Sie können Daten sicher erkunden und transformieren. Der ursprüngliche Datensatz wird nicht geändert, bis Sie Ihre Änderungen explizit exportieren.
Data Wrangler aus einem Jupyter Notebook starten
Es gibt drei Möglichkeiten, Data Wrangler aus Ihrem Jupyter Notebook zu starten
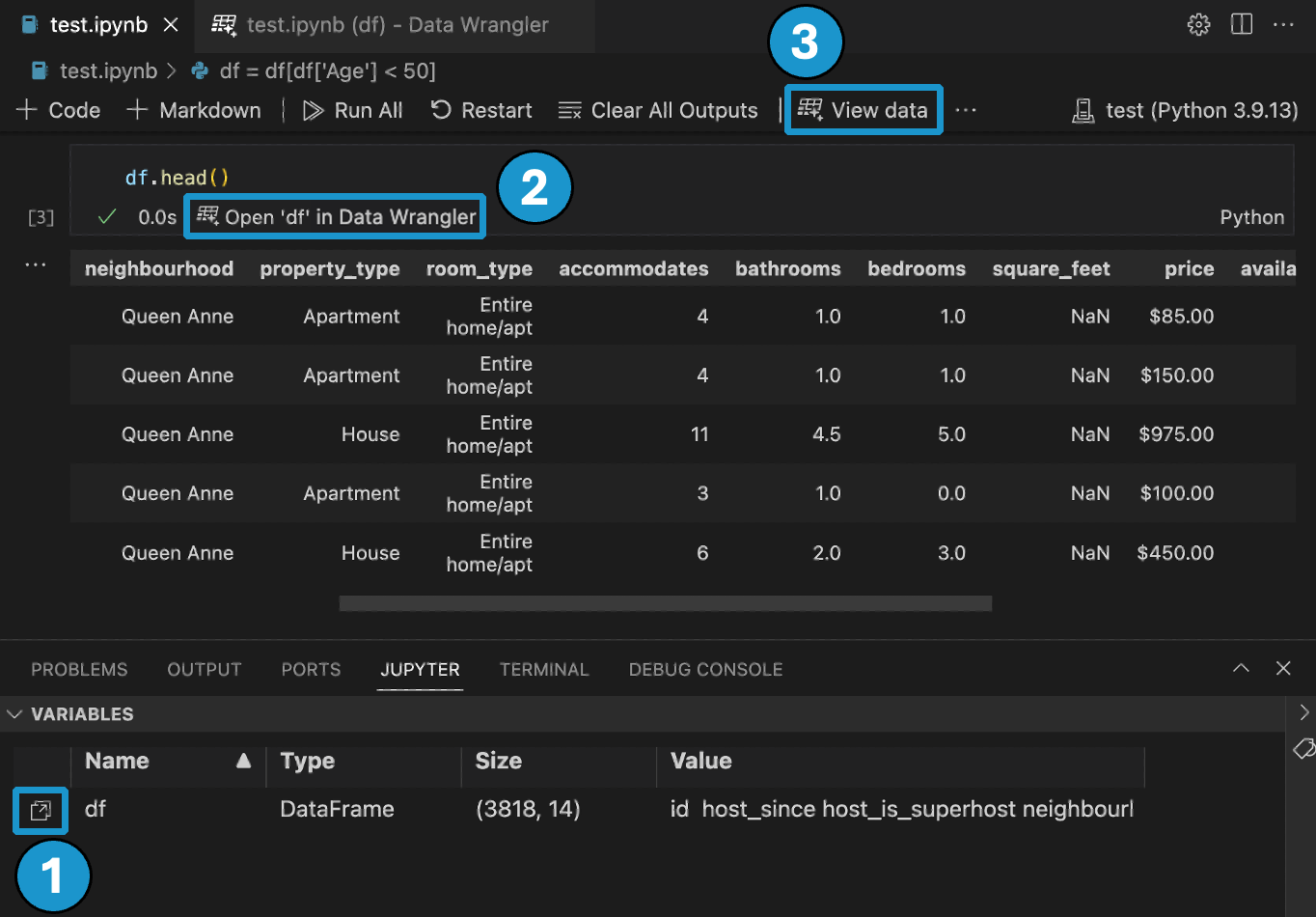
- Im Panel Jupyter > Variablen sehen Sie neben jedem unterstützten Datenobjekt eine Schaltfläche zum Starten von Data Wrangler.
- Wenn Sie einen Pandas DataFrame in Ihrem Notebook haben, sehen Sie jetzt eine Schaltfläche "df" in Data Wrangler öffnen (wobei "df" der Variablenname Ihres DataFrames ist) am Ende der Zelle, nachdem Sie Code ausgeführt haben, der den DataFrame ausgibt. Dazu gehören 1)
df.head(), 2)df.tail(), 3)display(df), 4)print(df), 5)df. - Wenn Sie in der Notebook-Symbolleiste Daten anzeigen auswählen, wird eine Liste aller unterstützten Datenobjekte in Ihrem Notebook angezeigt. Sie können dann auswählen, welche Variable in dieser Liste Sie in Data Wrangler öffnen möchten.
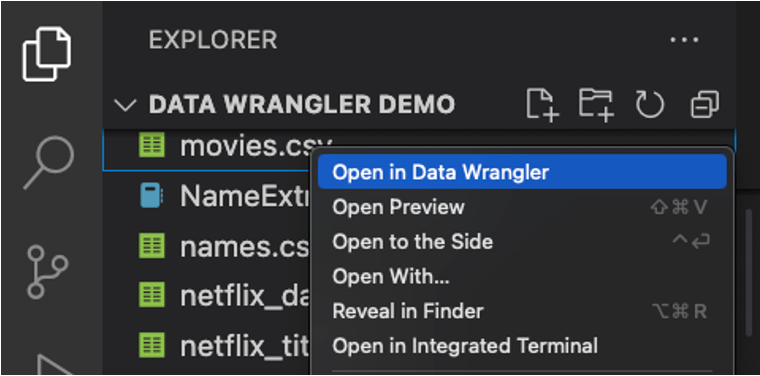
Data Wrangler direkt aus einer Datei starten
Sie können Data Wrangler auch direkt aus einer lokalen Datei (z. B. einer .csv) starten. Öffnen Sie dazu in VS Code einen beliebigen Ordner, der die gewünschte Datei enthält. Klicken Sie in der Dateiexplorer-Ansicht mit der rechten Maustaste auf die Datei und wählen Sie In Data Wrangler öffnen.
Data Wrangler unterstützt derzeit die folgenden Dateitypen
.csv/.tsv.xls/.xlsx.parquet
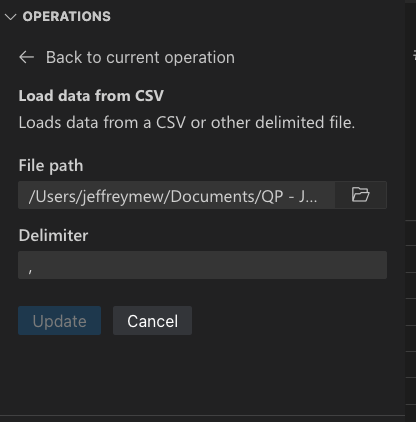
Abhängig vom Dateityp können Sie das Trennzeichen und/oder das Blatt der Datei angeben.
Sie können diese Dateitypen auch so einstellen, dass sie standardmäßig mit Data Wrangler geöffnet werden.
Benutzeroberfläche
Data Wrangler verfügt über zwei Modi bei der Arbeit mit Ihren Daten. Die Details für jeden Modus werden in den folgenden Abschnitten erläutert.
- Anzeigemodus: Der Anzeigemodus optimiert die Benutzeroberfläche, damit Sie Ihre Daten schnell anzeigen, filtern und sortieren können. Dieser Modus eignet sich hervorragend für die anfängliche Erkundung des Datensatzes.
- Bearbeitungsmodus: Der Bearbeitungsmodus optimiert die Benutzeroberfläche, damit Sie Transformationen, Bereinigungen oder Modifikationen auf Ihren Datensatz anwenden können. Während Sie diese Transformationen in der Benutzeroberfläche anwenden, generiert Data Wrangler automatisch den entsprechenden Pandas-Code, der zur Wiederverwendung zurück in Ihr Notebook exportiert werden kann.
Hinweis: Standardmäßig wird Data Wrangler im Anzeigemodus geöffnet. Sie können dieses Verhalten im Einstellungseditor ändern .

