Schnellstartanleitung für Data Wrangler in VS Code
Data Wrangler ist ein codezentriertes Tool zur Datenanzeige und -bereinigung, das in VS Code und VS Code Jupyter Notebooks integriert ist. Es bietet eine benutzerfreundliche Oberfläche zur Anzeige und Analyse Ihrer Daten, zeigt aufschlussreiche Spaltenstatistiken und Visualisierungen und generiert automatisch Pandas-Code, während Sie die Daten bereinigen und transformieren.
Das Folgende ist ein Beispiel für das Öffnen von Data Wrangler aus dem Notebook, um die Daten mit den integrierten Operationen zu analysieren und zu bereinigen. Anschließend wird der automatisch generierte Code wieder in das Notebook exportiert.
Ziel dieser Seite ist es, Ihnen den schnellen Einstieg in Data Wrangler zu ermöglichen.
Richten Sie Ihre Umgebung ein
- Wenn Sie dies noch nicht getan haben, installieren Sie Python (Hinweis: Data Wrangler unterstützt nur Python-Version 3.8 oder höher).
- Installieren Sie die Data Wrangler-Erweiterung
Wenn Sie Data Wrangler zum ersten Mal starten, werden Sie gefragt, mit welchem Python-Kernel Sie sich verbinden möchten. Außerdem wird Ihr Computer und Ihre Umgebung überprüft, um festzustellen, ob die erforderlichen Python-Pakete wie Pandas installiert sind.
Data Wrangler öffnen
Sie befinden sich jederzeit in einer isolierten Umgebung von Data Wrangler, d. h. Sie können die Daten sicher untersuchen und transformieren. Der ursprüngliche Datensatz wird nicht geändert, bis Sie Ihre Änderungen explizit exportieren.
Data Wrangler aus einem Jupyter Notebook starten
Wenn Sie einen Pandas-DataFrame in Ihrem Notebook haben, sehen Sie nun eine Schaltfläche „df“ in Data Wrangler öffnen (wobei df der Variablenname Ihres DataFrames ist) unterhalb der Zelle, nachdem Sie df.head(), df.tail(), display(df), print(df) oder df ausgeführt haben.
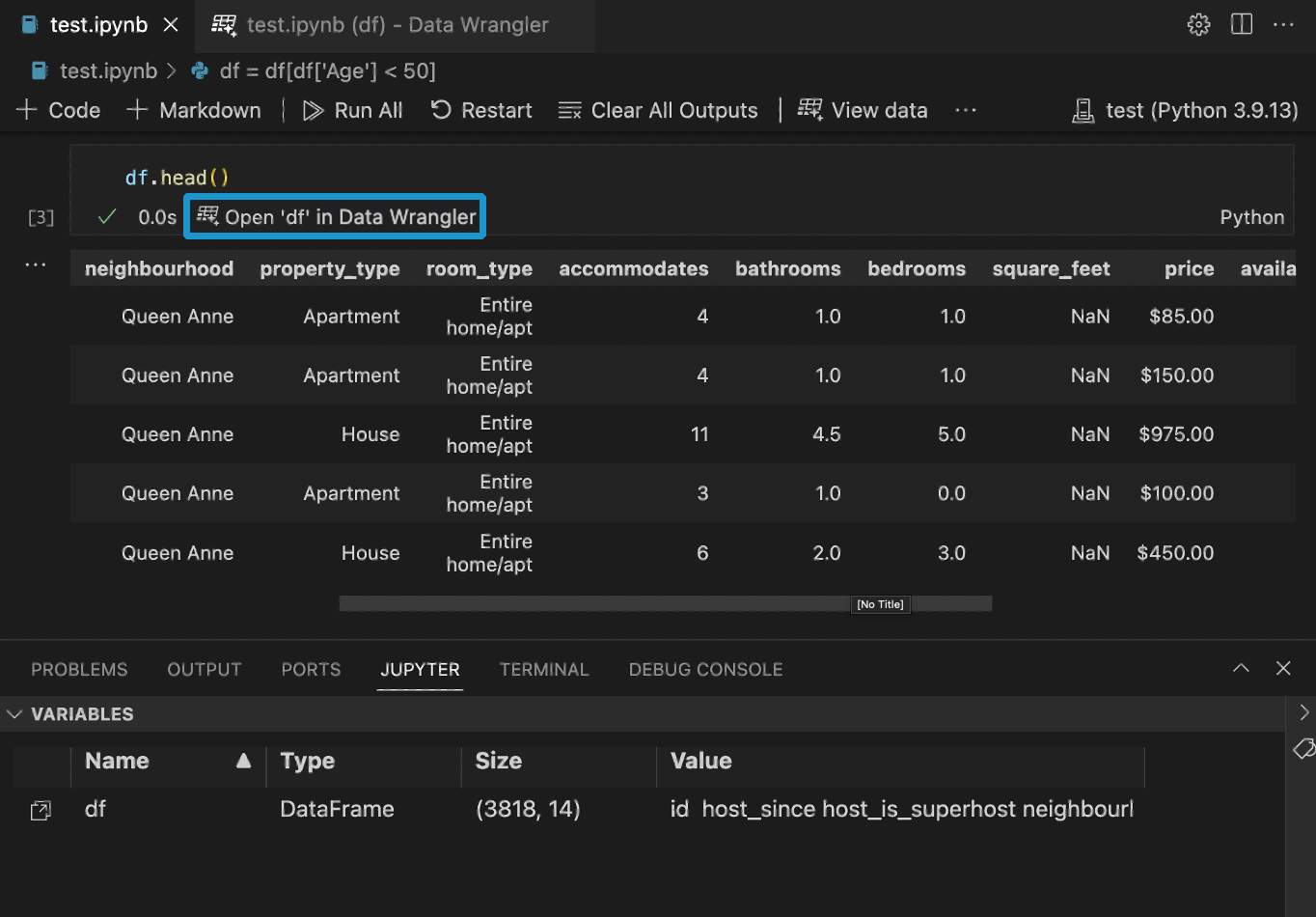
Data Wrangler direkt aus einer Datei starten
Sie können Data Wrangler auch direkt aus einer lokalen Datei (z. B. einer .csv-Datei) starten. Öffnen Sie dazu in VS Code einen Ordner, der die zu öffnende Datei enthält. Klicken Sie im Datei-Explorer mit der rechten Maustaste auf die Datei und wählen Sie In Data Wrangler öffnen.
