Data Science in Microsoft Fabric mit Visual Studio Code
Sie können Data Science- und Data Engineering-Lösungen für Microsoft Fabric innerhalb von VS Code erstellen und entwickeln. Microsoft Fabric-Erweiterungen für VS Code bieten eine integrierte Entwicklungsumgebung für die Arbeit mit Fabric-Artefakten, Lakehouses, Notebooks und benutzerdefinierten Datenfunktionen.
Was ist Microsoft Fabric?
Microsoft Fabric ist eine unternehmensgerechte, End-to-End-Analyseplattform. Sie vereinheitlicht Datenbewegung, Datenverarbeitung, Ingestion, Transformation, Echtzeit-Ereignis-Routing und Berichterstellung. Sie unterstützt diese Funktionen mit integrierten Diensten wie Data Engineering, Data Factory, Data Science, Echtzeit-Intelligenz, Data Warehouse und Datenbanken. Melden Sie sich kostenlos an und erkunden Sie Microsoft Fabric 60 Tage lang – keine Kreditkarte erforderlich.

Voraussetzungen
Bevor Sie mit den Microsoft Fabric-Erweiterungen für VS Code beginnen, benötigen Sie Folgendes:
- Visual Studio Code: Installieren Sie die neueste VS Code-Version.
- Microsoft Fabric-Konto: Sie benötigen Zugriff auf einen Microsoft Fabric-Arbeitsbereich. Sie können eine kostenlose Testversion abonnieren, um zu beginnen.
- Python: Installieren Sie Python 3.8 oder höher, um mit Notebooks und benutzerdefinierten Datenfunktionen in VS Code zu arbeiten.
Installation und Einrichtung
Sie können die Erweiterungen über den Visual Studio Marketplace oder direkt in VS Code finden und installieren. Wählen Sie die Ansicht Erweiterungen (⇧⌘X (Windows, Linux Ctrl+Shift+X)) und suchen Sie nach Microsoft Fabric.
Welche Erweiterungen Sie verwenden sollten
| Erweiterung | Am besten geeignet für | Hauptfunktionen | Empfohlen für Sie, wenn... | Dokumentation |
|---|---|---|---|---|
| Microsoft Fabric-Erweiterung | Allgemeine Arbeitsbereichsverwaltung, Elementverwaltung und Arbeit mit Elementdefinitionen | - Fabric-Elemente verwalten (Lakehouses, Notebooks, Pipelines) - Microsoft-Konto-Anmeldung & Mandantenwechsel - Einheitliche oder gruppierte Elementansichten - Fabric-Notebooks mit IntelliSense bearbeiten - Befehlspaletten-Integration ( Fabric: Befehle) |
Sie möchten eine einzige Erweiterung, um Arbeitsbereiche, Notebooks und Elemente in Fabric direkt von VS Code aus zu verwalten. | Was ist die Fabric VS Code-Erweiterung? |
| Fabric Benutzerdefinierte Datenfunktionen | Entwickler, die benutzerdefinierte Transformationen & Workflows erstellen | - Serverlose Funktionen in Fabric erstellen - Lokales Debugging mit Breakpoints - Datenquellenverbindungen verwalten - Python-Bibliotheken installieren/verwalten - Funktionen direkt in den Fabric-Arbeitsbereich deployen |
Sie erstellen Automatisierungs- oder Datentransformationslogik und benötigen Debugging + Deployment von VS Code. | Benutzerdefinierte Datenfunktionen in VS Code entwickeln |
| Fabric Data Engineering | Daten-Ingenieure, die mit großen Datenmengen & Spark arbeiten | - Lakehouses erkunden (Tabellen, Rohdateien) - Spark-Notebooks entwickeln/debuggen - Spark-Jobdefinitionen erstellen/testen - Notebooks zwischen lokalem VS Code & Fabric synchronisieren - Schemas & Beispieldaten anzeigen |
Sie arbeiten mit Spark, Lakehouses oder großen Datenpipelines und möchten lokal erkunden, entwickeln und debuggen. | Fabric-Notebooks in VS Code entwickeln |
Erste Schritte
Sobald Sie die Erweiterungen installiert und sich angemeldet haben, können Sie mit Fabric-Arbeitsbereichen und -Elementen arbeiten. Geben Sie in der Befehlspalette (⇧⌘P (Windows, Linux Ctrl+Shift+P)) Fabric ein, um die spezifischen Befehle für Microsoft Fabric anzuzeigen.
