Data Science in VS Code Tutorial
Dieses Tutorial demonstriert die Verwendung von Visual Studio Code und der Microsoft Python-Erweiterung mit gängigen Data-Science-Bibliotheken zur Erkundung eines einfachen Data-Science-Szenarios. Insbesondere anhand von Passagierdaten der Titanic lernen Sie, wie Sie eine Data-Science-Umgebung einrichten, Daten importieren und bereinigen, ein maschinelles Lernmodell zur Vorhersage des Überlebens auf der Titanic erstellen und die Genauigkeit des generierten Modells bewerten.
Voraussetzungen
Für die Durchführung dieses Tutorials sind die folgenden Installationen erforderlich. Stellen Sie sicher, dass Sie sie installieren, falls noch nicht geschehen.
-
Die Python-Erweiterung für VS Code und die Jupyter-Erweiterung für VS Code aus dem Visual Studio Marketplace. Weitere Details zur Installation von Erweiterungen finden Sie unter Extension Marketplace. Beide Erweiterungen werden von Microsoft veröffentlicht.
-
Miniconda mit neuester Python-Version
Hinweis: Wenn Sie bereits die vollständige Anaconda-Distribution installiert haben, müssen Sie Miniconda nicht installieren. Alternativ können Sie, wenn Sie Anaconda oder Miniconda nicht verwenden möchten, eine virtuelle Python-Umgebung erstellen und die für das Tutorial benötigten Pakete mit pip installieren. Wenn Sie diesen Weg wählen, müssen Sie die folgenden Pakete installieren: pandas, jupyter, seaborn, scikit-learn, keras und tensorflow.
Richten Sie eine Data-Science-Umgebung ein
Visual Studio Code und die Python-Erweiterung bieten einen großartigen Editor für Data-Science-Szenarien. Mit nativer Unterstützung für Jupyter-Notebooks in Kombination mit Anaconda ist der Einstieg einfach. In diesem Abschnitt erstellen Sie einen Arbeitsbereich für das Tutorial, eine Anaconda-Umgebung mit den für das Tutorial benötigten Data-Science-Modulen und ein Jupyter-Notebook, das Sie zum Erstellen eines Modells für maschinelles Lernen verwenden werden.
-
Beginnen Sie mit der Erstellung einer Anaconda-Umgebung für das Data-Science-Tutorial. Öffnen Sie eine Anaconda-Eingabeaufforderung und führen Sie
conda create -n myenv python=3.10 pandas jupyter seaborn scikit-learn keras tensorflowaus, um eine Umgebung namens myenv zu erstellen. Zusätzliche Informationen zum Erstellen und Verwalten von Anaconda-Umgebungen finden Sie in der Anaconda-Dokumentation. -
Erstellen Sie als Nächstes einen Ordner an einem geeigneten Ort, der als VS Code-Arbeitsbereich für das Tutorial dient, und benennen Sie ihn
hello_ds. -
Öffnen Sie den Projektordner in VS Code, indem Sie VS Code starten und den Befehl Datei > Ordner öffnen verwenden. Sie können den Ordner sicher öffnen, da Sie ihn selbst erstellt haben.
-
Sobald VS Code gestartet ist, erstellen Sie das Jupyter-Notebook, das für das Tutorial verwendet wird. Öffnen Sie die Befehlspalette (⇧⌘P (Windows, Linux Ctrl+Shift+P)) und wählen Sie Create: New Jupyter Notebook (Erstellen: Neues Jupyter Notebook).

Hinweis: Alternativ können Sie im VS Code-Datei-Explorer das Symbol "Neue Datei" verwenden, um eine Notebook-Datei namens
hello.ipynbzu erstellen. -
Speichern Sie die Datei als
hello.ipynbmit Datei > Speichern unter.... -
Nachdem Ihre Datei erstellt wurde, sollten Sie das geöffnete Jupyter-Notebook im Notebook-Editor sehen. Zusätzliche Informationen zur nativen Jupyter-Notebook-Unterstützung finden Sie im Thema Jupyter Notebooks.
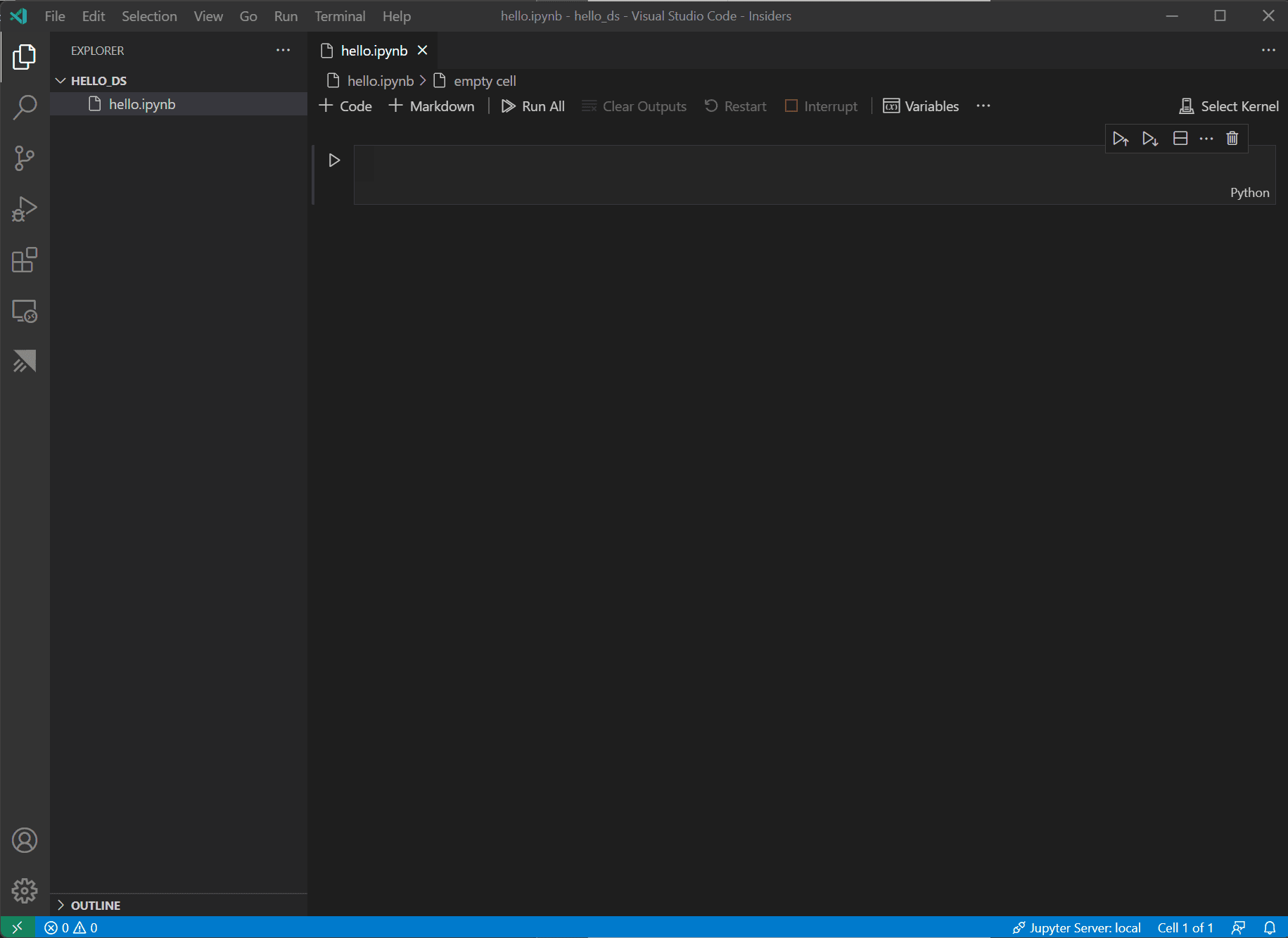
-
Wählen Sie nun oben rechts im Notebook Kernel auswählen.