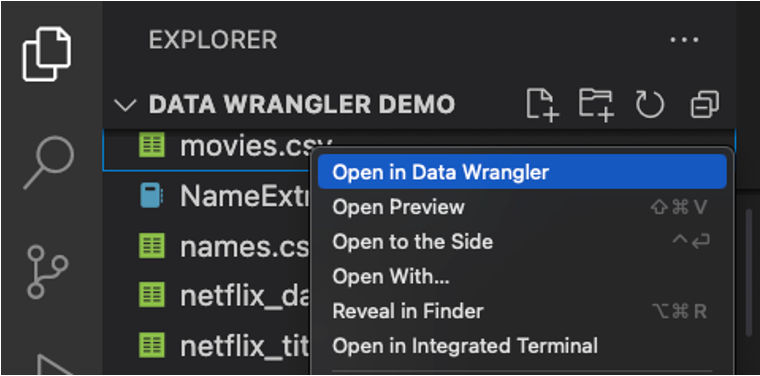
Benutzeroberfläche
Data Wrangler hat zwei Modi, wenn Sie mit Ihren Daten arbeiten. Die Details für jeden Modus werden in den folgenden Abschnitten erläutert.
- Anzeigemodus: Der Anzeigemodus optimiert die Benutzeroberfläche, damit Sie Ihre Daten schnell anzeigen, filtern und sortieren können. Dieser Modus eignet sich hervorragend für die anfängliche Erkundung des Datensatzes.
- Bearbeitungsmodus: Der Bearbeitungsmodus optimiert die Benutzeroberfläche, damit Sie Transformationen, Bereinigungen oder Modifikationen auf Ihren Datensatz anwenden können. Während Sie diese Transformationen