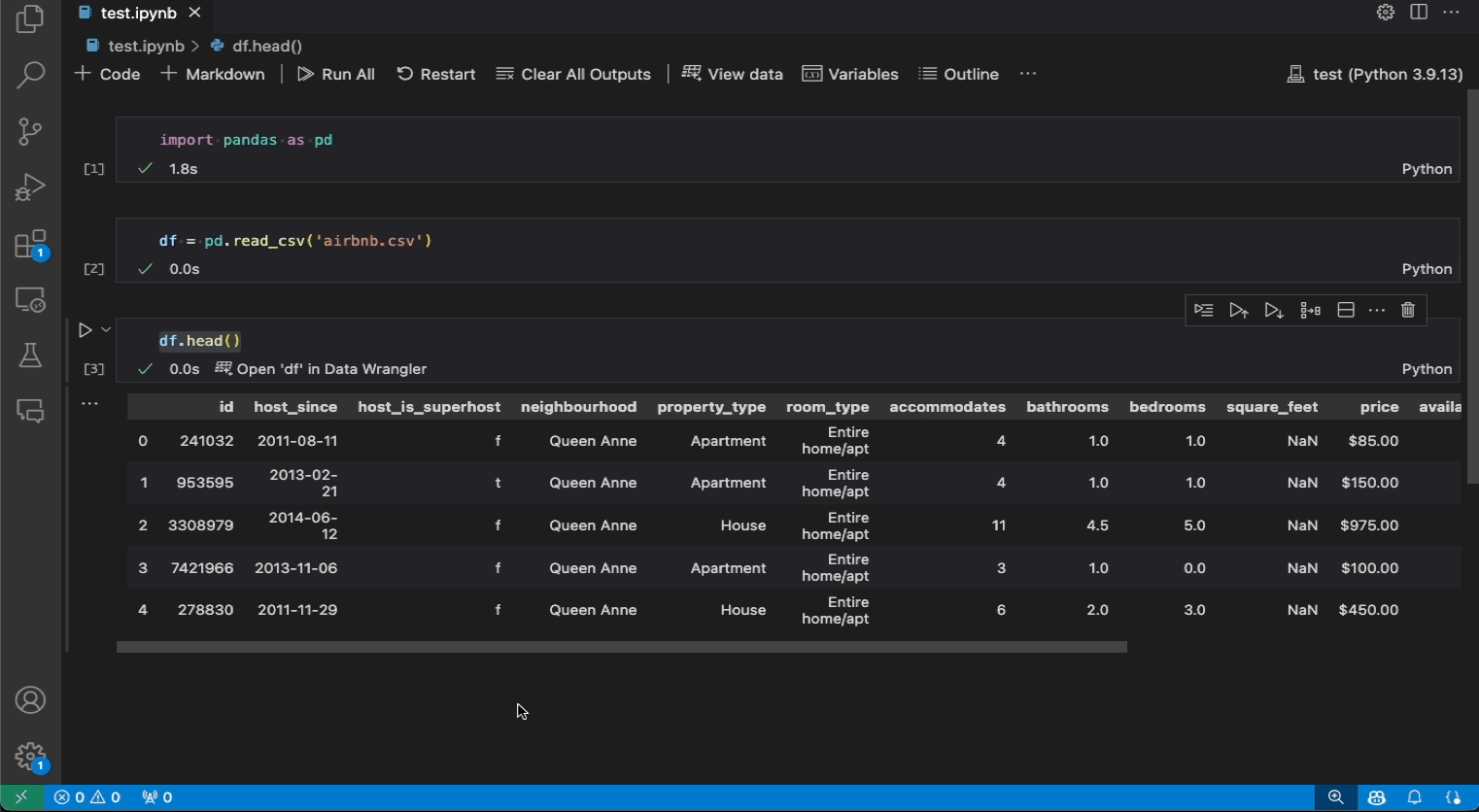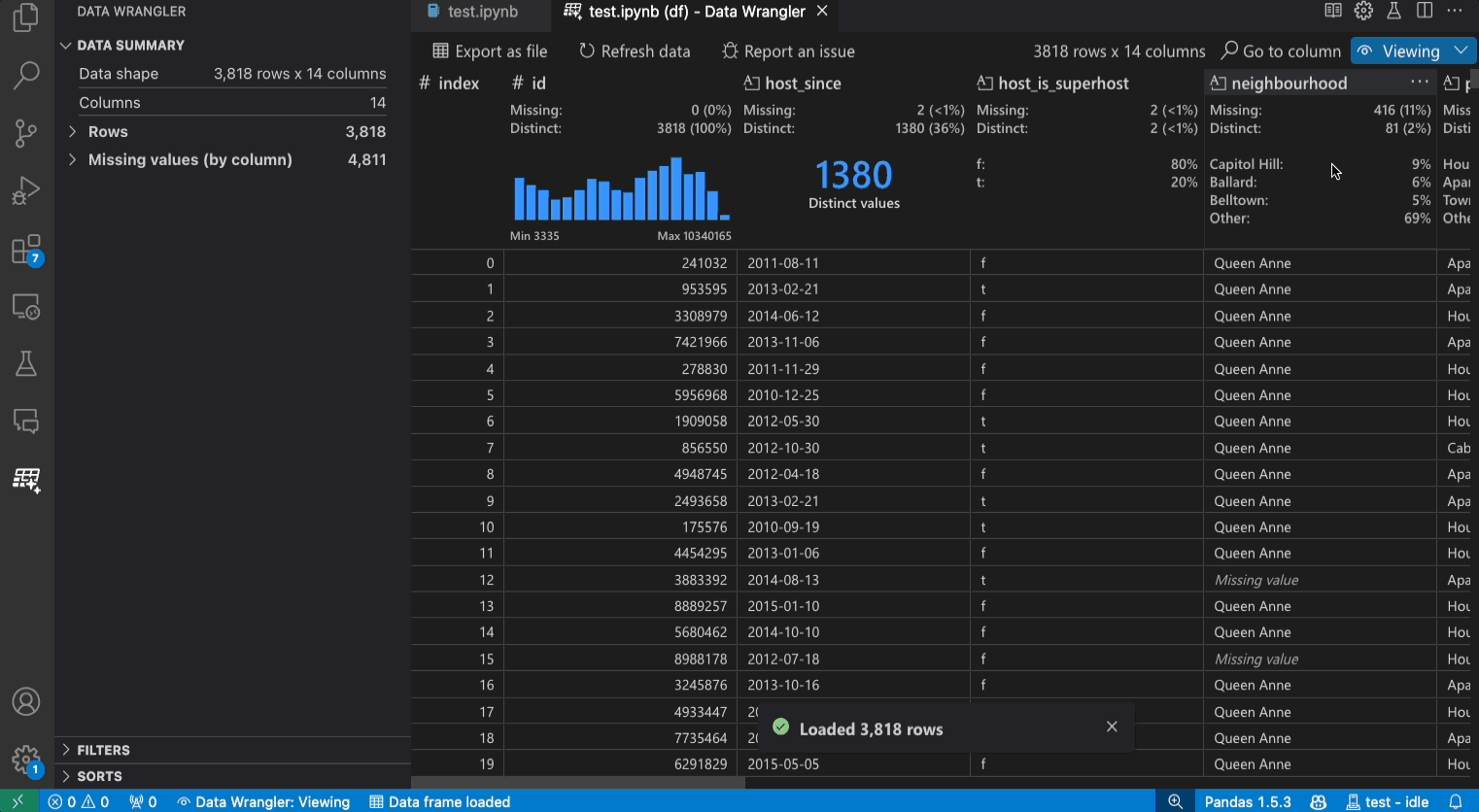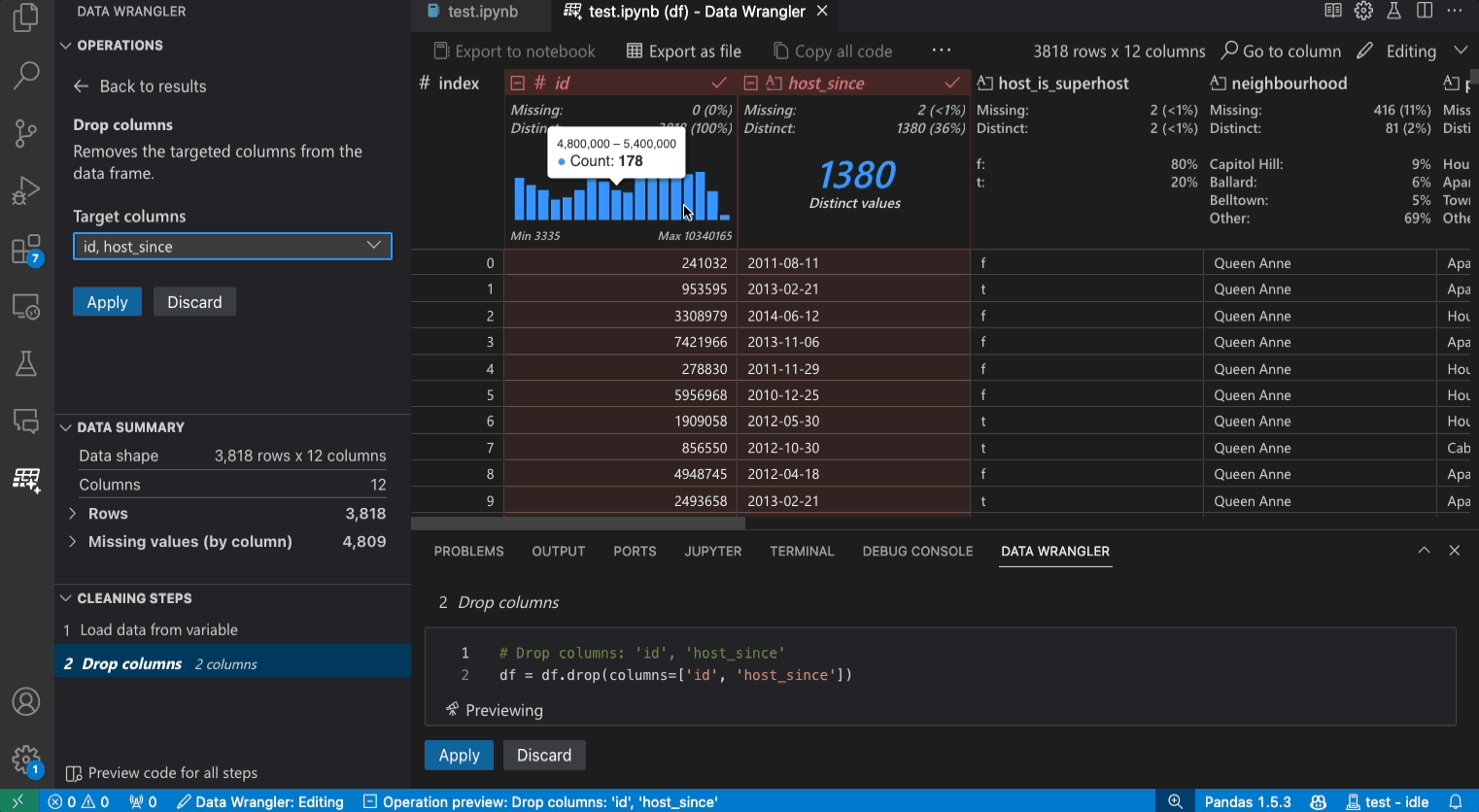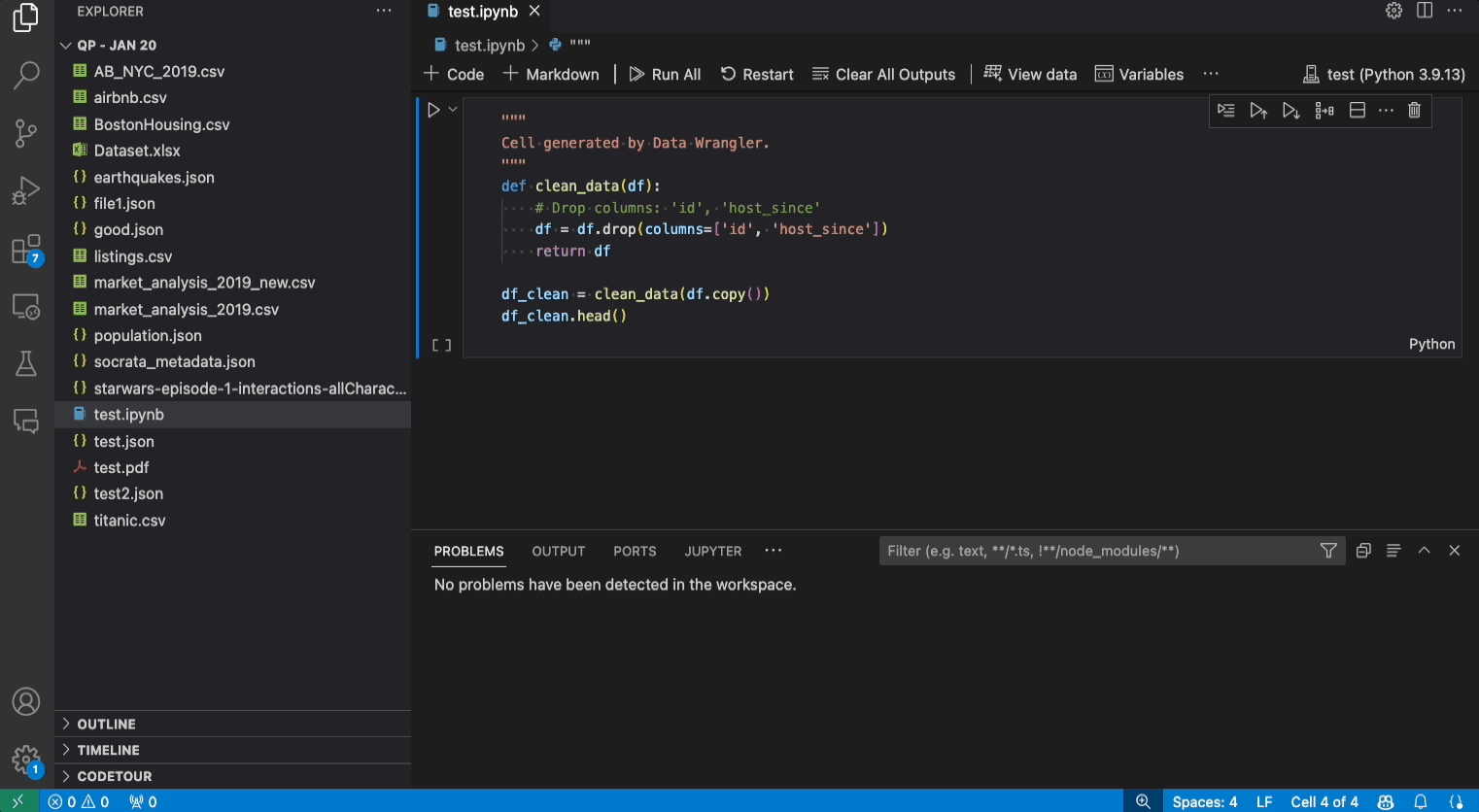
Benutzeroberfläche im Anzeigemodus
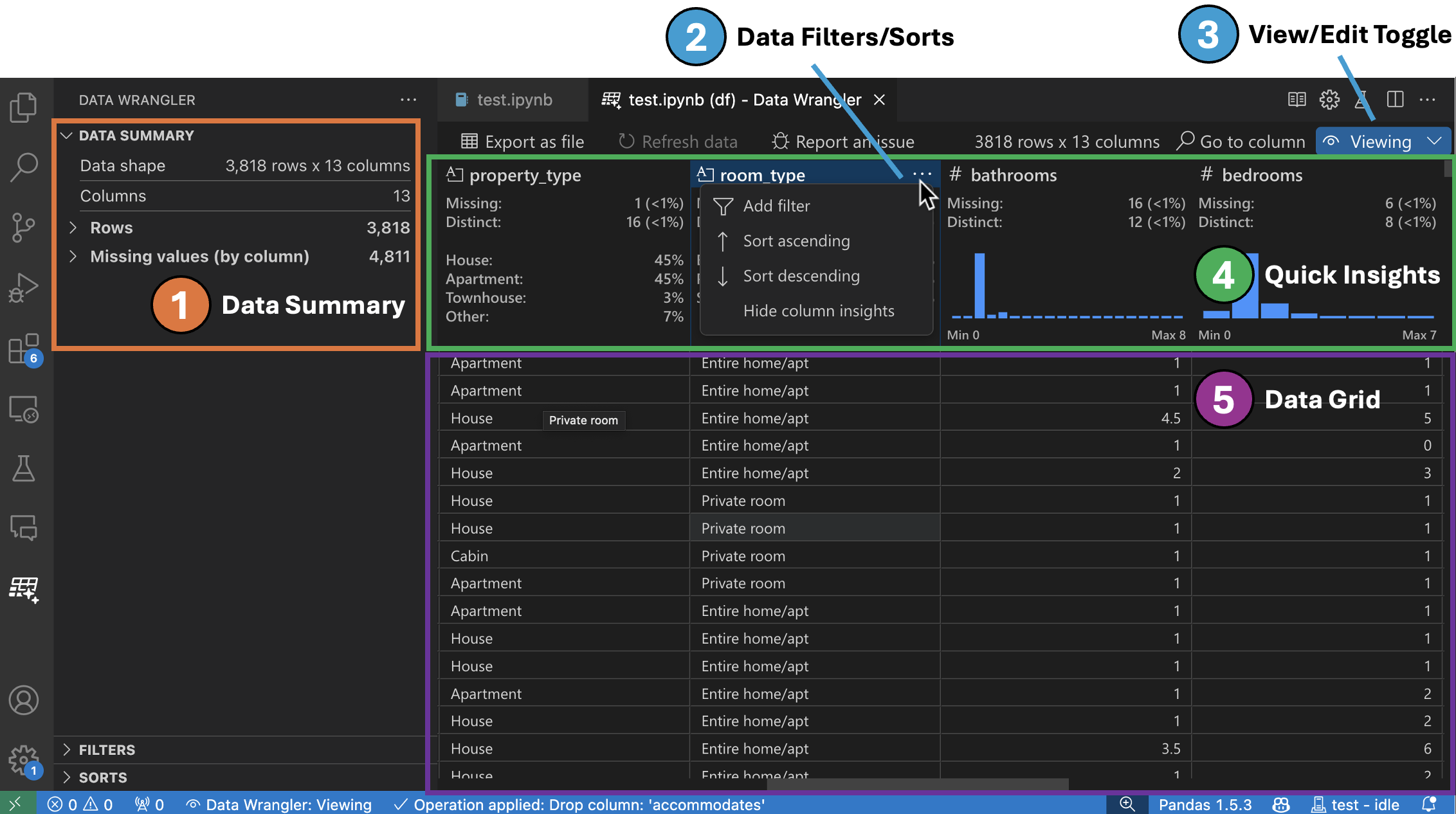
-
Das Panel Datenzusammenfassung zeigt detaillierte Zusammenfassungsstatistiken für Ihren gesamten Datensatz oder eine bestimmte Spalte an, wenn eine ausgewählt ist.
-
Sie können beliebige Datenfilter/Sortierungen auf die Spalte über das Header-Menü der Spalte anwenden.
-
Schalten Sie zwischen dem Anzeige- oder Bearbeitungsmodus von Data Wrangler um, um auf die integrierten Datenoperationen zuzugreifen.
-
Im Header Schnelle Einblicke können Sie schnell wertvolle Informationen zu jeder Spalte einsehen. Abhängig vom Datentyp der Spalte zeigen die schnellen Einblicke die Verteilung der Daten oder die Häufigkeit von Datenpunkten sowie fehlende und eindeutige Werte an.
-
Das Datenraster bietet ein scrollbares Fenster, in dem Sie Ihren gesamten Datensatz anzeigen können.