-
Wählen Sie die oben erstellte Python-Umgebung aus, in der Ihr Kernel ausgeführt werden soll.
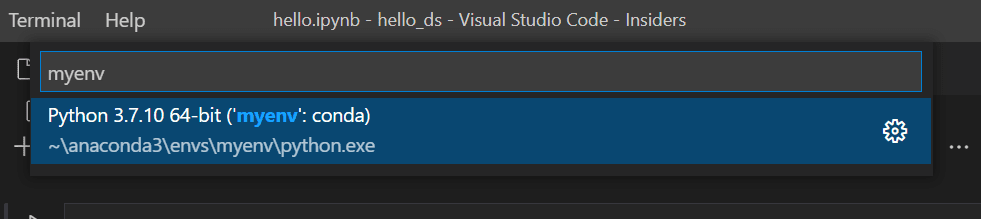
-
Um Ihre Umgebung über das integrierte Terminal von VS Code zu verwalten, öffnen Sie es mit (⌃` (Windows, Linux Ctrl+`)). Wenn Ihre Umgebung nicht aktiviert ist, können Sie dies wie in Ihrem Terminal tun (
conda activate myenv).
Bereiten Sie die Daten vor
Dieses Tutorial verwendet den Titanic-Datensatz, der auf OpenML.org verfügbar ist und von der Abteilung für Biostatistik der Vanderbilt University unter https://hbiostat.org/data bezogen wird. Die Titanic-Daten enthalten Informationen über das Überleben von Passagieren auf der Titanic und Merkmale der Passagiere wie Alter und Ticketklasse. Anhand dieser Daten wird in diesem Tutorial ein Modell zur Vorhersage etabliert, ob ein bestimmter Passagier den Untergang der Titanic überlebt hätte. Dieser Abschnitt zeigt, wie Daten in Ihrem Jupyter-Notebook geladen und manipuliert werden.
-
Laden Sie zunächst die Titanic-Daten von hbiostat.org als CSV-Datei (Download-Links oben rechts) mit dem Namen
titanic3.csvherunter und speichern Sie sie im Ordnerhello_ds, den Sie im vorherigen Abschnitt erstellt haben. -
Wenn Sie die Datei noch nicht in VS Code geöffnet haben, öffnen Sie den Ordner
hello_dsund das Jupyter-Notebook (hello.ipynb), indem Sie zu Datei > Ordner öffnen gehen. -
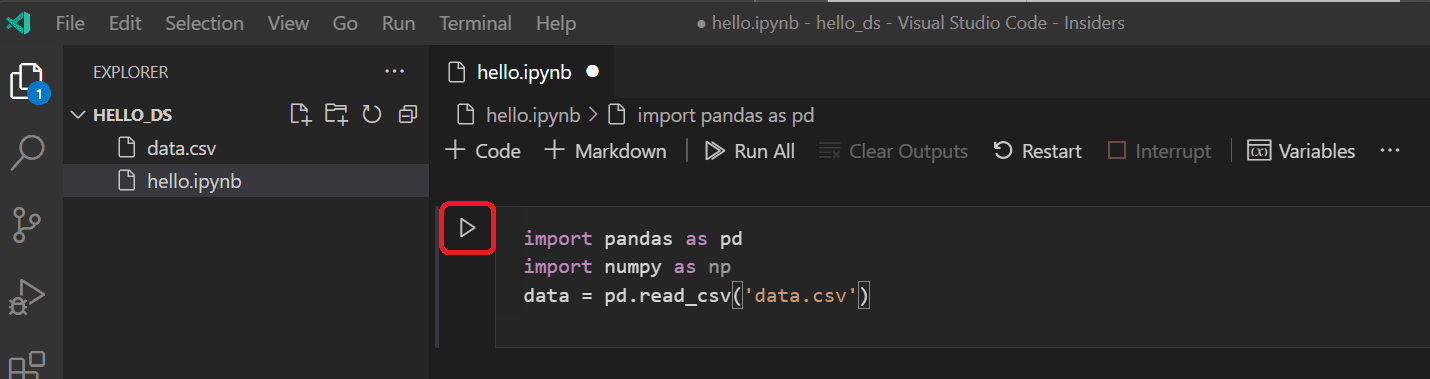
Importieren Sie in Ihrem Jupyter-Notebook zunächst die Bibliotheken pandas und numpy, zwei gängige Bibliotheken zur Datenmanipulation, und laden Sie die Titanic-Daten in einen pandas DataFrame. Kopieren Sie dazu den folgenden Code in die erste Zelle des Notebooks. Weitere Anleitungen zur Arbeit mit Jupyter-Notebooks in VS Code finden Sie in der Dokumentation Arbeiten mit Jupyter-Notebooks.
import pandas as pd import numpy as np data = pd.read_csv('titanic3.csv') -
Führen Sie nun die Zelle mit dem Symbol "Zelle ausführen" oder der Tastenkombination Umschalttaste+Eingabe aus.