in der Benutzeroberfläche anwenden, generiert Data Wrangler automatisch den entsprechenden Pandas-Code, der zur Wiederverwendung zurück in Ihr Notebook exportiert werden kann.
Hinweis: Standardmäßig öffnet sich Data Wrangler im Anzeigemodus. Sie können dieses Verhalten in der Einstellungsbearbeitung unter ändern.
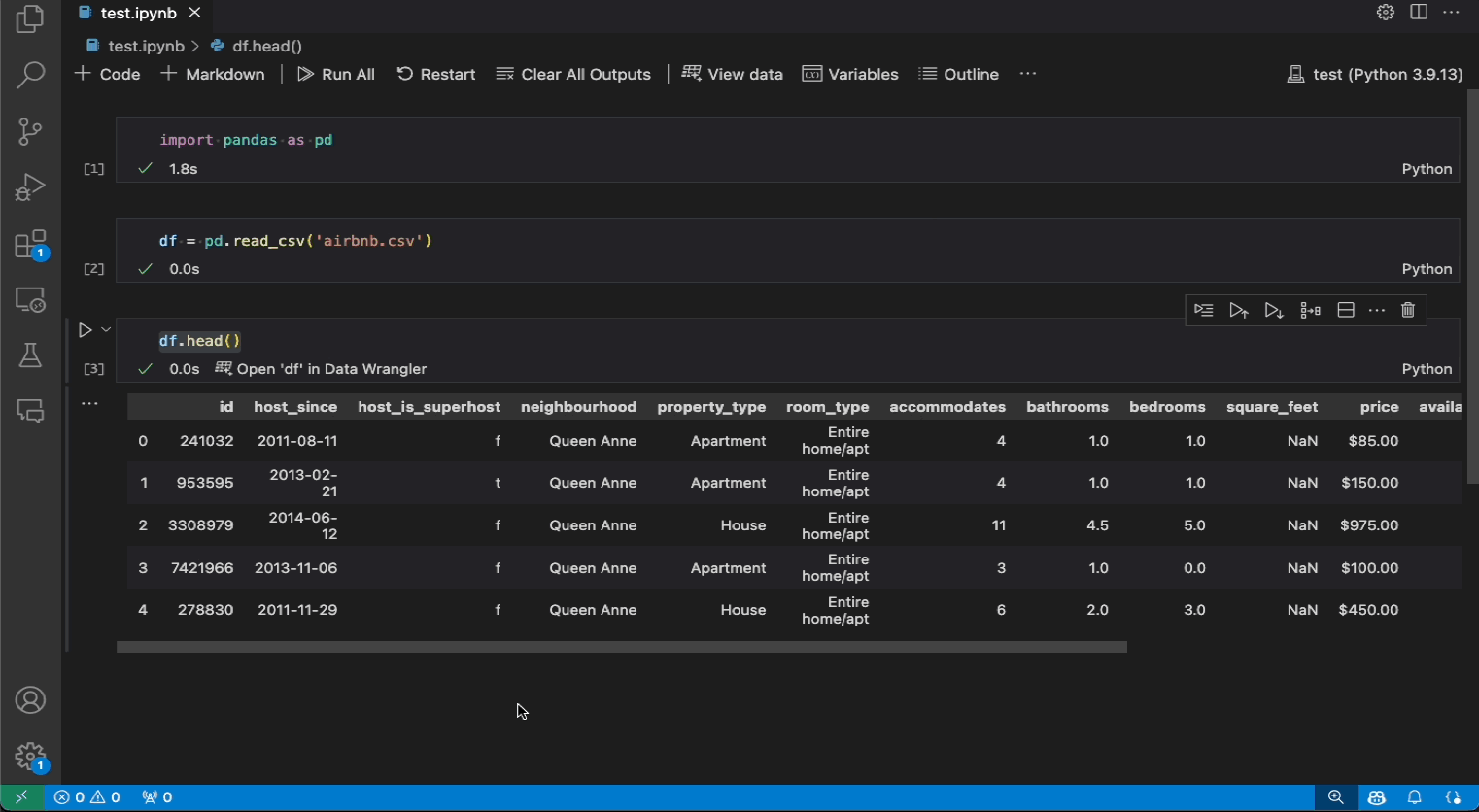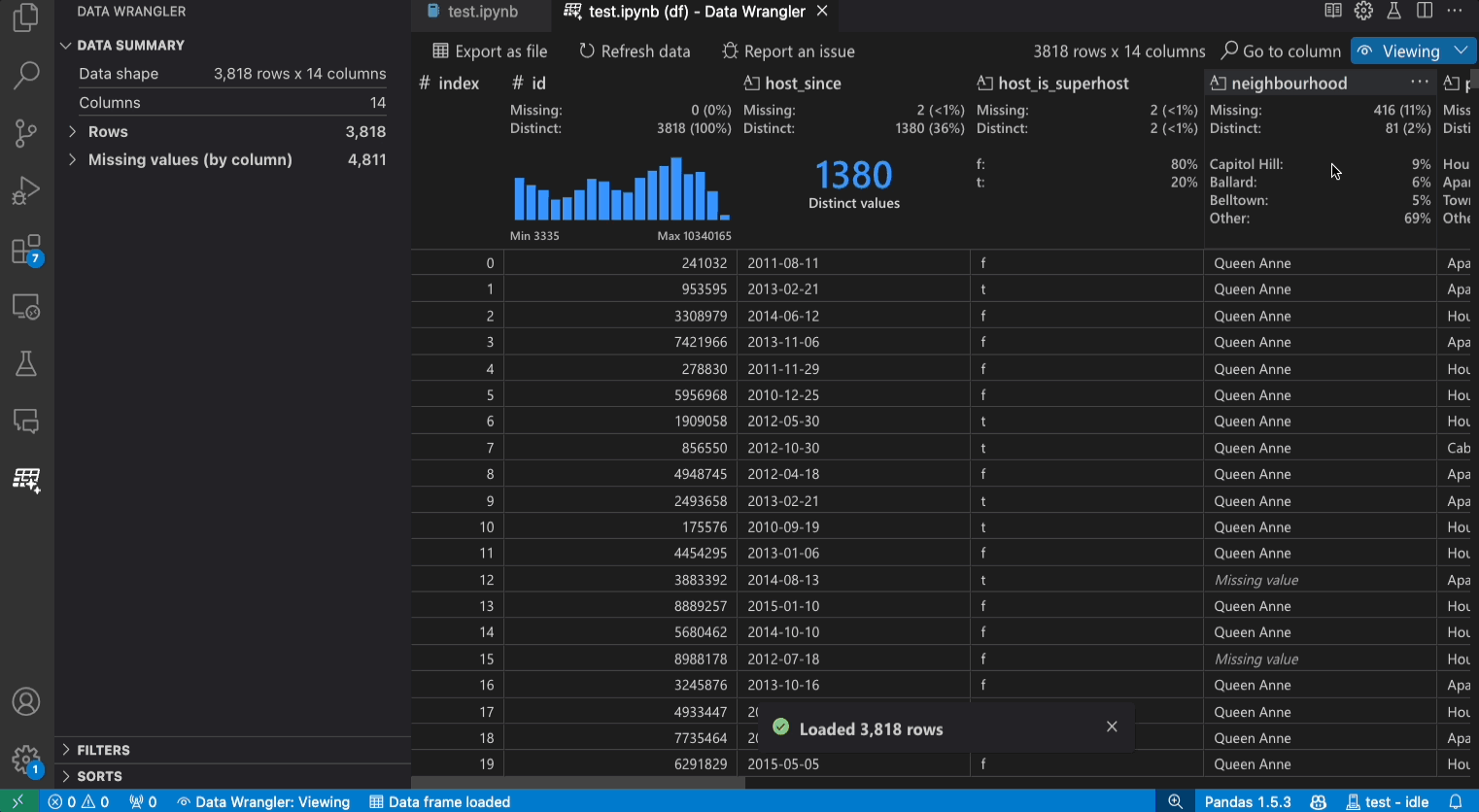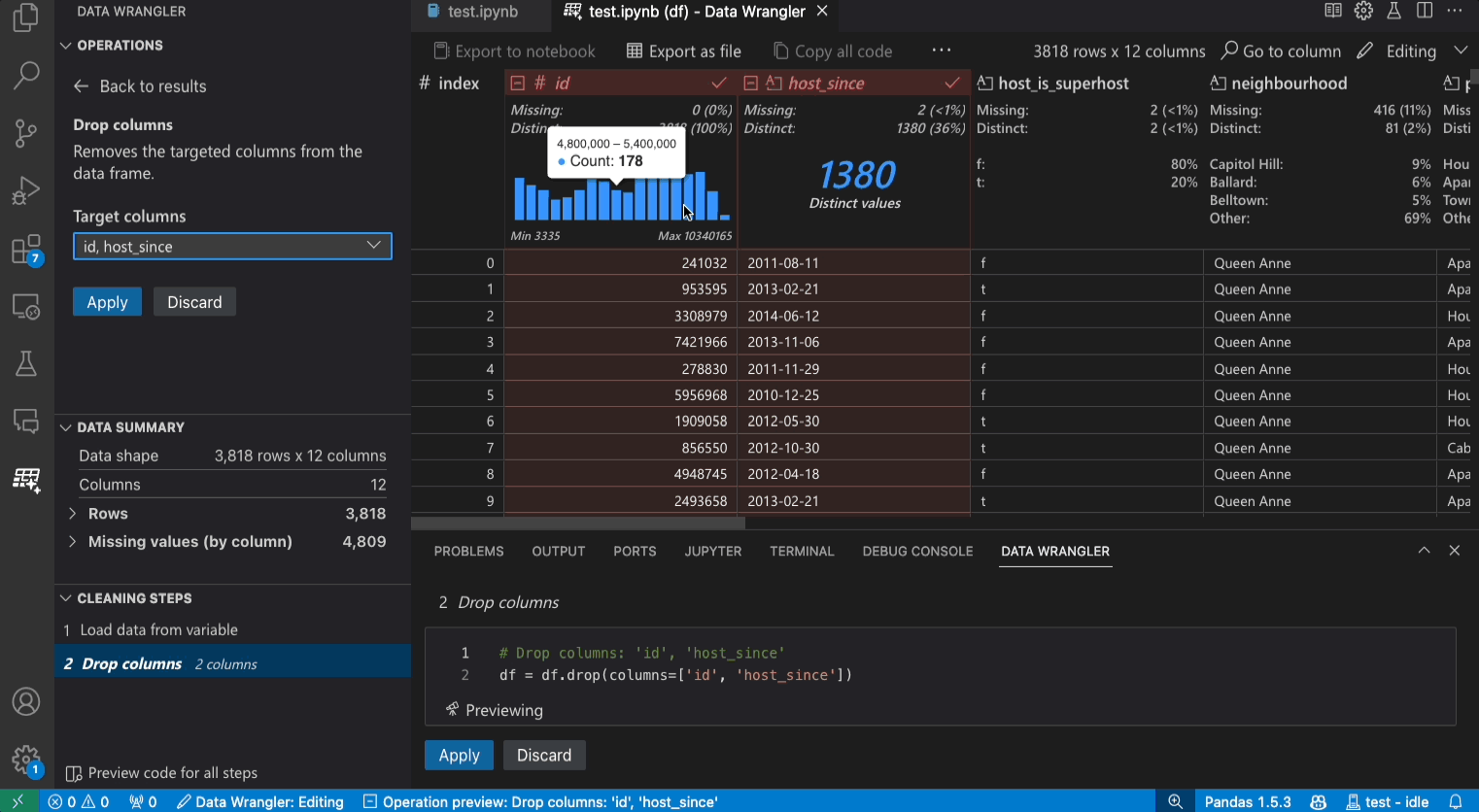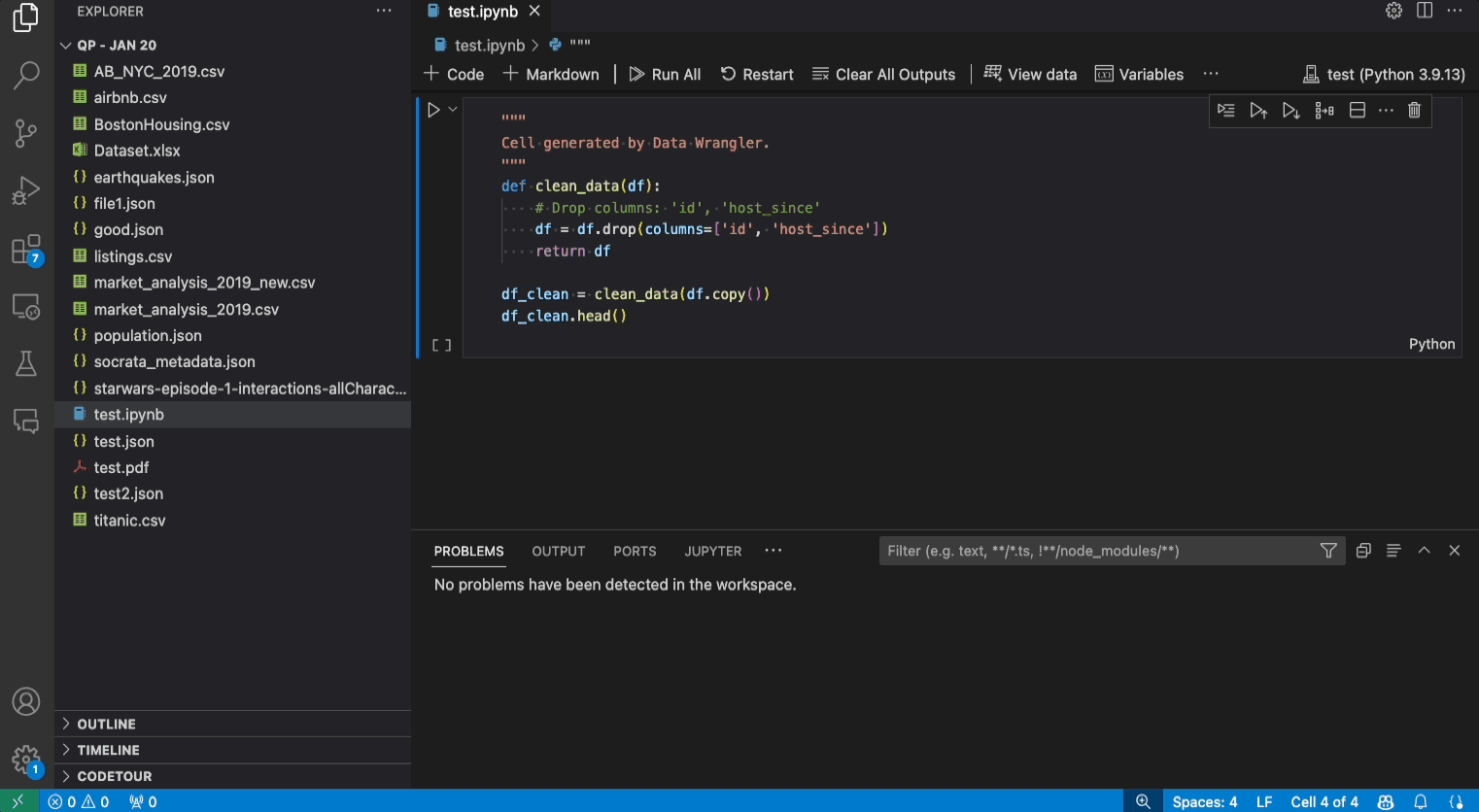
Benutzeroberfläche im Anzeigemodus
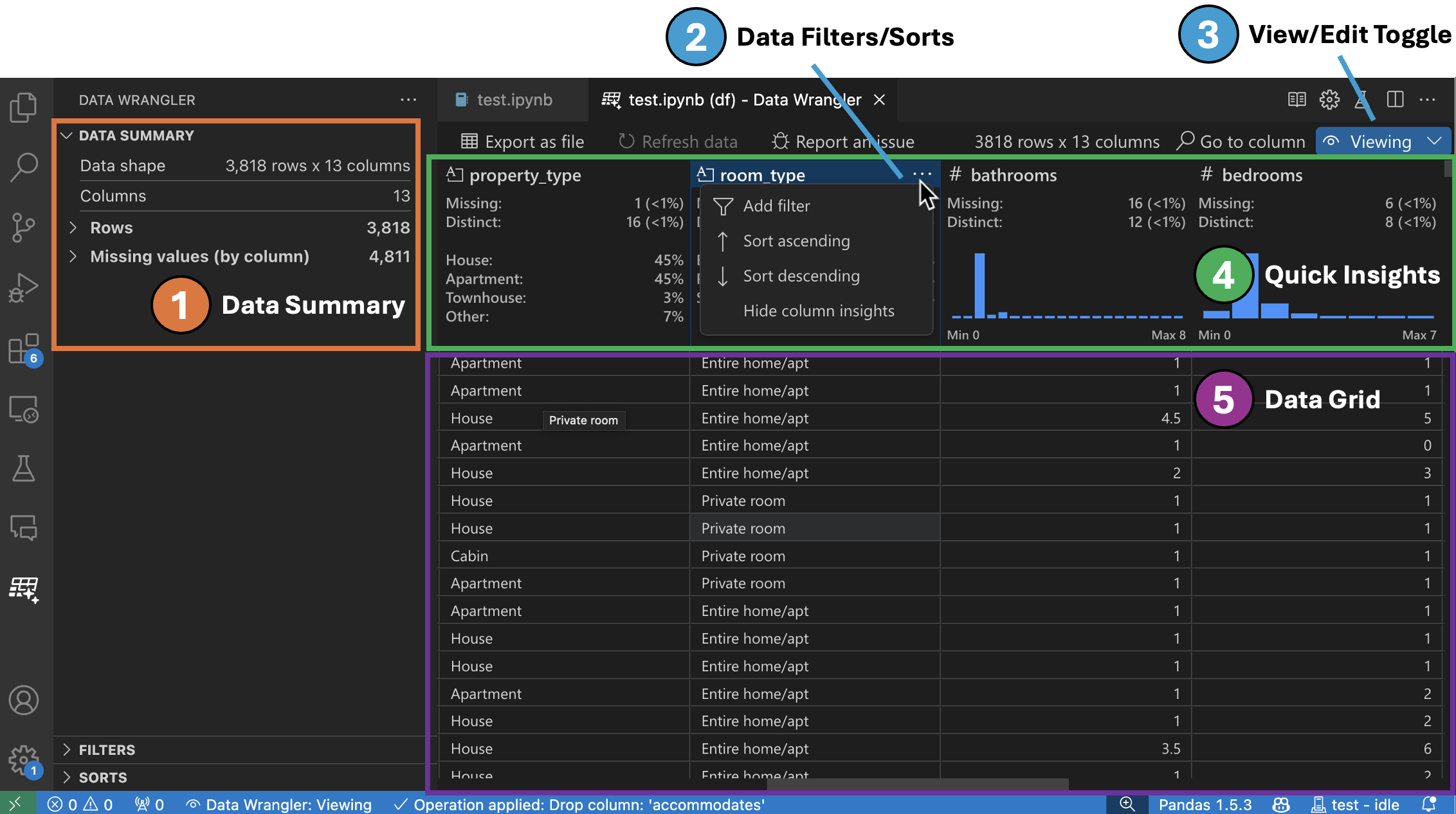
-