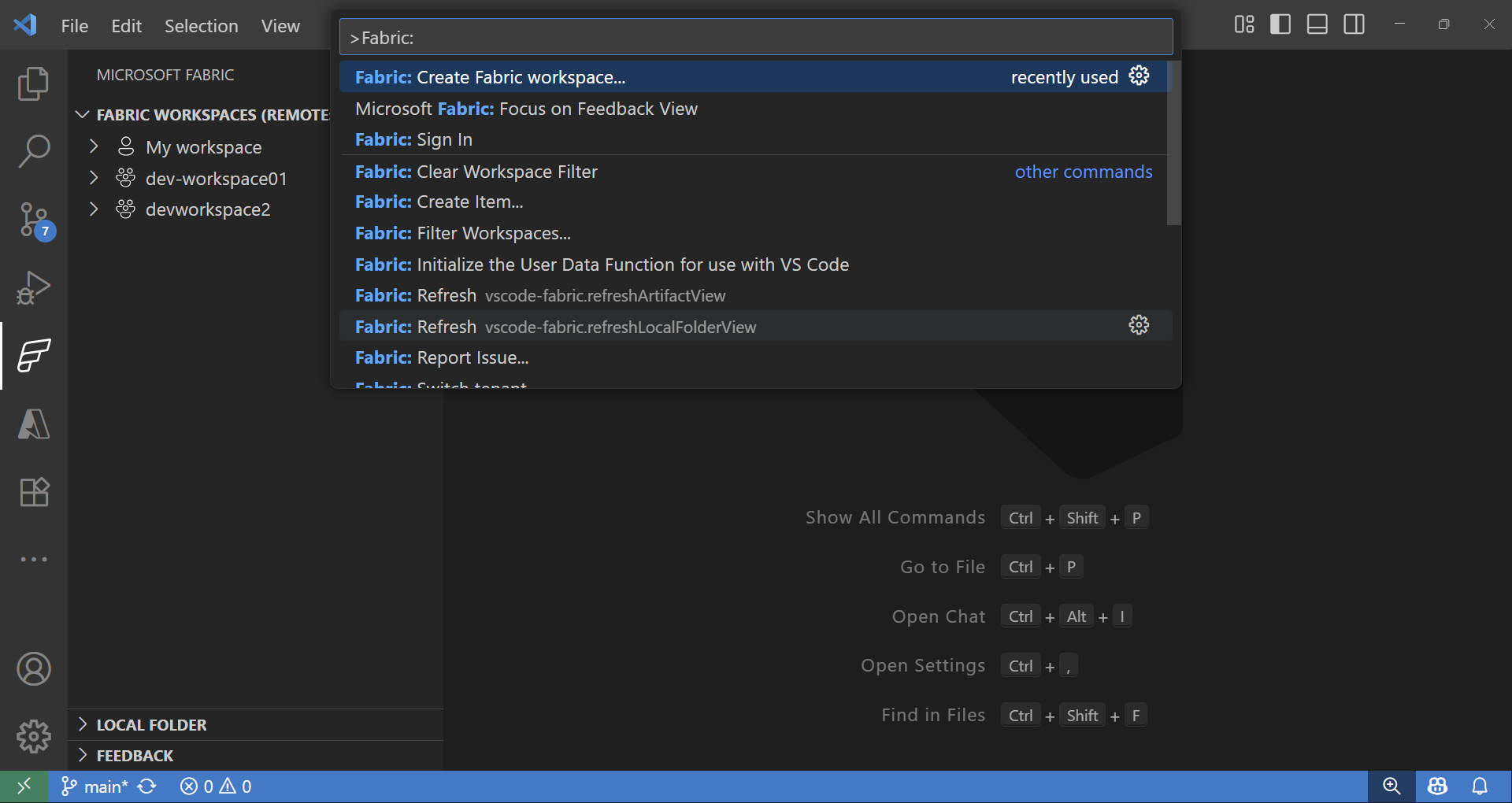
Fabric Workspace und Item Explorer
Die Fabric-Erweiterungen bieten eine nahtlose Möglichkeit, sowohl mit Remote- als auch mit lokalen Fabric-Elementen zu arbeiten.