-
Nachdem die Zelle ausgeführt wurde, können Sie die geladenen Daten mithilfe des Variablen-Explorers und des Daten-Viewers anzeigen. Wählen Sie zunächst das Symbol Variablen in der oberen Symbolleiste des Notebooks.
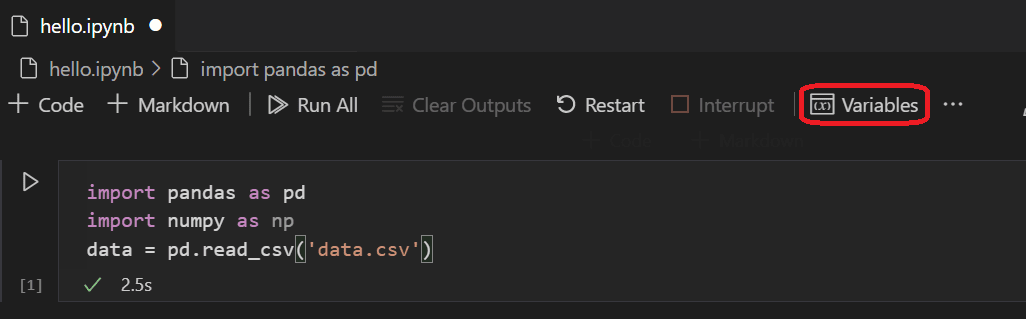
-
Unten in VS Code öffnet sich ein Bereich JUPYTER: VARIABLEN. Er enthält eine Liste der bisher in Ihrem laufenden Kernel definierten Variablen.
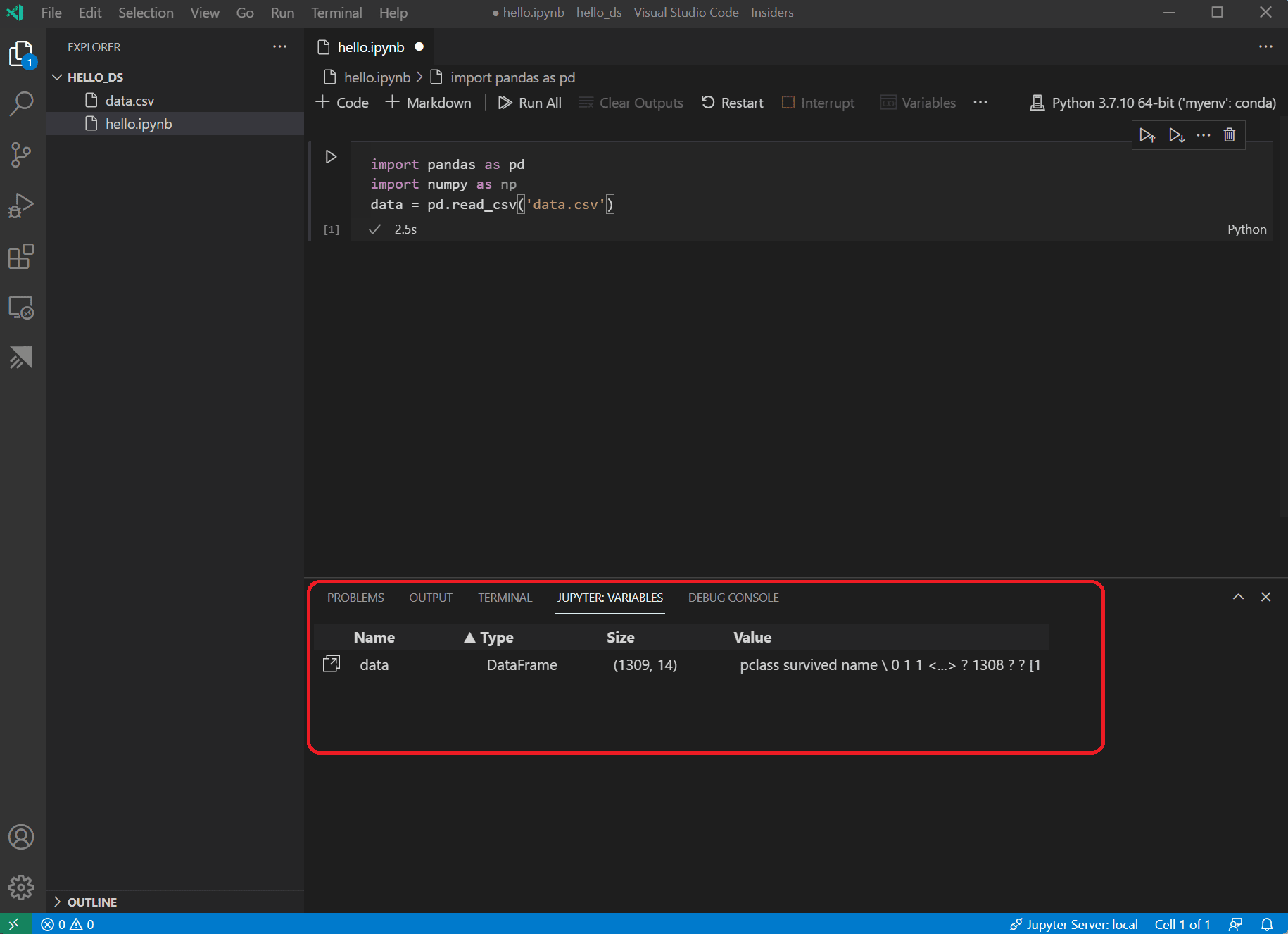
-
Um die Daten im zuvor geladenen Pandas DataFrame anzuzeigen, wählen Sie das Symbol "Daten-Viewer" links neben der Variable
data.
-
Verwenden Sie den Daten-Viewer, um die Zeilen der Daten anzuzeigen, zu sortieren und zu filtern. Nachdem Sie die Daten überprüft haben, kann es hilfreich sein, einige Aspekte davon zu grafisch darzustellen, um die Beziehungen zwischen den verschiedenen Variablen zu visualisieren.