Das Panel Datensatzzusammenfassung zeigt detaillierte statistische Zusammenfassungen für Ihren gesamten Datensatz oder eine bestimmte Spalte an, wenn diese ausgewählt ist.
-
Sie können beliebige Datenfilter/Sortierungen auf die Spalte über das Header-Menü der Spalte anwenden.
-
Schalten Sie zwischen dem Anzeige- oder Bearbeitungsmodus von Data Wrangler um, um auf die integrierten Datenoperationen zuzugreifen.
-
Unter der Kopfzeile Schnelle Einblicke können Sie schnell wertvolle Informationen zu jeder Spalte einsehen. Je nach Datentyp der Spalte zeigt der schnelle Einblick die Verteilung der Daten oder die Häufigkeit der Datenpunkte sowie fehlende und eindeutige Werte an.
-
Das Datenraster bietet Ihnen ein scrollbares Fenster, in dem Sie Ihren gesamten Datensatz anzeigen können.
Benutzeroberfläche im Bearbeitungsmodus
Das Umschalten in den Bearbeitungsmodus aktiviert zusätzliche Funktionen und Benutzeroberflächenelemente in Data Wrangler. Im folgenden Screenshot verwenden wir Data Wrangler, um die fehlenden Werte in der letzten Spalte durch den Median dieser Spalte zu ersetzen.
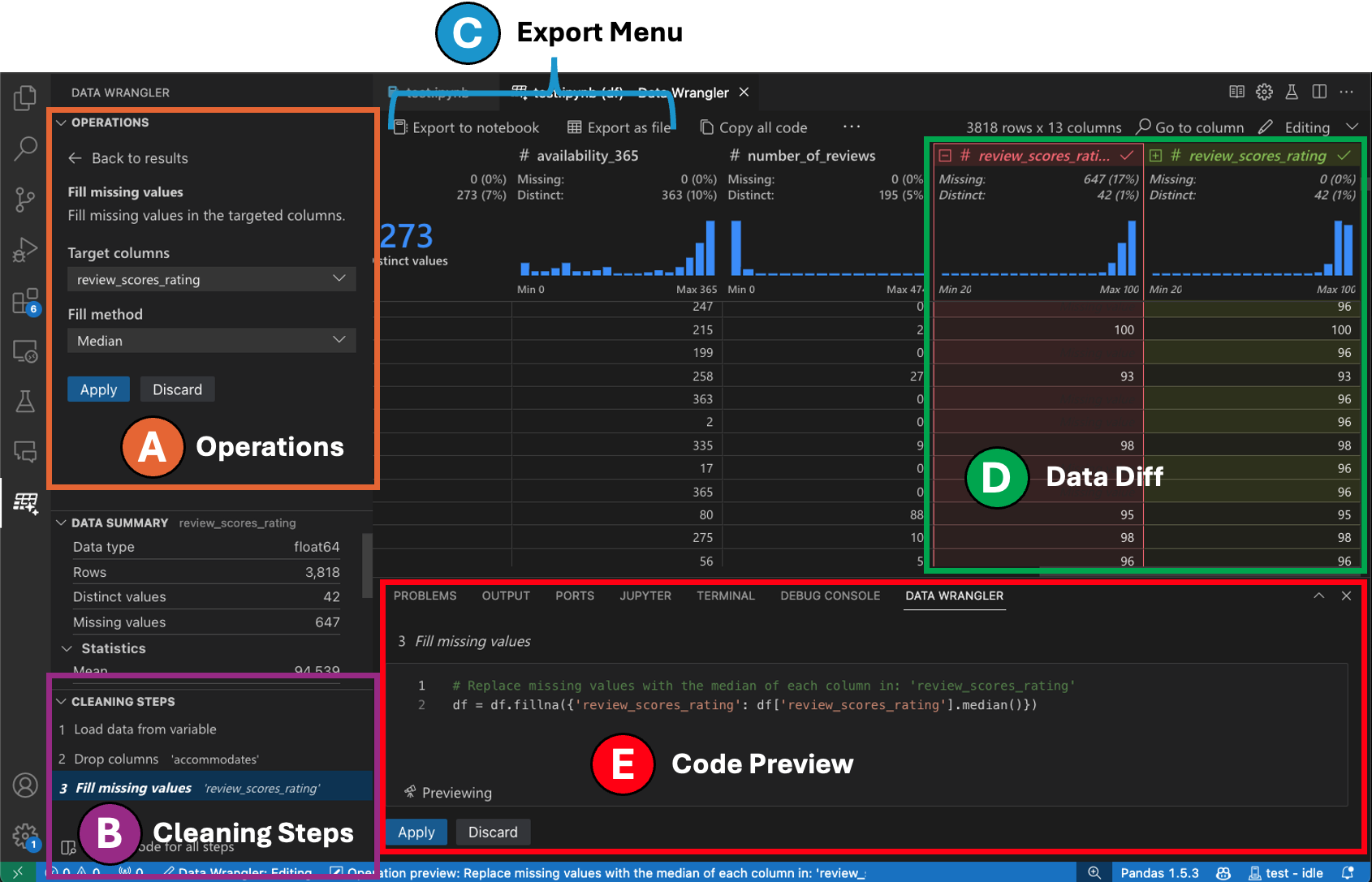
-
Das Panel Operationen ist der Ort, an dem Sie alle integrierten Datenoperationen von Data Wrangler durchsuchen können. Die Operationen sind nach Kategorien organisiert.