Benutzeroberfläche im Bearbeitungsmodus
Der Wechsel in den Bearbeitungsmodus aktiviert zusätzliche Funktionen und Benutzeroberflächenelemente in Data Wrangler. Im folgenden Screenshot verwenden wir Data Wrangler, um die fehlenden Werte in der letzten Spalte durch den Median dieser Spalte zu ersetzen.
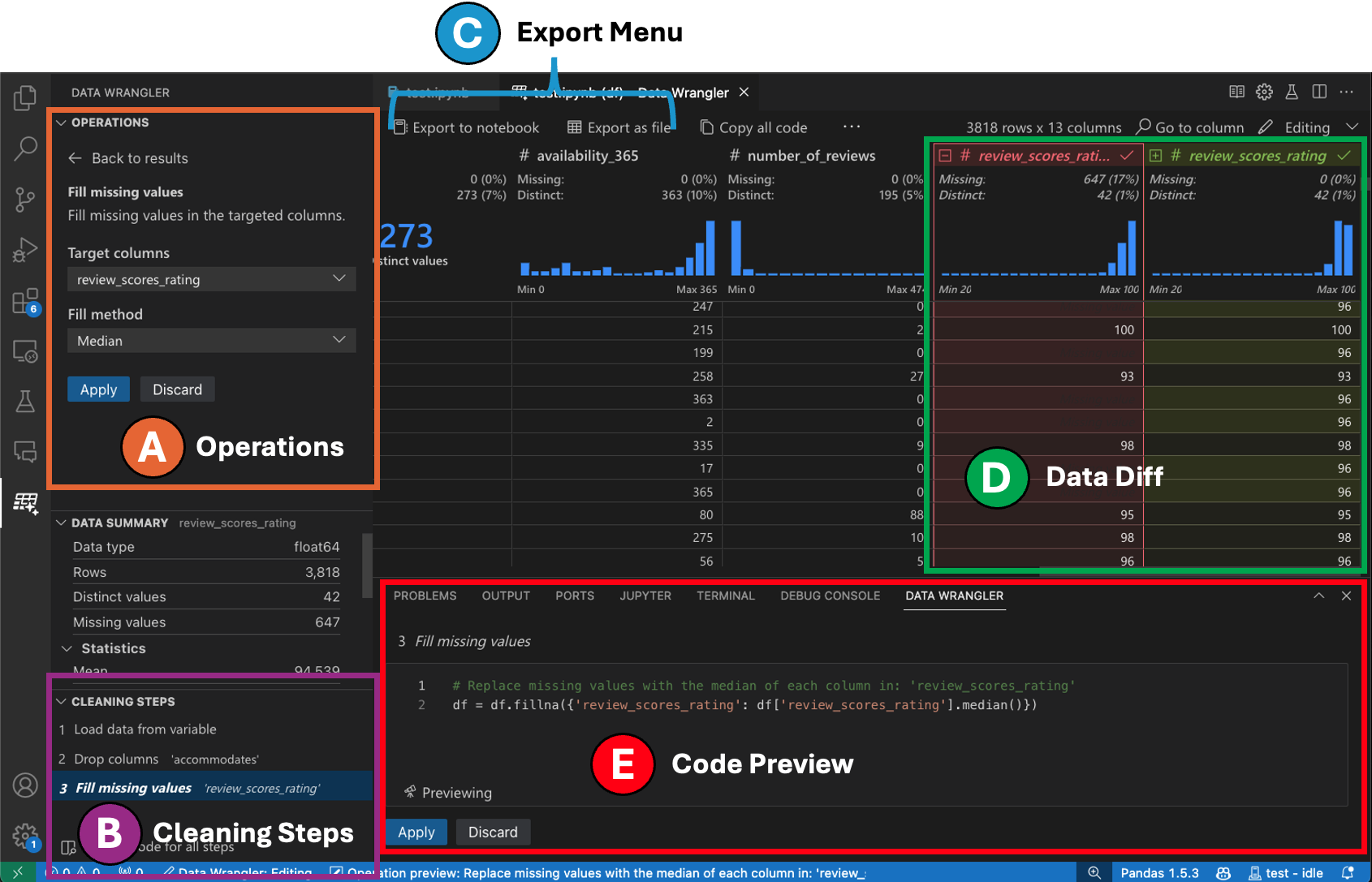
-
Im Panel Operationen können Sie alle integrierten Datenoperationen von Data Wrangler durchsuchen. Die Operationen sind nach Kategorien organisiert.
-
Das Panel Bereinigungsschritte zeigt eine Liste aller zuvor angewendeten Operationen an. Es ermöglicht dem Benutzer, bestimmte Operationen rückgängig zu machen oder die letzte Operation zu bearbeiten. Die Auswahl eines Schritts hebt die Änderungen in der Data-Diff-Ansicht hervor und zeigt den zugehörigen generierten Code an.
-
Das Exportmenü ermöglicht den Export des Codes zurück in ein Jupyter Notebook oder den Export der Daten in eine neue Datei.