- In der Fabric-Erweiterung listet der Abschnitt Fabric Workspaces alle Elemente aus Ihrem Remote-Arbeitsbereich auf, organisiert nach Typ (Lakehouses, Notebooks, Pipelines und mehr).
- In der Fabric-Erweiterung zeigt der Abschnitt Lokaler Ordner einen oder mehrere Fabric-Elementordner an, die in VS Code geöffnet sind. Er spiegelt die Struktur Ihrer Fabric-Elementdefinition für jeden Typ wider, der in VS Code geöffnet ist. Dies ermöglicht Ihnen, lokal zu entwickeln und Ihre Änderungen in den aktuellen oder neuen Arbeitsbereich zu veröffentlichen.
Benutzerdefinierte Datenfunktionen für Data Science nutzen
-
Geben Sie in der Befehlspalette (⇧⌘P (Windows, Linux Ctrl+Shift+P)) Fabric: Create Item ein.
-
Wählen Sie Ihren Arbeitsbereich und dann User data function aus. Geben Sie einen Namen und wählen Sie die Sprache Python.
-
Sie werden aufgefordert, die Python-virtuelle Umgebung einzurichten, und fahren mit der lokalen Einrichtung fort.
-
Installieren Sie die Bibliotheken mit
pip installoder wählen Sie das Element der benutzerdefinierten Datenfunktion in der Fabric-Erweiterung aus, um Bibliotheken hinzuzufügen. Aktualisieren Sie die Dateirequirements.txt, um die Abhängigkeiten anzugeben.fabric-user-data-functions ~= 1.0 pandas == 2.3.1 numpy == 2.3.2 requests == 2.32.5 scikit-learn=1.2.0 joblib=1.2.0 -
Öffnen Sie
functions_app.py. Hier ist ein Beispiel für die Entwicklung einer benutzerdefinierten Datenfunktion für Data Science mit scikit-learn.import datetime import fabric.functions as fn import logging # Import additional libraries import pandas as pd from sklearn.ensemble import RandomForestClassifier from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score import joblib udf = fn.UserDataFunctions() @udf.function() def train_churn_model(data: list, targetColumn: str) -> dict: ''' Description: Train a Random Forest model to predict customer churn using pandas and scikit-learn. Args: - data (list): List of dictionaries containing customer features and churn target Example: [{"Age": 25, "Income": 50000, "Churn": 0}, {"Age": 45, "Income": 75000, "Churn": 1}] - targetColumn (str): Name of the target column for churn prediction Example: "Churn" Returns: dict: Model training results including accuracy and feature information ''' # Convert data to DataFrame df = pd.DataFrame(data) # Prepare features and target numeric_features = df.select_dtypes(include=['number']).columns.tolist() numeric_features.remove(targetColumn) X = df[numeric_features] y = df[targetColumn] # Split and scale data X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test) # Train model model = RandomForestClassifier(n_estimators=100, random_state=42) model.fit(X_train_scaled, y_train) # Evaluate and save accuracy = accuracy_score(y_test, model.predict(X_test_scaled)) joblib.dump(model, 'churn_model.pkl') joblib.dump(scaler, 'scaler.pkl') return { 'accuracy': float(accuracy), 'features': numeric_features, 'message': f'Model trained with {len(X_train)} samples and {accuracy:.2%} accuracy' } @udf.function() def predict_churn(customer_data: list) -> list: ''' Description: Predict customer churn using trained Random Forest model. Args: - customer_data (list): List of dictionaries containing customer features for prediction Example: [{"Age": 30, "Income": 60000}, {"Age": 55, "Income": 80000}] Returns: list: Customer data with churn predictions and probability scores ''' # Load saved model and scaler model = joblib.load('churn_model.pkl') scaler = joblib.load('scaler.pkl') # Convert to DataFrame and scale features df = pd.DataFrame(customer_data) X_scaled = scaler.transform(df) # Make predictions predictions = model.predict(X_scaled) probabilities = model.predict_proba(X_scaled)[:, 1] # Add predictions to original data results = customer_data.copy() for i, (pred, prob) in enumerate(zip(predictions, probabilities)): results[i]['churn_prediction'] = int(pred) results[i]['churn_probability'] = float(prob) return results -
Testen Sie Ihre Funktionen lokal, indem Sie F5 drücken.