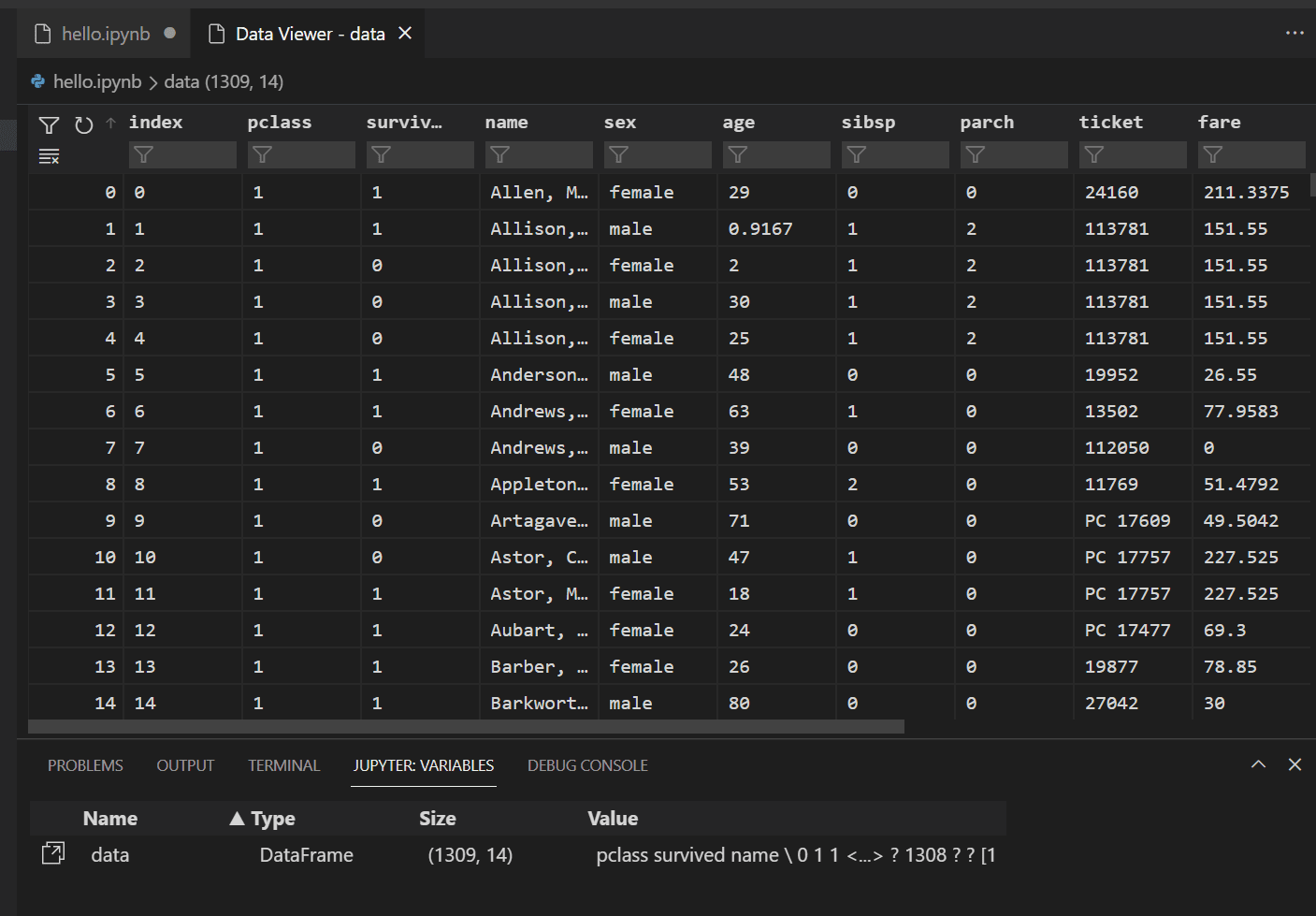
Alternativ können Sie die Datenansicht nutzen, die von anderen Erweiterungen wie Data Wrangler angeboten wird. Die Data Wrangler-Erweiterung bietet eine reichhaltige Benutzeroberfläche, um Einblicke in Ihre Daten zu erhalten und hilft Ihnen bei der Datenprofilierung, Qualitätsprüfungen, Transformationen und mehr. Erfahren Sie mehr über die Data Wrangler-Erweiterung in unserer Dokumentation.
-
Bevor die Daten grafisch dargestellt werden können, müssen Sie sicherstellen, dass keine Probleme damit bestehen. Wenn Sie sich die Titanic-CSV-Datei ansehen, werden Sie feststellen, dass ein Fragezeichen ("?") verwendet wurde, um Zellen zu identifizieren, in denen keine Daten verfügbar waren.
Pandas kann diesen Wert zwar in einen DataFrame einlesen, aber das Ergebnis für eine Spalte wie age ist, dass ihr Datentyp auf object anstatt auf einen numerischen Datentyp gesetzt wird, was für die grafische Darstellung problematisch ist.
Dieses Problem kann behoben werden, indem das Fragezeichen durch einen fehlenden Wert ersetzt wird, den pandas verstehen kann. Fügen Sie den folgenden Code zur nächsten Zelle in Ihrem Notebook hinzu, um die Fragezeichen in den Spalten age und fare durch den numpy NaN-Wert zu ersetzen. Beachten Sie, dass wir auch den Datentyp der Spalte nach dem Ersetzen der Werte aktualisieren müssen.
Tipp: Um eine neue Zelle hinzuzufügen, können Sie das Symbol "Zelle einfügen" verwenden, das sich in der unteren linken Ecke einer vorhandenen Zelle befindet. Alternativ können Sie auch die Taste Esc drücken, um in den Befehlsmodus zu wechseln, gefolgt von der Taste B.
data.replace('?', np.nan, inplace= True) data = data.astype({"age": np.float64, "fare": np.float64})Hinweis: Wenn Sie jemals den für eine Spalte verwendeten Datentyp sehen müssen, können Sie das Attribut DataFrame dtypes verwenden.