-
Das Panel Bereinigungsschritte zeigt eine Liste aller zuvor angewendeten Operationen. Es ermöglicht dem Benutzer, bestimmte Operationen rückgängig zu machen oder die *letzte* Operation zu bearbeiten. Das Auswählen eines Schritts hebt die Änderungen im Datenraster hervor und zeigt den zugehörigen generierten Code für diese Operation an.
-
Das Exportmenü ermöglicht es Ihnen, den Code zurück in ein Jupyter Notebook zu exportieren oder die Daten in eine neue Datei zu exportieren.
-
Wenn Sie eine Operation ausgewählt haben und deren Auswirkungen auf die Daten anzeigen, wird das Raster mit einer Datenunterschied-Ansicht der von Ihnen vorgenommenen Änderungen überlagert.
-
Der Abschnitt Code-Vorschau zeigt den Python- und Pandas-Code, den Data Wrangler bei Auswahl einer Operation generiert hat. Er bleibt leer, wenn keine Operation ausgewählt ist. Sie können den generierten Code bearbeiten, was dazu führt, dass das Datenraster die Auswirkungen auf die Daten hervorhebt.
Beispiel: Fehlende Werte in Ihrem Datensatz ersetzen
Gegeben sei ein Datensatz, eine der üblichen Datenbereinigungsaufgaben ist der Umgang mit fehlenden Werten im Datensatz. Das folgende Beispiel zeigt, wie Data Wrangler verwendet werden kann, um die fehlenden Werte in einer Spalte durch den Medianwert dieser Spalte zu ersetzen. Während die Transformation über die Benutzeroberfläche erfolgt, generiert Data Wrangler auch automatisch den Python- und Pandas-Code, der für den Ersatz fehlender Werte erforderlich ist.
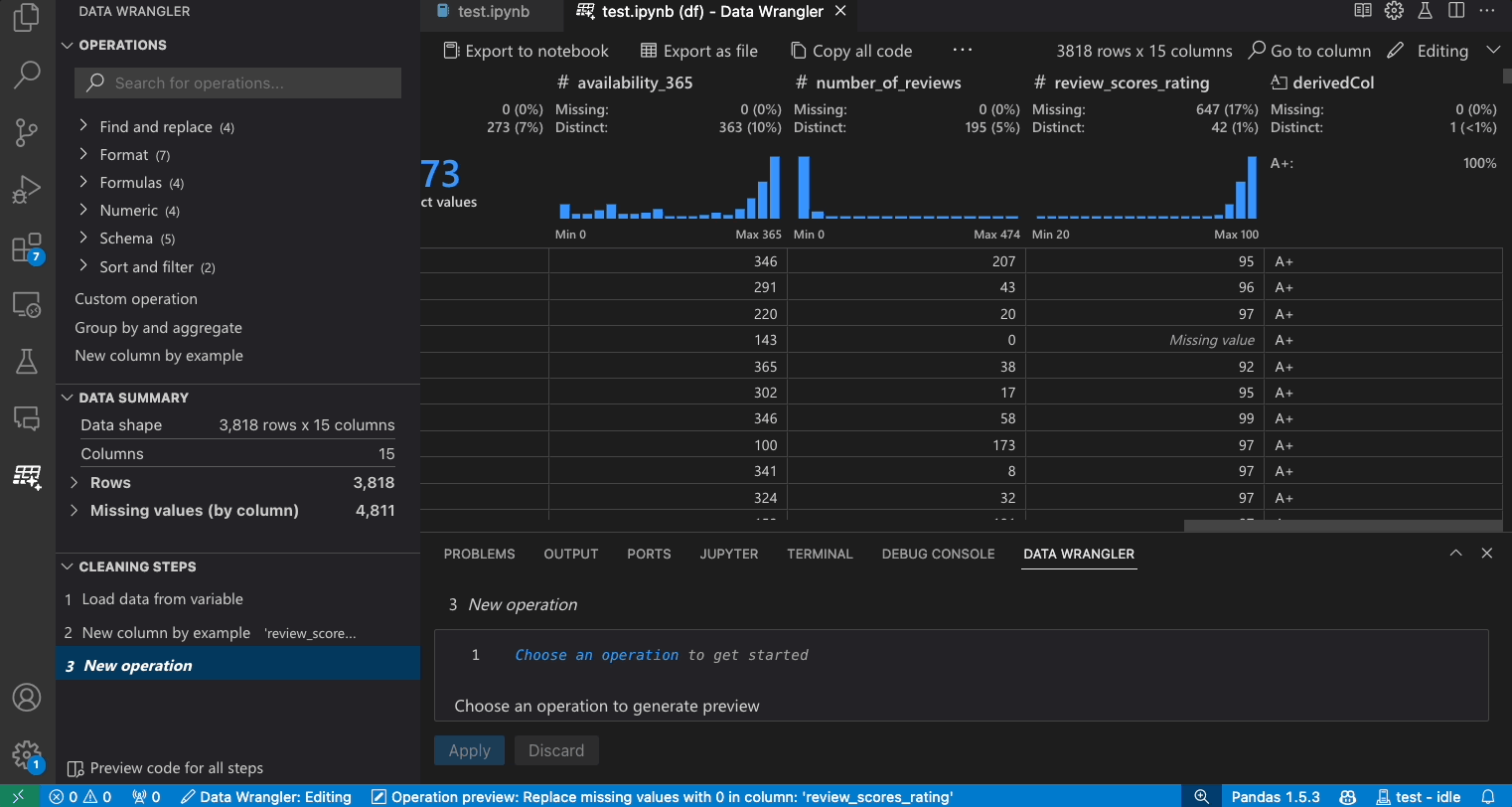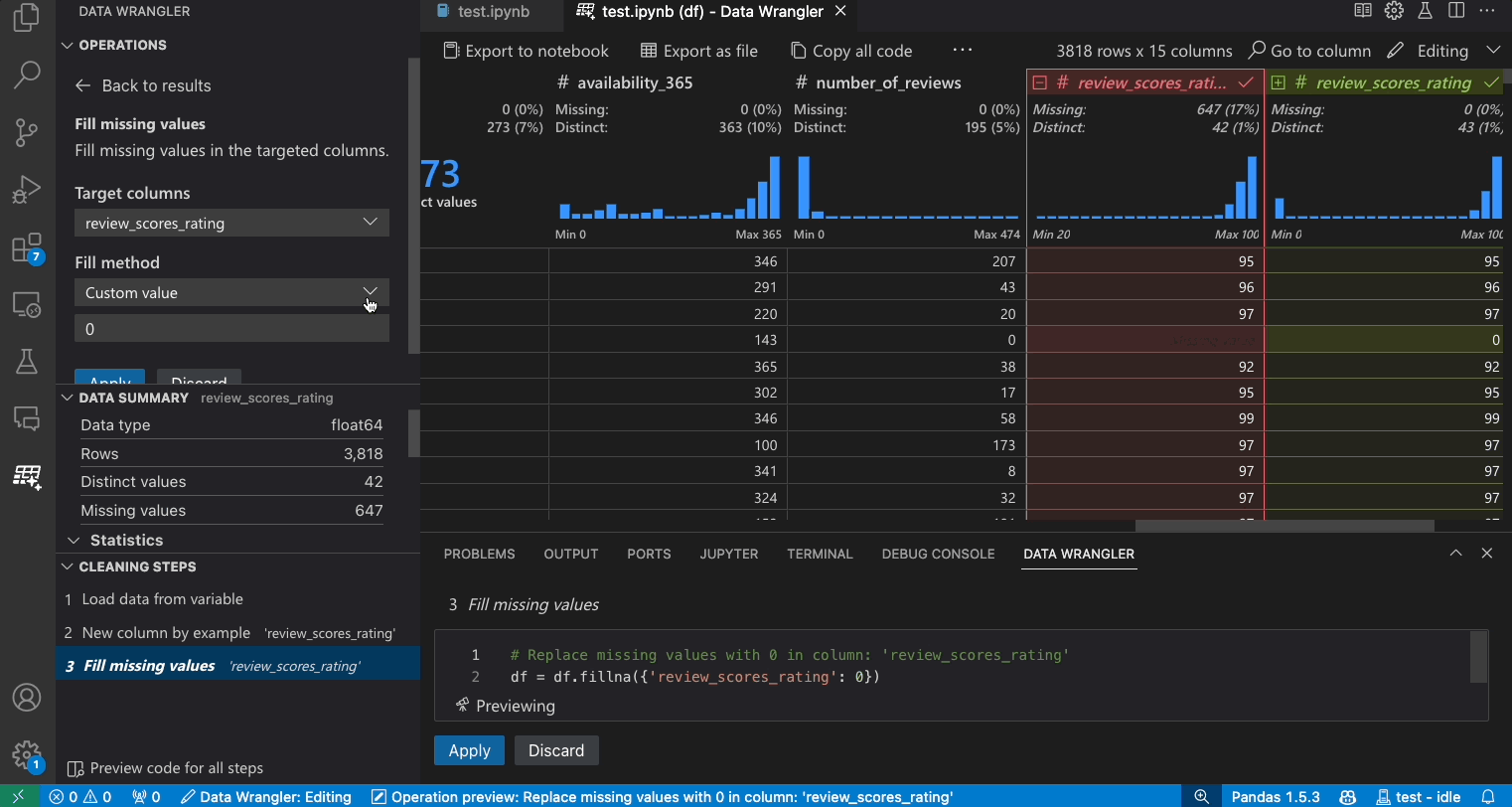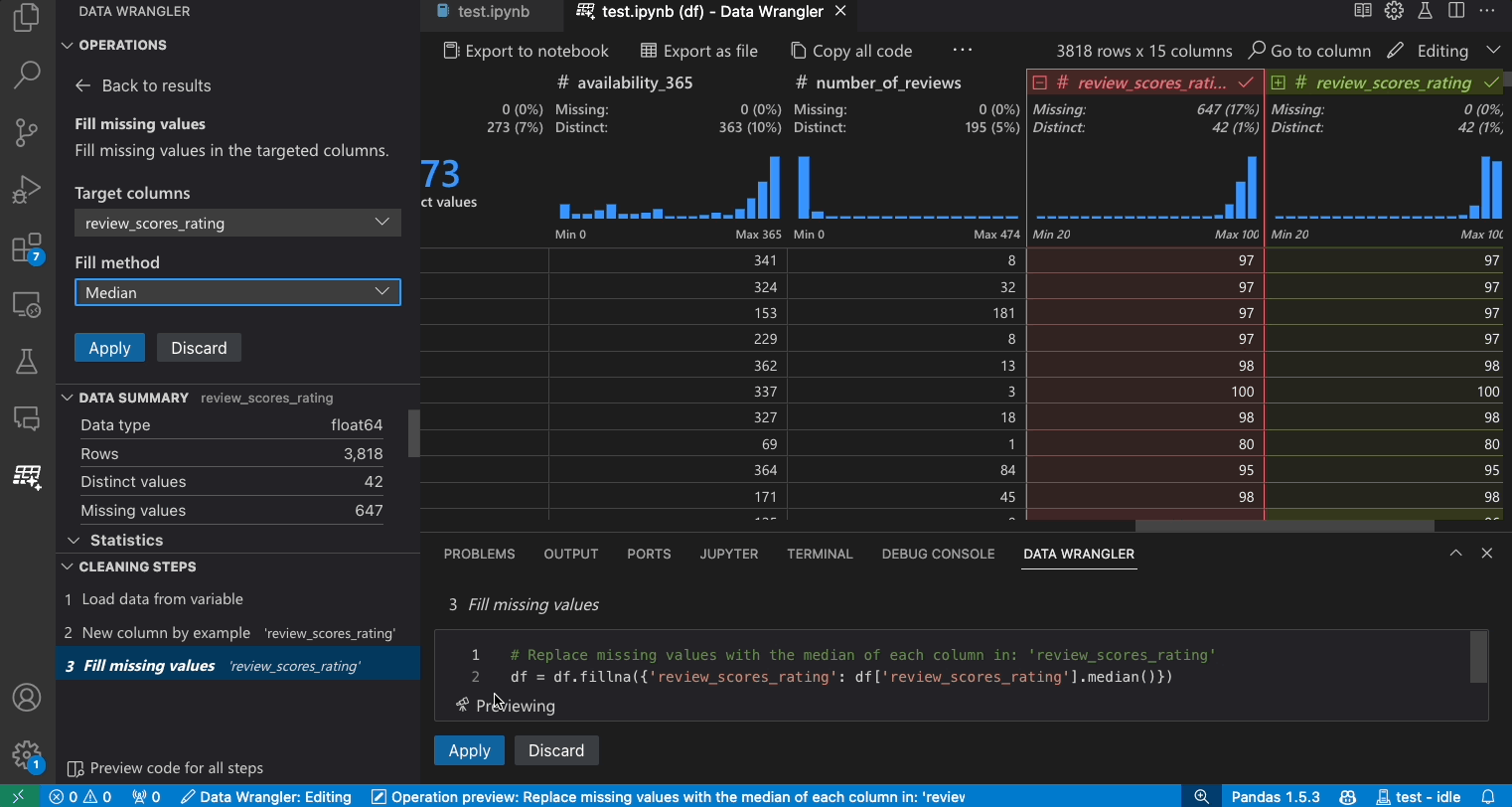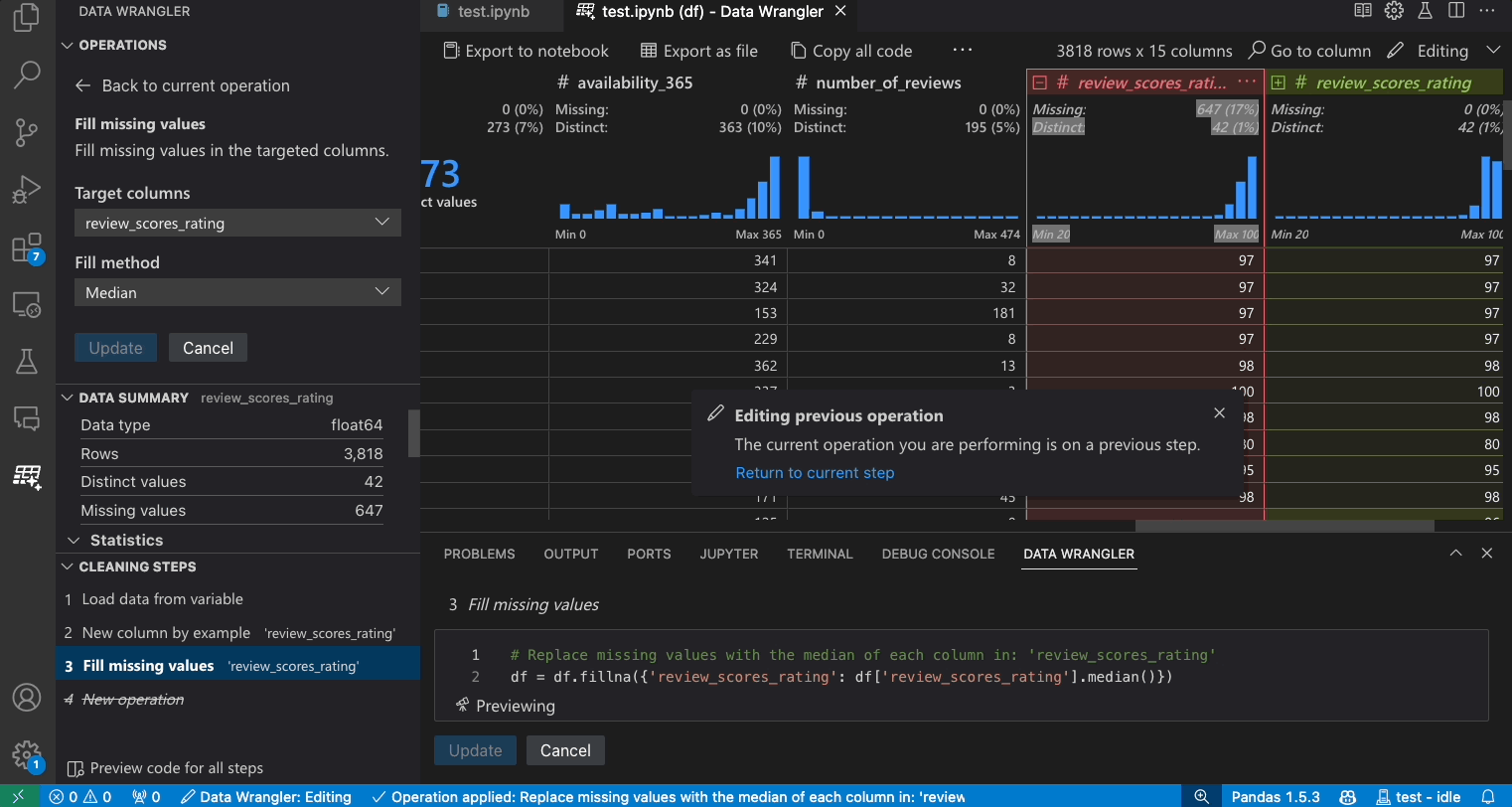
- Suchen Sie im Operationen-Panel nach der Operation Fehlende Werte auffüllen.
- Geben Sie in den Parametern an, womit Sie die fehlenden Werte ersetzen möchten. In diesem Fall werden die fehlenden Werte durch den Medianwert der Spalte ersetzt.
- Überprüfen Sie, ob das Datenraster Ihnen die korrekten Änderungen in der Datenunterschied-Ansicht anzeigt.
- Überprüfen Sie, ob der von Data Wrangler generierte Code Ihren Absichten entspricht.
- Wenden Sie die Operation an und sie wird Ihrer Historie der Bereinigungsschritte hinzugefügt.
Nächste Schritte
Diese Seite behandelte den schnellen Einstieg in Data Wrangler. Die vollständige Dokumentation und ein Tutorial zu Data Wrangler, einschließlich aller integrierten Operationen, die Data Wrangler derzeit unterstützt, finden Sie auf der folgenden Seite.