-
Wählen Sie in der Fabric-Erweiterung im Abschnitt Lokaler Ordner die Funktion aus und deployen Sie sie in Ihren Arbeitsbereich.
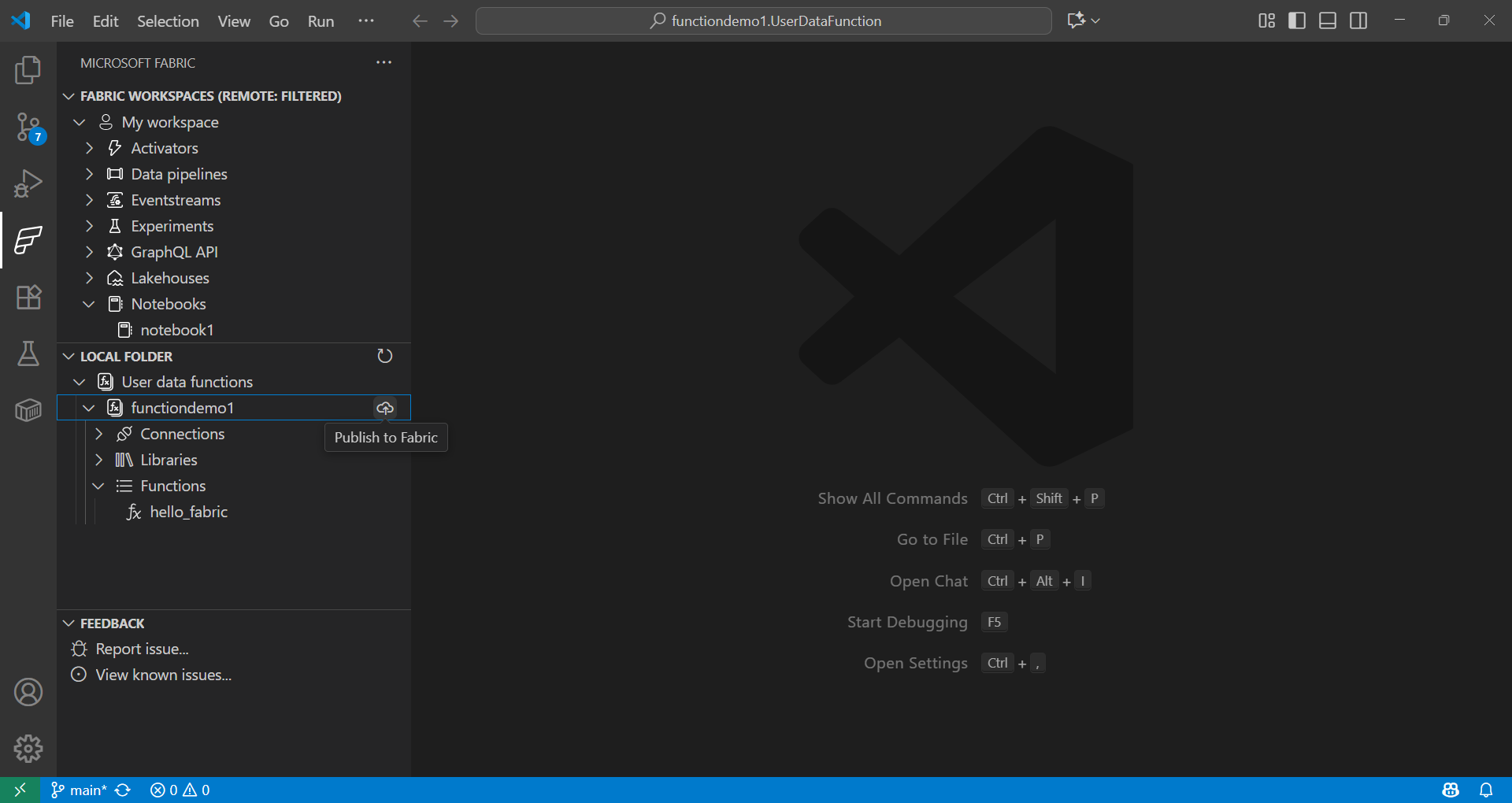
Erfahren Sie mehr über das Aufrufen der Funktion aus
Fabric Notebooks für Data Science nutzen
Ein Fabric Notebook ist eine interaktive Arbeitsmappe in Microsoft Fabric zum gleichzeitigen Schreiben und Ausführen von Code, Visualisierungen und Markdown. Notebooks unterstützen mehrere Sprachen (Python, Spark, SQL, Scala und mehr) und eignen sich ideal für die Datenexploration, -transformation und -modellentwicklung in Fabric, wobei Ihre vorhandenen Daten in OneLake verwendet werden.
Beispiel
Die folgende Zelle liest eine CSV-Datei mit Spark, konvertiert sie in pandas und trainiert ein logistisches Regressionsmodell mit scikit-learn. Ersetzen Sie Spaltennamen und Pfade durch Ihre Dataset-Werte.
def train_logistic_from_spark(spark, csv_path):
# Read CSV with Spark, convert to pandas
sdf = spark.read.option("header", "true").option("inferSchema", "true").csv(csv_path)
df = sdf.toPandas().dropna()
# Adjust these to match your dataset
X = df[['feature1', 'feature2']]
y = df['label']