-
Nachdem die Daten nun in gutem Zustand sind, können Sie seaborn und matplotlib verwenden, um zu sehen, wie bestimmte Spalten des Datensatzes mit der Überlebensrate zusammenhängen. Fügen Sie den folgenden Code zur nächsten Zelle in Ihrem Notebook hinzu und führen Sie ihn aus, um die generierten Diagramme anzuzeigen.
import seaborn as sns import matplotlib.pyplot as plt fig, axs = plt.subplots(ncols=5, figsize=(30,5)) sns.violinplot(x="survived", y="age", hue="sex", data=data, ax=axs[0]) sns.pointplot(x="sibsp", y="survived", hue="sex", data=data, ax=axs[1]) sns.pointplot(x="parch", y="survived", hue="sex", data=data, ax=axs[2]) sns.pointplot(x="pclass", y="survived", hue="sex", data=data, ax=axs[3]) sns.violinplot(x="survived", y="fare", hue="sex", data=data, ax=axs[4])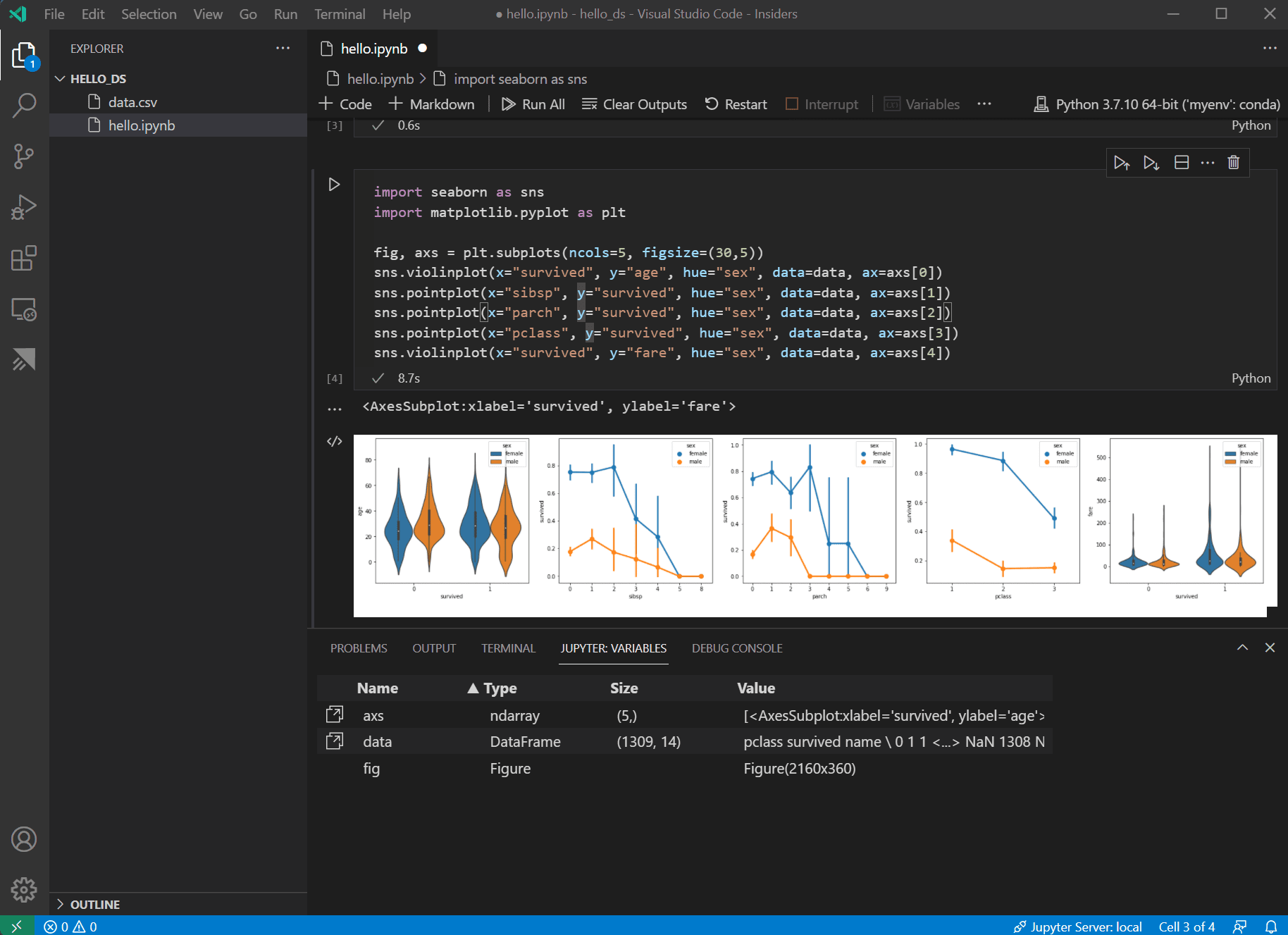
Tipp: Um Ihren Graphen schnell zu kopieren, können Sie mit der Maus über die obere rechte Ecke Ihres Graphen fahren und auf die Schaltfläche In die Zwischenablage kopieren klicken, die erscheint. Sie können auch Details Ihres Graphen besser anzeigen, indem Sie auf die Schaltfläche Bild erweitern klicken.

-
Diese Diagramme sind hilfreich, um einige der Beziehungen zwischen dem Überleben und den Eingabevariablen der Daten zu erkennen, aber es ist auch möglich, mit pandas Korrelationen zu berechnen. Dazu müssen alle verwendeten Variablen numerisch sein, damit die Korrelationsberechnung durchgeführt werden kann, und derzeit ist das Geschlecht als Zeichenkette gespeichert. Um diese Zeichenkettenwerte in Ganzzahlen umzuwandeln, fügen Sie den folgenden Code hinzu und führen Sie ihn aus.
data.replace({'male': 1, 'female': 0}, inplace=True) -
Nun können Sie die Korrelation zwischen allen Eingabevariablen analysieren, um die Merkmale zu identifizieren, die die besten Eingaben für ein Modell für maschinelles Lernen wären. Je näher ein Wert an 1 liegt, desto höher ist die Korrelation zwischen dem Wert und dem Ergebnis. Verwenden Sie den folgenden Code, um die Beziehung zwischen allen Variablen und dem Überleben zu korrelieren.
data.corr(numeric_only=True).abs()[["survived"]]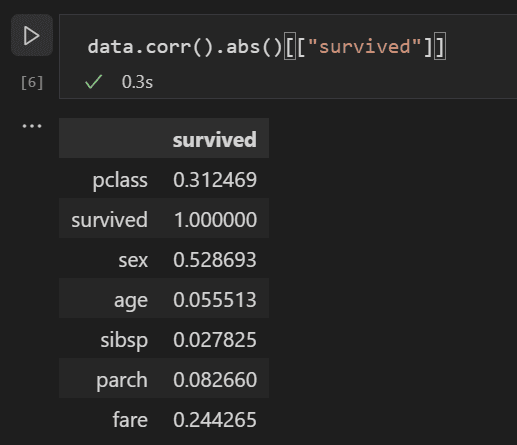
-
Wenn Sie die Korrelationsergebnisse betrachten, werden Sie feststellen, dass einige Variablen wie das Geschlecht eine ziemlich hohe Korrelation zum Überleben aufweisen, während andere wie Verwandte (sibsp = Geschwister oder Ehepartner, parch = Eltern oder Kinder) scheinbar wenig Korrelation aufweisen.