-
Wenn Sie eine Operation ausgewählt haben und deren Auswirkungen auf die Daten vorschauen, wird das Raster mit einer Data-Diff-Ansicht der von Ihnen vorgenommenen Änderungen überlagert.
-
Der Abschnitt Code-Vorschau zeigt den Python- und Pandas-Code an, den Data Wrangler beim Auswählen einer Operation generiert hat. Er bleibt leer, wenn keine Operation ausgewählt ist. Sie können den generierten Code bearbeiten, was dazu führt, dass das Datenraster die Auswirkungen auf die Daten hervorhebt.
Data Wrangler-Operationen
Die integrierten Data Wrangler-Operationen können aus dem Panel Operation ausgewählt werden.
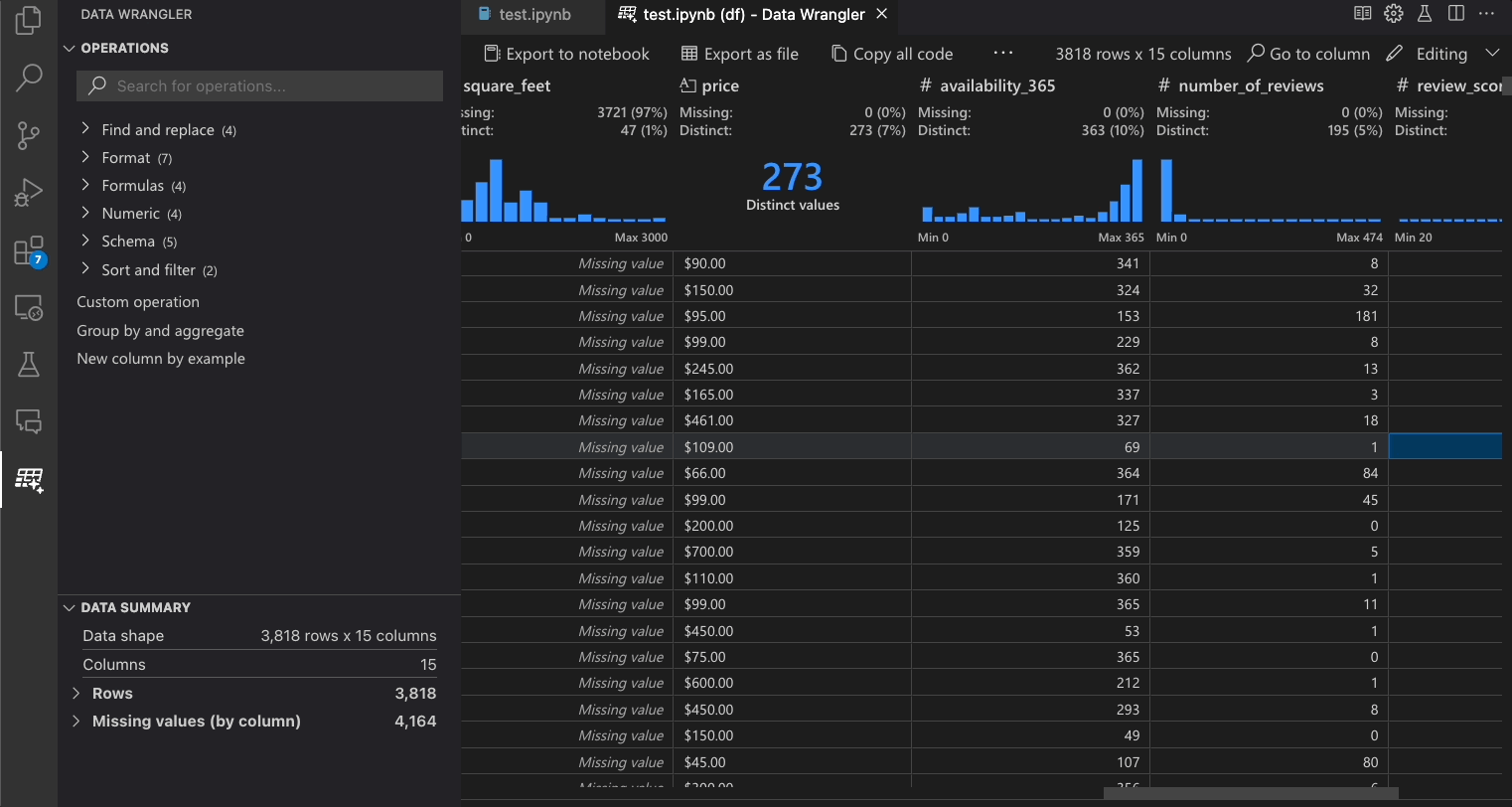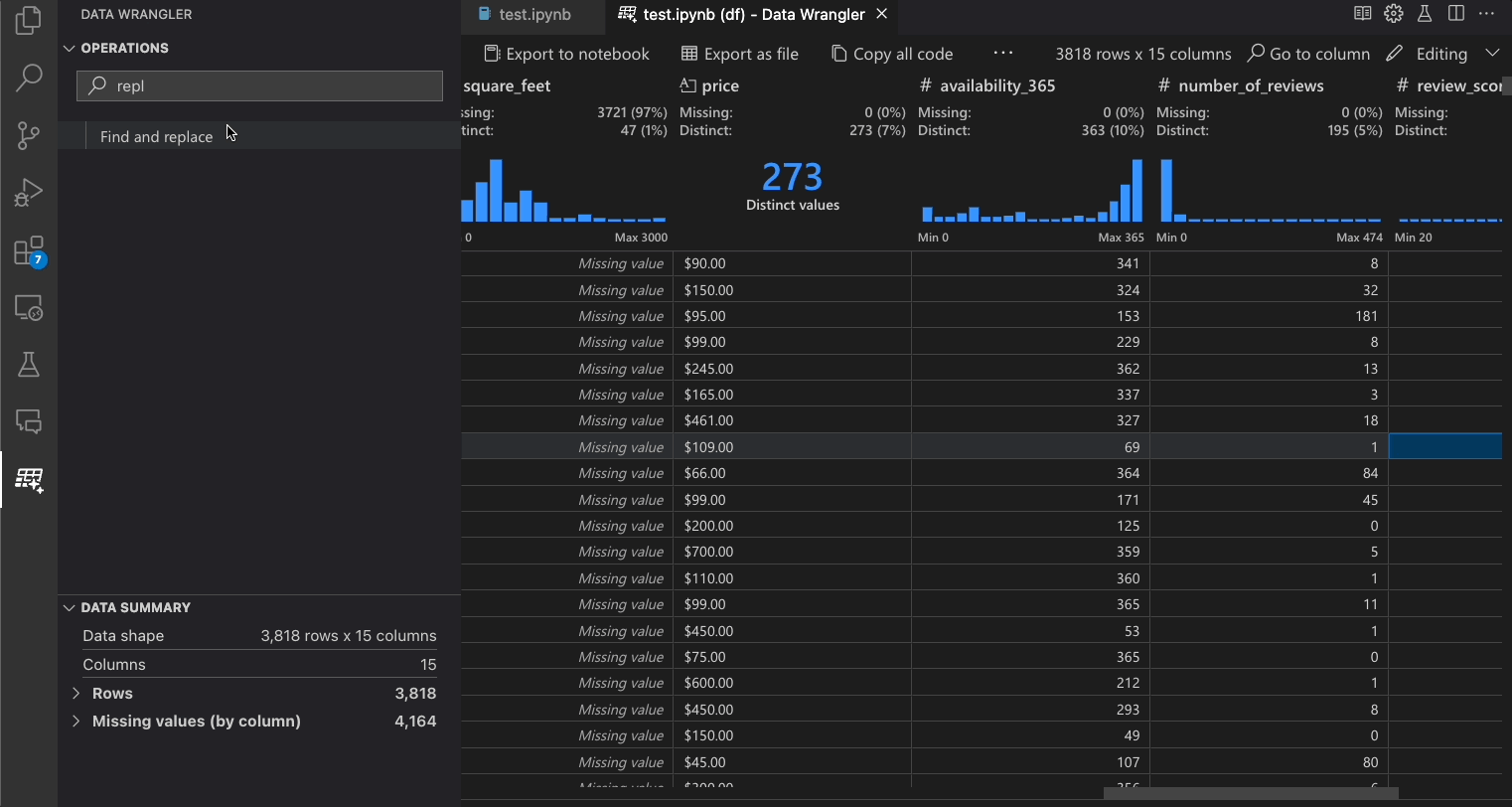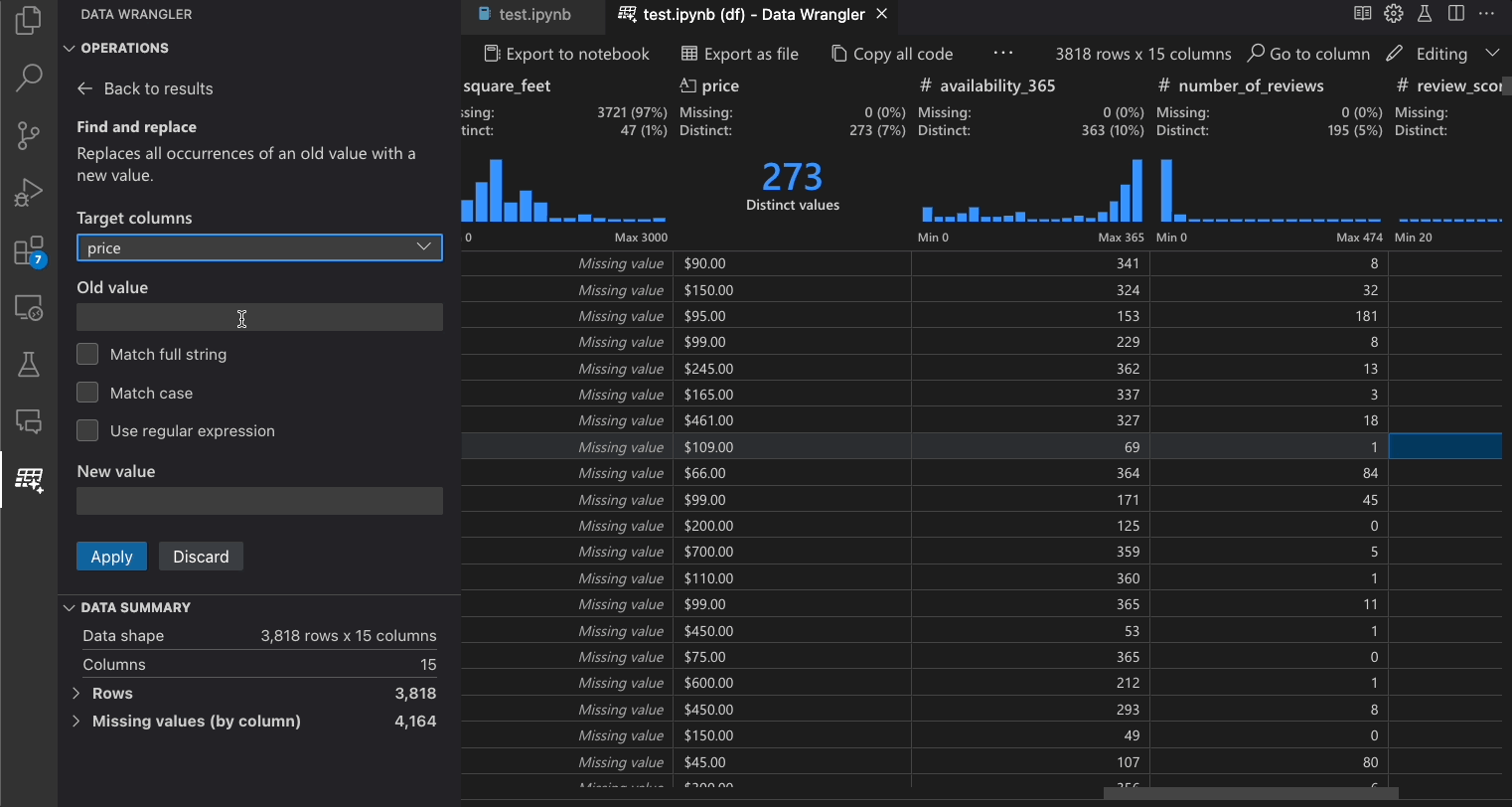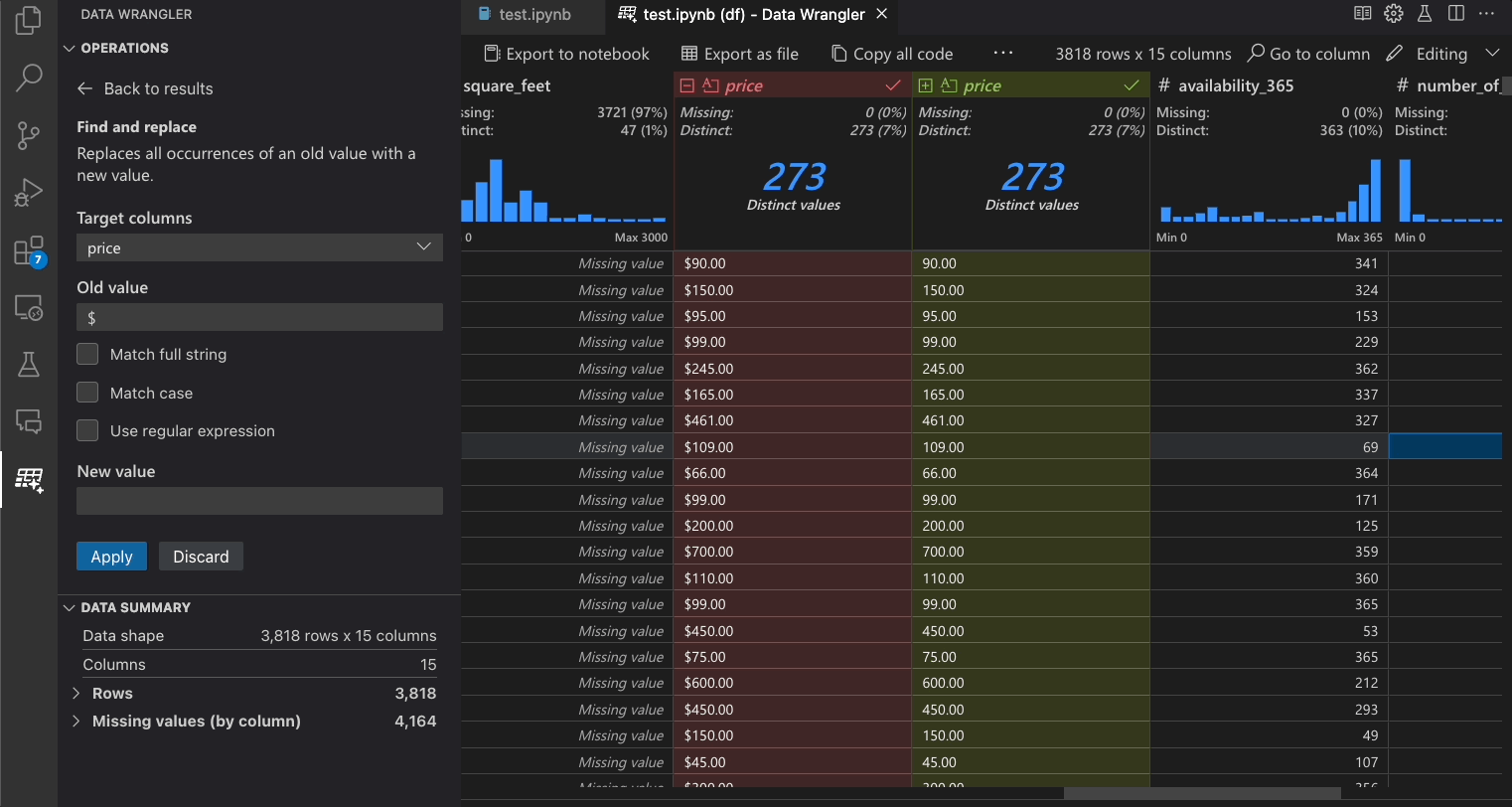
Die folgende Tabelle listet die Data Wrangler-Operationen auf, die derzeit in der Erstveröffentlichung von Data Wrangler unterstützt werden. Wir planen, in naher Zukunft weitere Operationen hinzuzufügen.
| Operation | Beschreibung |
|---|---|
| Sortieren | Spalte(n) aufsteigend oder absteigend sortieren |
| Filtern | Zeilen basierend auf einer oder mehreren Bedingungen filtern |
| Textlänge berechnen | Neue Spalte erstellen, deren Werte der Länge jedes Zeichenfolgenwerts in einer Textspalte entsprechen |
| One-Hot-Kodierung | Kategorische Daten in eine neue Spalte für jede Kategorie aufteilen |
| Multi-Label-Binarisierer | Kategorische Daten mit einem Trennzeichen in eine neue Spalte für jede Kategorie aufteilen |
| Spalte aus Formel erstellen | Eine Spalte mit einer benutzerdefinierten Python-Formel erstellen |
| Spaltentyp ändern | Datentyp einer Spalte ändern |
| Spalte löschen | Eine oder mehrere Spalten löschen |
| Spalte auswählen | Eine oder mehrere Spalten zum Beibehalten auswählen und den Rest löschen |
| Spalte umbenennen | Eine oder mehrere Spalten umbenennen |
| Spalte klonen | Eine Kopie einer oder mehrerer Spalten erstellen |
| Fehlende Werte löschen | Zeilen mit fehlenden Werten entfernen |
| Doppelte Zeilen löschen | Alle Zeilen löschen, die doppelte Werte in einer oder mehreren Spalten aufweisen |
| Fehlende Werte auffüllen | Zellen mit fehlenden Werten durch einen neuen Wert ersetzen |