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = LogisticRegression(max_iter=200)
model.fit(X_train, y_train)
preds = model.predict(X_test)
return {'accuracy': float(accuracy_score(y_test, preds))}
# Example usage in a Fabric notebook cell
# train_logistic_from_spark(spark, '/path/to/data.csv')
Weitere Informationen finden Sie in der Dokumentation zu Microsoft Fabric Notebooks.
Git-Integration
Microsoft Fabric unterstützt die Git-Integration, die Versionskontrolle und Zusammenarbeit über Daten- und Analyseprojekte hinweg ermöglicht. Sie können einen Fabric-Arbeitsbereich mit Git-Repositorys, hauptsächlich Azure DevOps oder GitHub, verbinden, und nur unterstützte Elemente werden synchronisiert. Diese Integration unterstützt auch den CI/CD-Workflow, damit Teams Releases effizient verwalten und qualitativ hochwertige Analyseumgebungen aufrechterhalten können.

Nächste Schritte
Nachdem Sie die Microsoft Fabric-Erweiterungen in VS Code eingerichtet haben, erkunden Sie diese Ressourcen, um Ihr Wissen zu vertiefen.
- Mehr über Microsoft Fabric für Data Science erfahren.
- Richten Sie Ihre Fabric-Testkapazität ein
- Grundlagen von Microsoft Fabric
Um sich mit der Community auszutauschen und Unterstützung zu erhalten