Hypothetisieren wir, dass sibsp und parch in ihrer Auswirkung auf die Überlebensrate zusammenhängen und gruppieren wir sie in einer neuen Spalte namens "relatives", um zu sehen, ob die Kombination davon eine höhere Korrelation mit der Überlebensrate aufweist. Dazu prüfen wir, ob für einen bestimmten Passagier die Anzahl von sibsp und parch größer als 0 ist, und wenn ja, können wir dann sagen, dass sie einen Verwandten an Bord hatten.
Verwenden Sie den folgenden Code, um eine neue Variable und Spalte im Datensatz namens
relativeszu erstellen und die Korrelation erneut zu überprüfen.data['relatives'] = data.apply (lambda row: int((row['sibsp'] + row['parch']) > 0), axis=1) data.corr(numeric_only=True).abs()[["survived"]]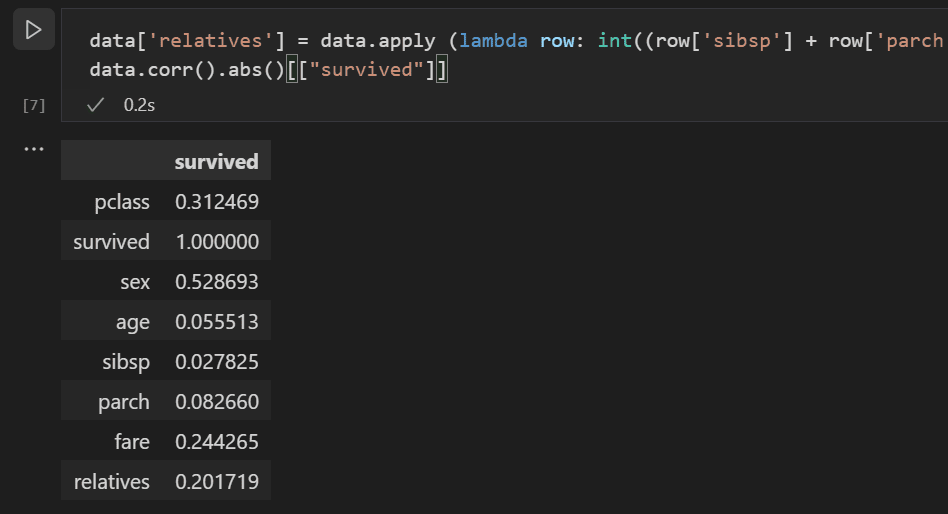
-
Sie werden feststellen, dass, wenn man die Anzahl der Verwandten betrachtet, tatsächlich eine höhere Korrelation mit dem Überleben besteht, als ob eine Person Verwandte hatte. Mit diesen Informationen können Sie nun die Spalten sibsp und parch mit geringem Wert sowie alle Zeilen mit NaN-Werten aus dem Datensatz entfernen, um einen Datensatz zu erhalten, der für das Training eines Modells verwendet werden kann.
data = data[['sex', 'pclass','age','relatives','fare','survived']].dropna()Hinweis: Obwohl das Alter eine geringe direkte Korrelation aufwies, wurde es beibehalten, da es sinnvoll erscheint, dass es in Verbindung mit anderen Eingaben immer noch eine Korrelation aufweisen könnte.
Trainieren und evaluieren Sie ein Modell
Mit dem vorbereiteten Datensatz können Sie nun mit der Erstellung eines Modells beginnen. Für diesen Abschnitt verwenden Sie die Bibliothek scikit-learn (da sie einige nützliche Hilfsfunktionen bietet), um den Datensatz vorzuverarbeiten, ein Klassifizierungsmodell zur Ermittlung der Überlebensrate auf der Titanic zu trainieren und dieses Modell dann mit Testdaten zu verwenden, um seine Genauigkeit zu ermitteln.
-
Ein üblicher erster Schritt beim Trainieren eines Modells ist die Aufteilung des Datensatzes in Trainings- und Validierungsdaten. Dies ermöglicht es Ihnen, einen Teil der Daten zum Trainieren des Modells und einen Teil der Daten zum Testen des Modells zu verwenden. Wenn Sie alle Ihre Daten zum Trainieren des Modells verwenden würden, hätten Sie keine Möglichkeit, abzuschätzen, wie gut es tatsächlich mit Daten abschneiden würde, die das Modell noch nicht gesehen hat. Ein Vorteil der scikit-learn-Bibliothek ist, dass sie eine spezielle Methode zum Aufteilen eines Datensatzes in Trainings- und Testdaten bietet.
Fügen Sie eine Zelle mit dem folgenden Code zum Notebook hinzu und führen Sie sie aus, um die Daten aufzuteilen.
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(data[['sex','pclass','age','relatives','fare']], data.survived, test_size=0.2, random_state=0) -
Als Nächstes werden die Eingaben normalisiert, sodass alle Merkmale gleich behandelt werden. Innerhalb des Datensatzes reichen die Werte für das Alter beispielsweise von ca. 0-100, während das Geschlecht nur 1 oder 0 ist. Durch die Normalisierung aller Variablen stellen Sie sicher, dass die Wertebereiche gleich sind. Verwenden Sie den folgenden Code in einer neuen Codezelle, um die Eingabewerte zu skalieren.
from sklearn.preprocessing import StandardScaler sc = StandardScaler() X_train = sc.fit_transform(x_train) X_test = sc.transform(x_test) -
Es gibt viele verschiedene Algorithmen für maschinelles Lernen, aus denen Sie zur Modellierung der Daten wählen können. Die scikit-learn-Bibliothek bietet ebenfalls Unterstützung für viele davon und eine Tabelle, die Ihnen bei der Auswahl des richtigen für Ihr Szenario hilft. Verwenden Sie vorerst den Naïve Bayes-Algorithmus, einen gängigen Algorithmus für Klassifizierungsprobleme. Fügen Sie eine Zelle mit dem folgenden Code hinzu, um den Algorithmus zu erstellen und zu trainieren.