| Finden und ersetzen | Zellen mit einem übereinstimmenden Muster ersetzen |
| Nach Spalte gruppieren und aggregieren | Ergebnisse nach Spalten gruppieren und aggregieren |
| Leerzeichen entfernen | Leerzeichen am Anfang und Ende von Text entfernen |
| Text aufteilen | Eine Spalte basierend auf einem vom Benutzer definierten Trennzeichen in mehrere Spalten aufteilen |
| Ersten Buchstaben großschreiben | Ersten Buchstaben in Großbuchstaben und die übrigen in Kleinbuchstaben umwandeln |
| Text in Kleinbuchstaben umwandeln | Text in Kleinbuchstaben umwandeln |
| Text in Großbuchstaben umwandeln | Text in GROSSBUCHSTABEN umwandeln |
| String-Transformation nach Beispiel | Automatische Durchführung von String-Transformationen, wenn ein Muster anhand der von Ihnen bereitgestellten Beispiele erkannt wird |
| DateTime-Formatierung nach Beispiel | Automatische Durchführung von DateTime-Formatierungen, wenn ein Muster anhand der von Ihnen bereitgestellten Beispiele erkannt wird |
| Neue Spalte nach Beispiel | Automatisch eine Spalte erstellen, wenn ein Muster anhand der von Ihnen bereitgestellten Beispiele erkannt wird. |
| Werte skalieren (Min/Max) | Eine numerische Spalte zwischen einem Minimal- und einem Maximalwert skalieren |
| Runden | Zahlen auf die angegebene Anzahl von Dezimalstellen runden |
| Abrunden (Bodenwert) | Zahlen auf die nächste ganze Zahl abrunden |
| Aufrunden (Deckenwert) | Zahlen auf die nächste ganze Zahl aufrunden |
| Benutzerdefinierte Operation | Automatisch eine neue Spalte basierend auf Beispielen und der Ableitung vorhandener Spalten erstellen |
Wenn eine Operation fehlt und Sie diese in Data Wrangler unterstützt sehen möchten, reichen Sie bitte eine Feature-Anfrage in unserem Data Wrangler GitHub-Repository ein.
Vorherige Schritte ändern
Jeder Schritt des generierten Codes kann über das Panel Bereinigungsschritte geändert werden. Wählen Sie zuerst den zu ändernden Schritt aus. Während Sie dann Änderungen an der Operation vornehmen (entweder über Code oder das Operationspanel), werden die Auswirkungen Ihrer Änderungen auf die Daten im Raster hervorgehoben.
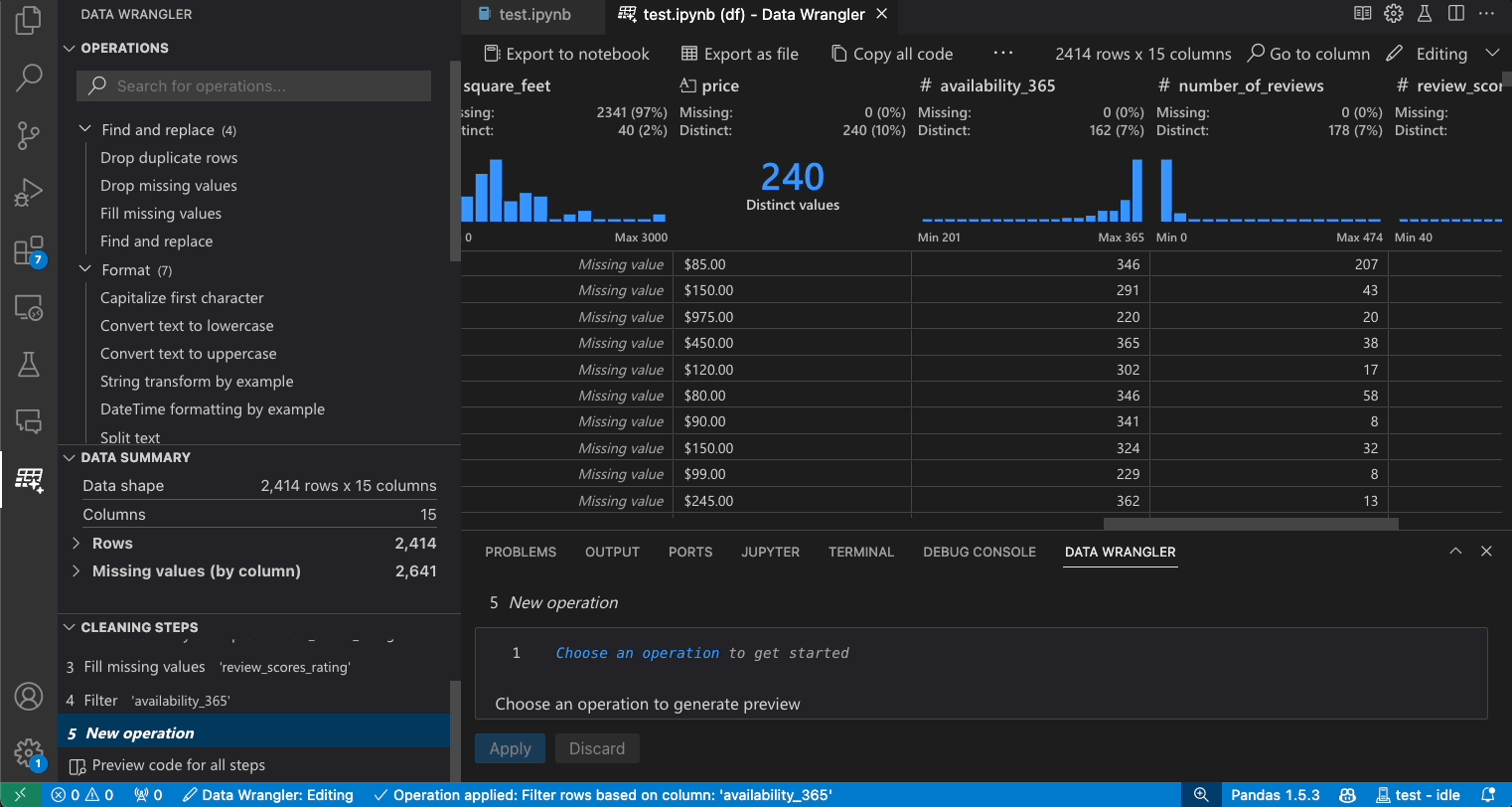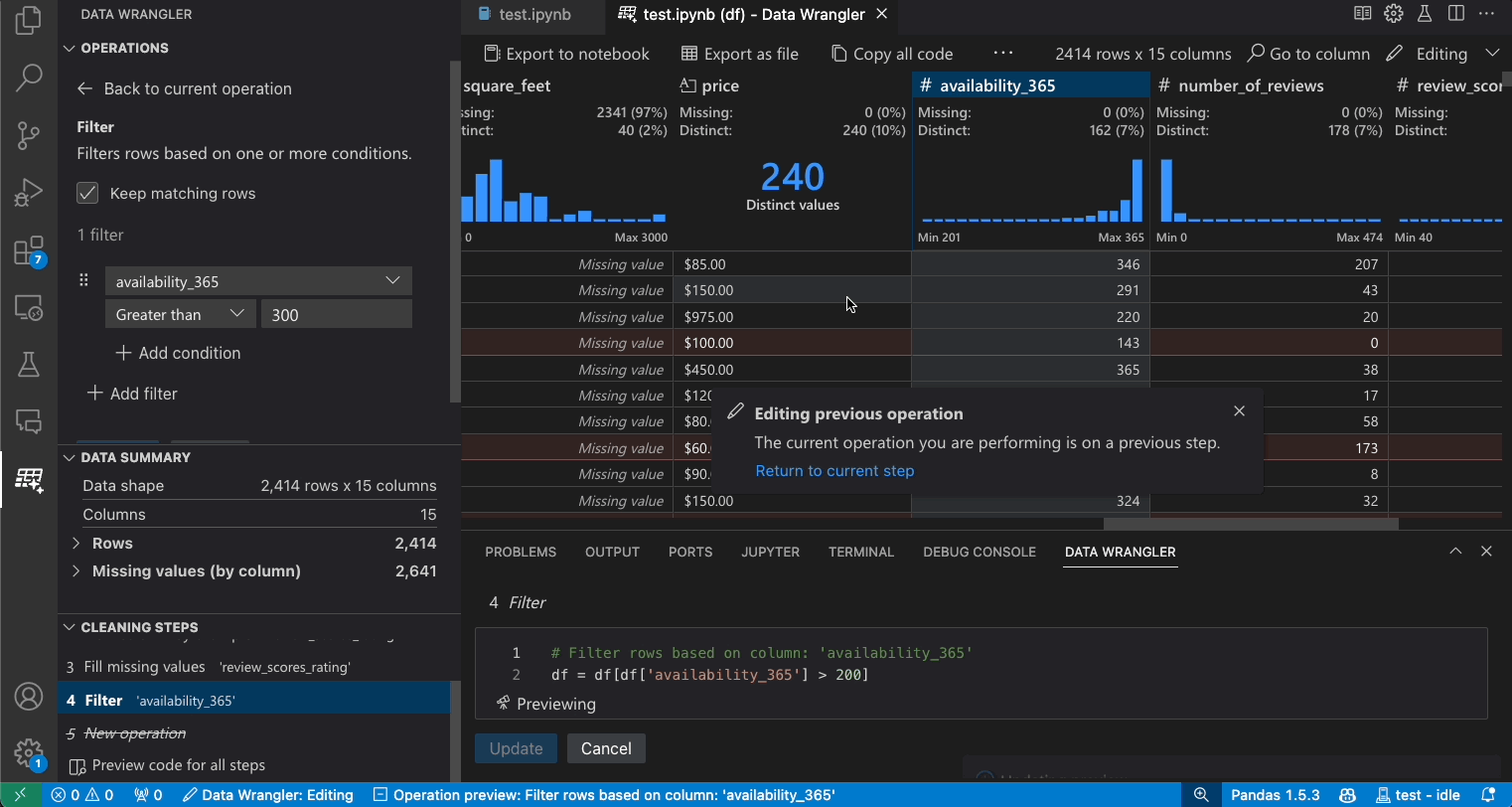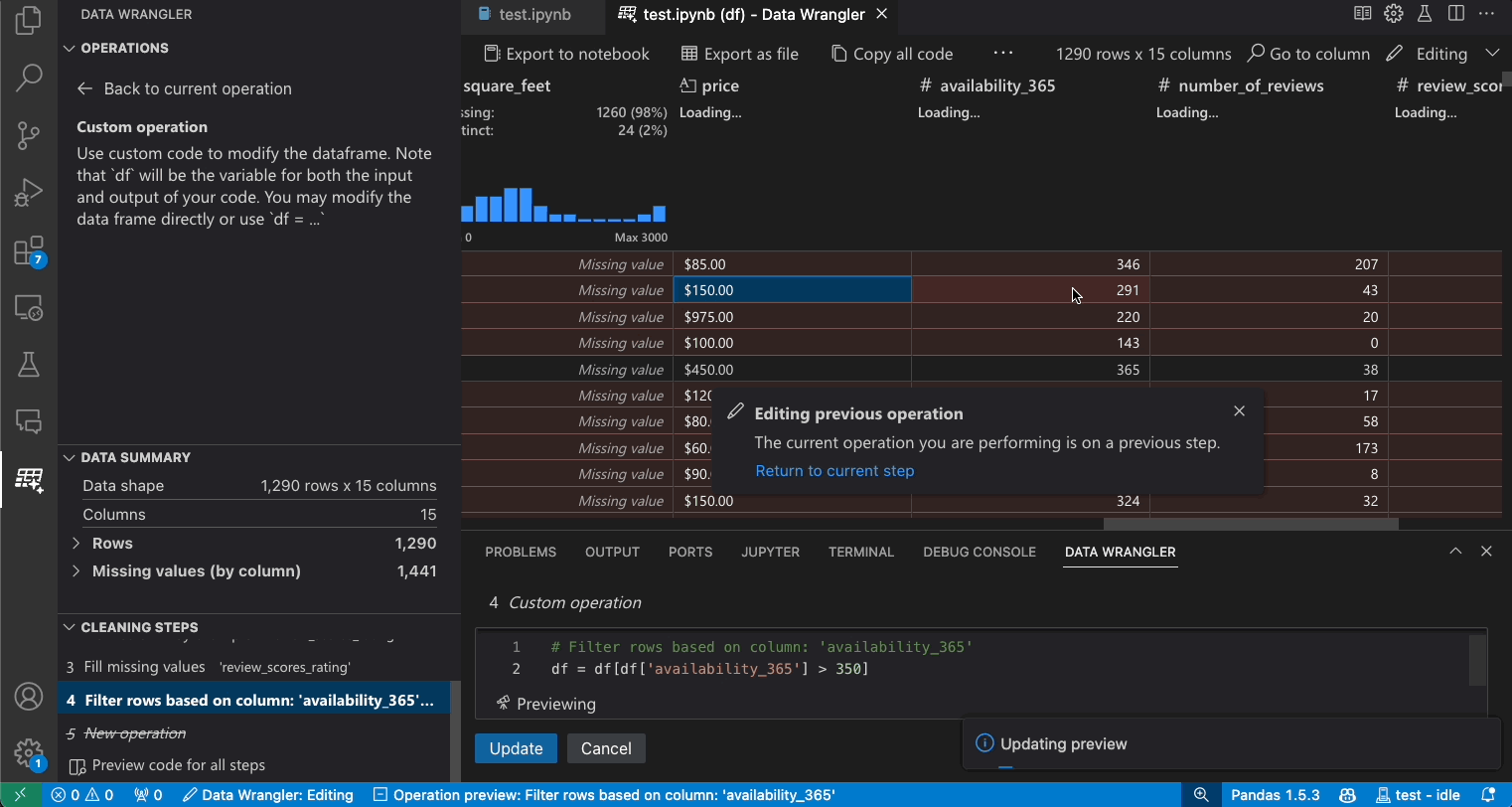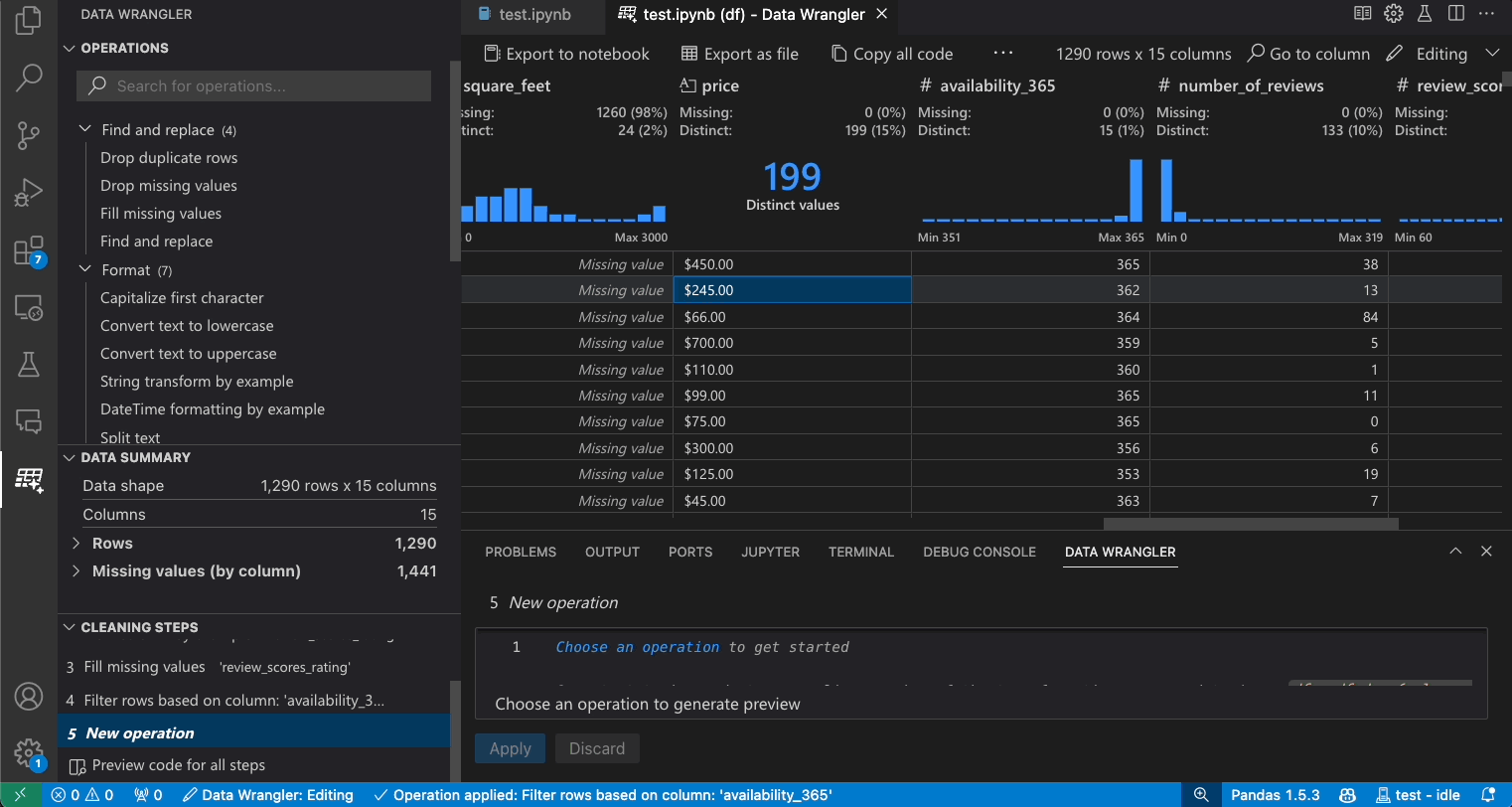
Code bearbeiten und exportieren
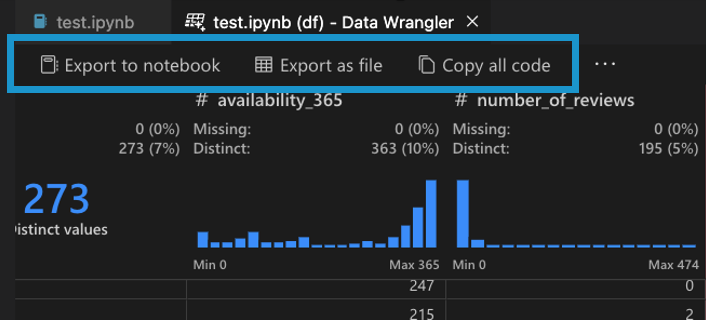
Sobald Sie mit Ihren Datenbereinigungsschritten in Data Wrangler fertig sind, gibt es drei Möglichkeiten, Ihren bereinigten Datensatz aus Data Wrangler zu exportieren.
- Code zurück in das Notebook exportieren und beenden: Dies erstellt eine neue Zelle in Ihrem Jupyter Notebook mit dem gesamten generierten Datenbereinigungscode, verpackt in einer Python-Funktion.
- Daten in eine Datei exportieren: Dies speichert den bereinigten Datensatz als neue CSV- oder Parquet-Datei auf Ihrem Computer.
- Code in die Zwischenablage kopieren: Dies kopiert den gesamten Code, der von Data Wrangler für die Datenbereinigungsoperationen generiert wurde.
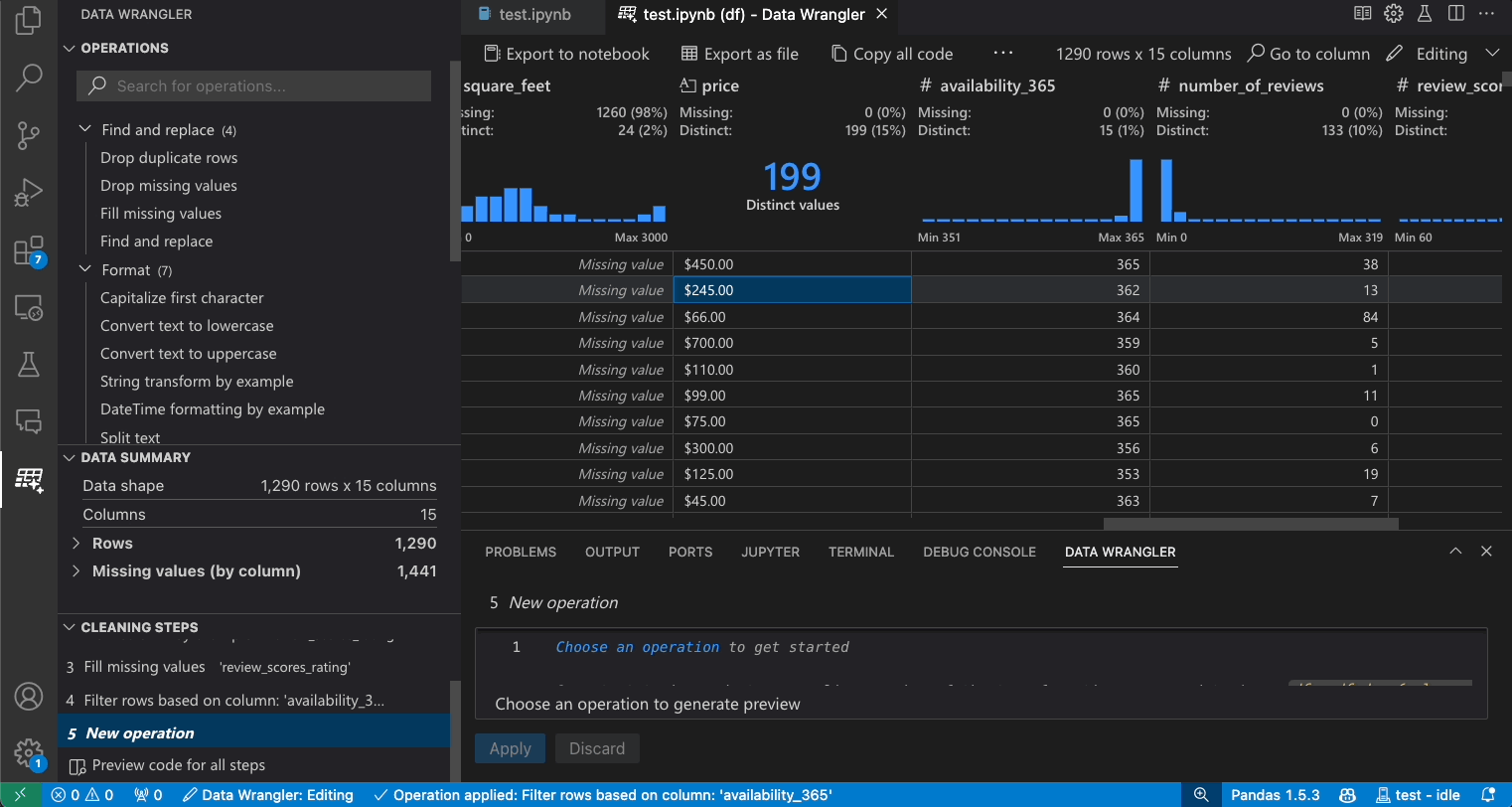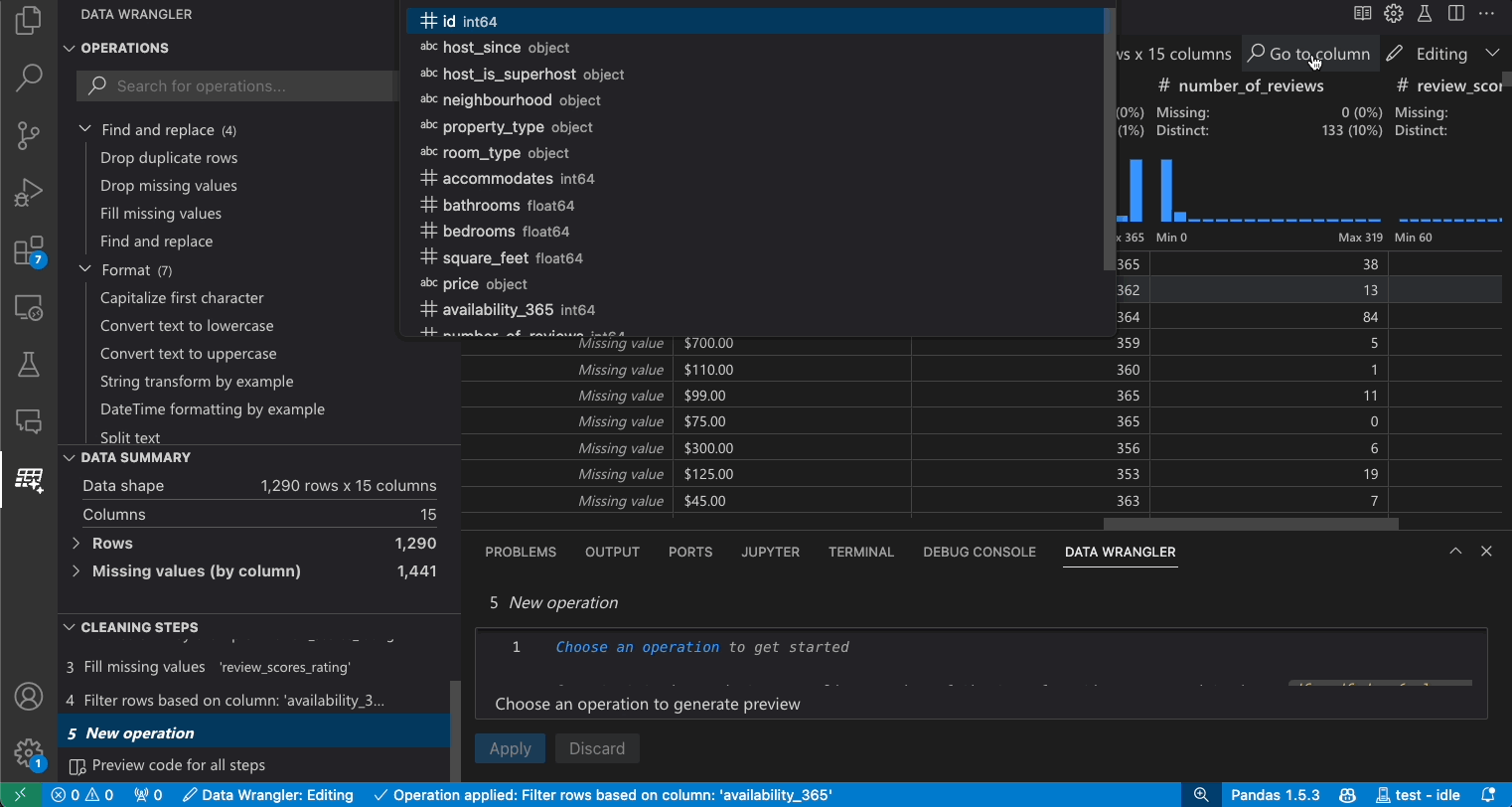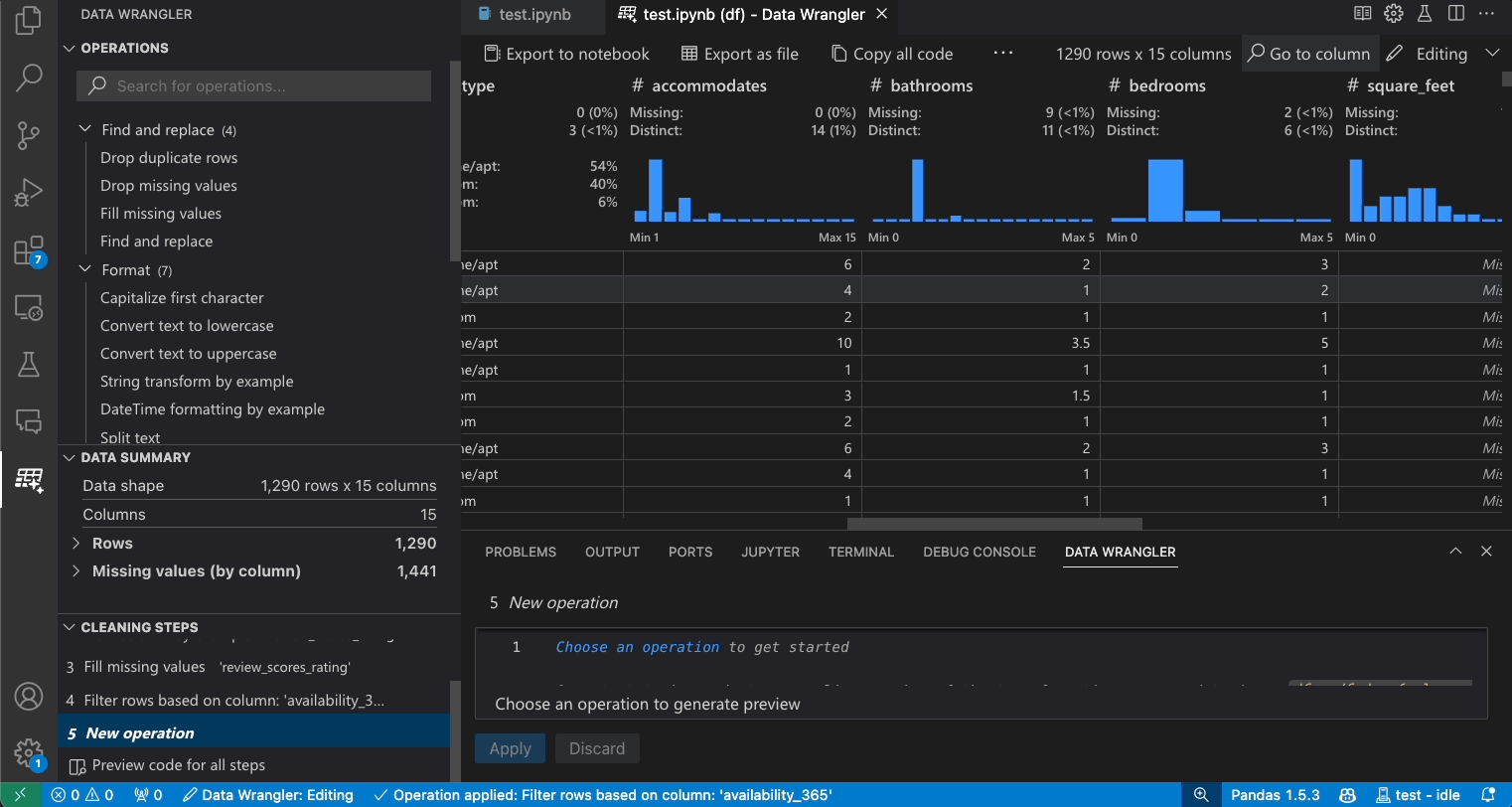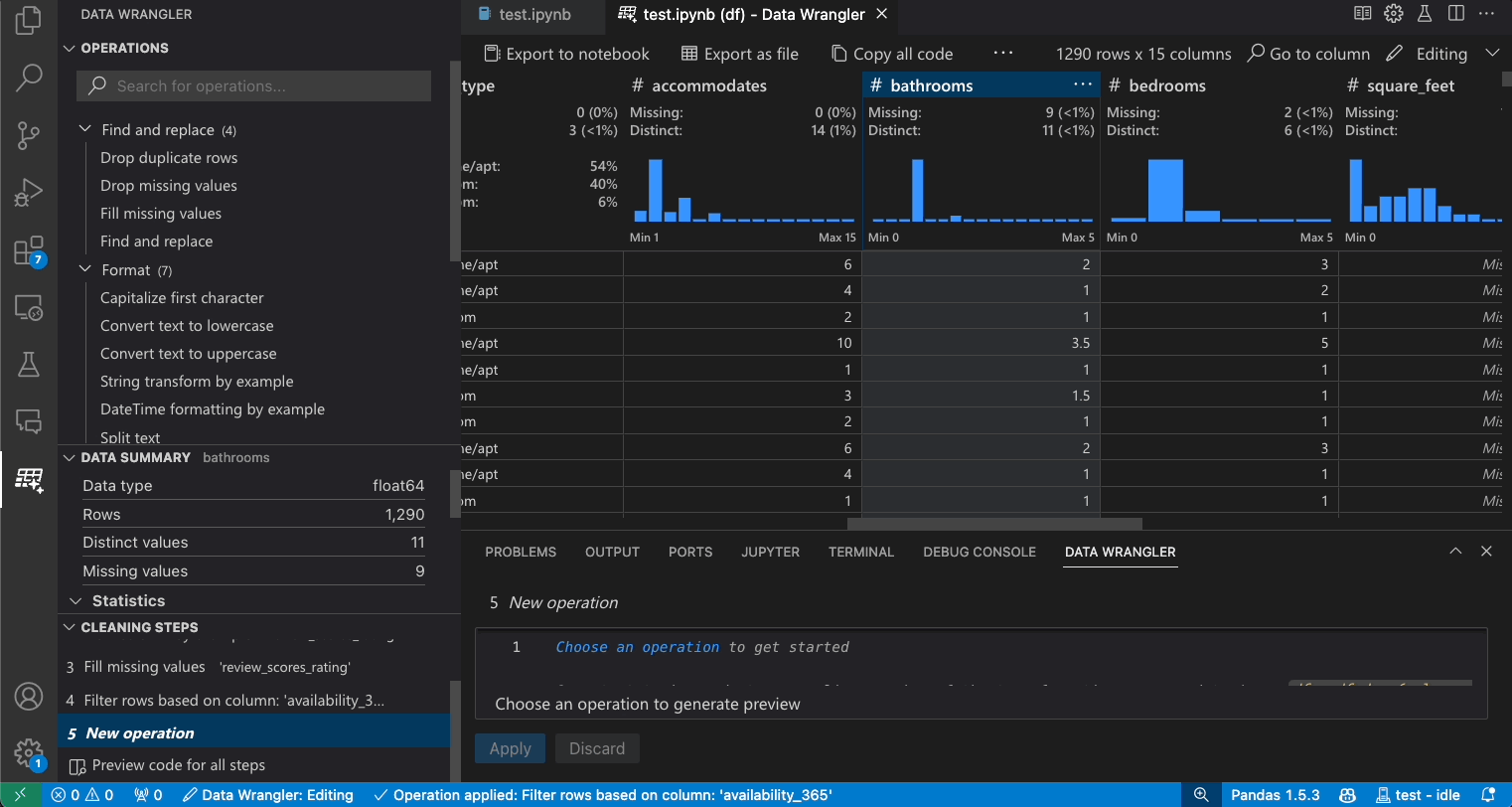
Nach Spalten suchen
Um eine bestimmte Spalte in Ihrem Datensatz zu finden, wählen Sie in der Data Wrangler-Symbolleiste Zu Spalte gehen und suchen Sie die entsprechende Spalte.