from sklearn.naive_bayes import GaussianNB model = GaussianNB() model.fit(X_train, y_train) -
Mit einem trainierten Modell können Sie es nun gegen den Testdatensatz testen, der vom Training zurückgehalten wurde. Fügen Sie den folgenden Code hinzu, führen Sie ihn aus, um das Ergebnis der Testdaten vorherzusagen und die Genauigkeit des Modells zu berechnen.
from sklearn import metrics predict_test = model.predict(X_test) print(metrics.accuracy_score(y_test, predict_test))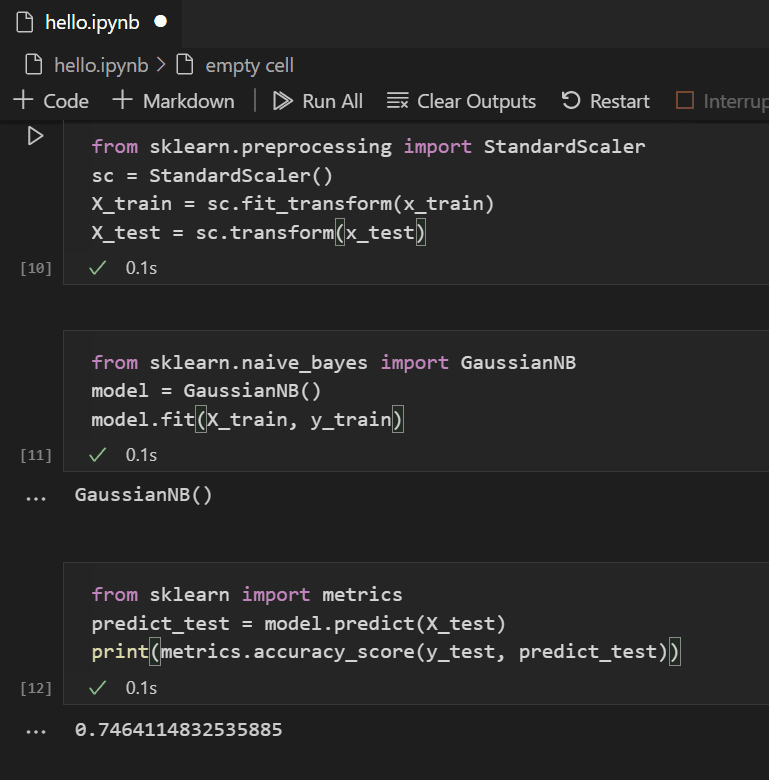
Wenn Sie das Ergebnis der Testdaten betrachten, werden Sie feststellen, dass der trainierte Algorithmus eine Erfolgsquote von ~75 % bei der Schätzung des Überlebens hatte.
(Optional) Verwenden Sie ein neuronales Netz
Ein neuronales Netz ist ein Modell, das Gewichte und Aktivierungsfunktionen verwendet und Aspekte menschlicher Neuronen modelliert, um basierend auf gegebenen Eingaben ein Ergebnis zu ermitteln. Im Gegensatz zu den zuvor betrachteten Algorithmen für maschinelles Lernen sind neuronale Netze eine Form des Deep Learning, bei der Sie keinen idealen Algorithmus für Ihr Problem im Voraus kennen müssen. Sie können für viele verschiedene Szenarien verwendet werden, und Klassifizierung ist eines davon. In diesem Abschnitt verwenden Sie die Bibliothek Keras mit TensorFlow, um das neuronale Netz zu konstruieren und zu untersuchen, wie es mit dem Titanic-Datensatz umgeht.
-
Der erste Schritt ist der Import der erforderlichen Bibliotheken und die Erstellung des Modells. In diesem Fall verwenden Sie ein sequenzielles neuronales Netz, das ein geschichtetes neuronales Netz ist, bei dem mehrere Schichten nacheinander ineinander übergehen.
from keras.models import Sequential from keras.layers import Dense model = Sequential() -
Nachdem das Modell definiert ist, besteht der nächste Schritt darin, die Schichten des neuronalen Netzes hinzuzufügen. Fürs Erste halten wir die Dinge einfach und verwenden nur drei Schichten. Fügen Sie den folgenden Code hinzu, um die Schichten des neuronalen Netzes zu erstellen.
model.add(Dense(5, kernel_initializer = 'uniform', activation = 'relu', input_dim = 5)) model.add(Dense(5, kernel_initializer = 'uniform', activation = 'relu')) model.add(Dense(1, kernel_initializer = 'uniform', activation = 'sigmoid'))- Die erste Schicht wird auf eine Dimension von 5 gesetzt, da Sie fünf Eingaben haben: Geschlecht, Ticketklasse, Alter, Verwandte und Fahrpreis.
- Die letzte Schicht muss 1 ausgeben, da Sie eine eindimensionale Ausgabe wünschen, die angibt, ob ein Passagier überleben würde.
- Die mittlere Schicht wurde zur Vereinfachung bei 5 belassen, obwohl dieser Wert auch anders hätte sein können.
Die ReLU-Aktivierungsfunktion (Rectified Linear Unit) wird als gute allgemeine Aktivierungsfunktion für die ersten beiden Schichten verwendet, während die Sigmoid-Aktivierungsfunktion für die letzte Schicht erforderlich ist, da die gewünschte Ausgabe (ob ein Passagier überlebt oder nicht) im Bereich von 0-1 (die Wahrscheinlichkeit, dass ein Passagier überlebt) skaliert werden muss.
Mit dieser Codezeile können Sie sich auch die Zusammenfassung des erstellten Modells ansehen.
model.summary()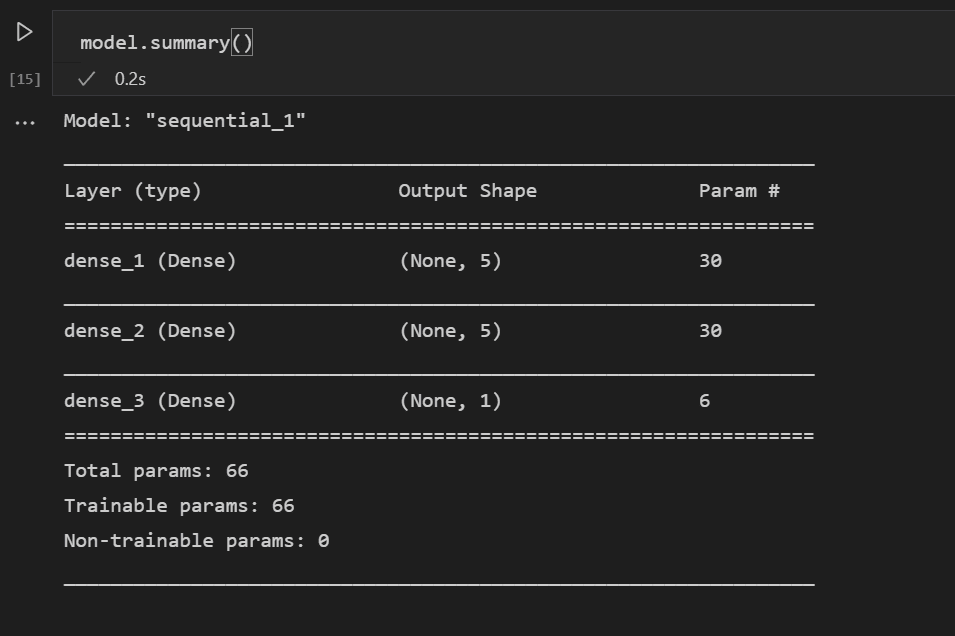
-
Nachdem das Modell erstellt wurde, muss es kompiliert werden. Dazu müssen Sie definieren, welcher Optimierer verwendet wird, wie der Verlust berechnet wird und welche Metrik optimiert werden soll. Fügen Sie den folgenden Code hinzu, um das Modell zu erstellen und zu trainieren. Sie werden feststellen, dass die Genauigkeit nach dem Training ~61 % beträgt.
Hinweis: Dieser Schritt kann je nach Rechner von einigen Sekunden bis zu einigen Minuten dauern.
model.compile(optimizer="adam", loss='binary_crossentropy', metrics=['accuracy']) model.fit(X_train, y_train, batch_size=32, epochs=50)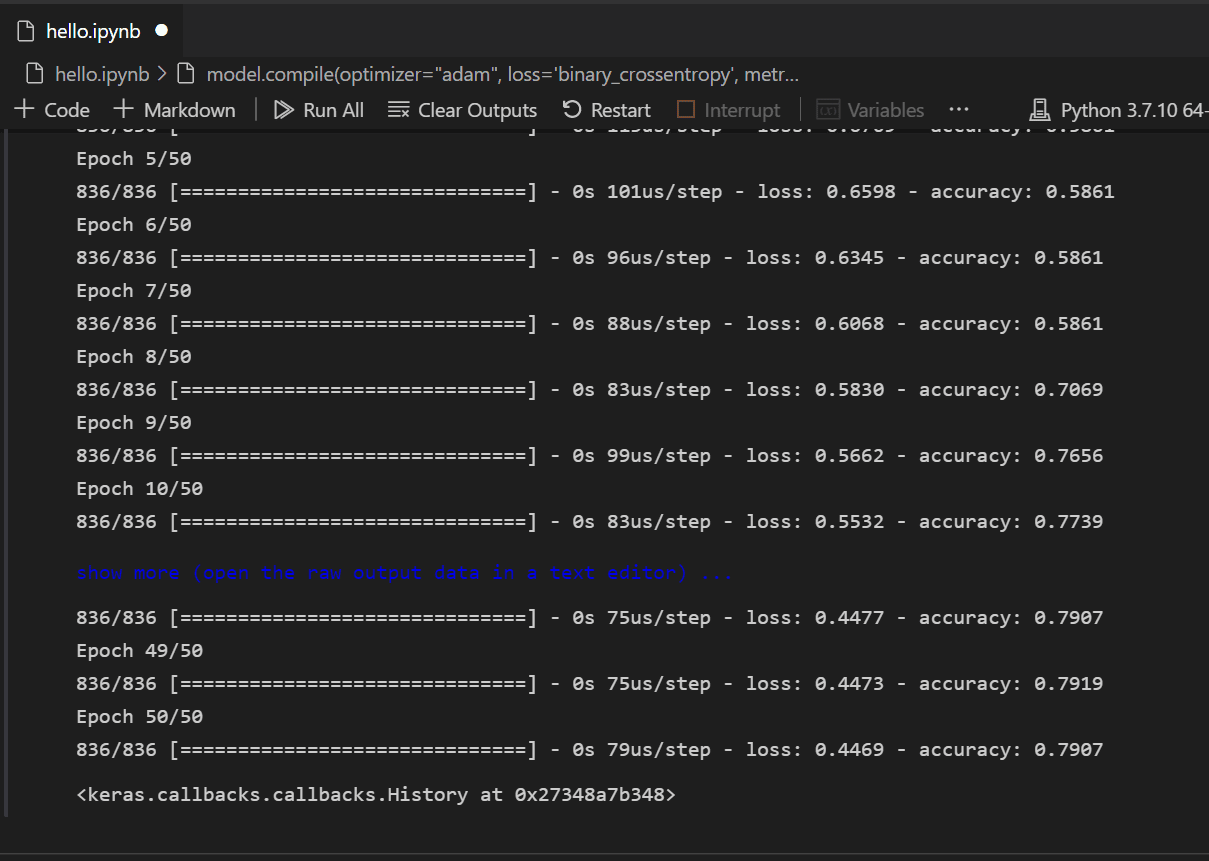
-
Nun, da das Modell erstellt und trainiert ist, können wir sehen, wie es mit den Testdaten funktioniert.
y_pred = np.rint(model.predict(X_test).flatten()) print(metrics.accuracy_score(y_test, y_pred))
Ähnlich wie beim Training werden Sie feststellen, dass Sie nun eine Genauigkeit von 79 % bei der Vorhersage des Überlebens von Passagieren haben. Mit diesem einfachen neuronalen Netz ist das Ergebnis besser als die 75%ige Genauigkeit des zuvor ausprobierten Naive Bayes Classifiers.
Nächste Schritte
Jetzt, da Sie mit den Grundlagen der Ausführung von maschinellem Lernen in Visual Studio Code vertraut sind, finden Sie hier einige weitere Microsoft-Ressourcen und Tutorials, die Sie sich ansehen können.
- Data Science-Profilvorlage - Erstellen Sie ein neues Profil mit einer kuratierten Sammlung von Erweiterungen, Einstellungen und Snippets.
- Erfahren Sie mehr über die Arbeit mit Jupyter-Notebooks in Visual Studio Code (Video).
- Erste Schritte mit Azure Machine Learning für VS Code, um Ihr Modell mit der Leistung von Azure bereitzustellen und zu optimieren.
- Finden Sie weitere Daten zur Erkundung auf Azure Open Data Sets.