Fehlerbehebung
Allgemeine Probleme bei der Kernel-Verbindung
Bei allgemeinen Verbindungsproblemen lesen Sie bitte den Abschnitt "Verbindung mit einem Python-Kernel herstellen" oben für alternative Verbindungsmethoden. Um Probleme im Zusammenhang mit der lokalen Python-Interpreter-Option zu beheben, besteht eine Möglichkeit, das Problem zu beheben, indem Sie verschiedene Versionen der Jupyter- und Python-Erweiterungen installieren. Wenn beispielsweise stabile Versionen der Erweiterungen installiert sind, könnten Sie die Vorabversion (oder umgekehrt) installieren.
Um einen bereits zwischengespeicherten Kernel zu löschen, können Sie den Befehl Data Wrangler: Cached runtime löschen aus der Befehlspalette ausführen ⇧⌘P (Windows, Linux Ctrl+Shift+P).
Beim Öffnen einer Datendatei tritt ein UnicodeDecodeError auf
Wenn beim direkten Öffnen einer Datendatei in Data Wrangler ein UnicodeDecodeError auftritt, kann dies auf zwei mögliche Probleme zurückzuführen sein
- Die zu öffnende Datei hat eine andere Kodierung als
UTF-8 - Die Datei ist beschädigt.
Um diesen Fehler zu umgehen, müssen Sie Data Wrangler aus einem Jupyter Notebook anstatt direkt aus einer Datendatei öffnen. Verwenden Sie ein Jupyter Notebook, um die Datei mit Pandas zu lesen, z. B. mit der read_csv-Methode. Verwenden Sie innerhalb der read-Methode die Parameter encoding und/oder encoding_errors, um die zu verwendende Kodierung oder den Umgang mit Kodierungsfehlern zu definieren. Wenn Sie nicht wissen, welche Kodierung für diese Datei funktioniert, können Sie eine Bibliothek wie chardet verwenden, um zu versuchen, eine passende Kodierung zu ermitteln.
Fragen und Feedback
Wenn Sie Probleme haben, Feature-Wünsche haben oder anderes Feedback geben möchten, reichen Sie bitte ein Issue in unserem GitHub-Repository ein: https://github.com/microsoft/vscode-data-wrangler/issues/new/choose
Daten und Telemetrie
Die Microsoft Data Wrangler-Erweiterung für Visual Studio Code sammelt Nutzungsdaten und sendet diese an Microsoft, um unsere Produkte und Dienstleistungen zu verbessern. Lesen Sie unsere Datenschutzerklärung, um mehr zu erfahren. Diese Erweiterung respektiert die Einstellung telemetry.telemetryLevel, über die Sie unter https://visualstudiocode.de/docs/configure/telemetry mehr erfahren können.