Bracket-Paar-Kolorierung 10.000x schneller
29. September 2021 von Henning Dieterichs, @hediet_dev
Wenn man mit tief verschachtelten Klammern in Visual Studio Code arbeitet, kann es schwierig sein herauszufinden, welche Klammern zusammengehören und welche nicht.
Um dies zu erleichtern, entwickelte 2016 ein Benutzer namens CoenraadS die großartige Bracket Pair Colorizer Erweiterung, um passende Klammern zu kolorieren und veröffentlichte sie im VS Code Marketplace. Diese Erweiterung wurde sehr beliebt und ist heute eine der 10 am häufigsten heruntergeladenen Erweiterungen im Marketplace mit über 6 Millionen Installationen.
Um Leistung und Genauigkeitsprobleme anzugehen, folgte 2018 CoenraadS mit Bracket Pair Colorizer 2, die inzwischen ebenfalls über 3 Millionen Installationen hat.
Die Bracket Pair Colorizer Erweiterung ist ein gutes Beispiel für die Leistungsfähigkeit der Erweiterbarkeit von VS Code und nutzt intensiv die Decoration API zur Kolorierung von Klammern.

Wir freuen uns zu sehen, dass der VS Code Marketplace viele weitere solcher von der Community bereitgestellten Erweiterungen bietet, die alle auf sehr kreative Weise dabei helfen, passende Klammerpaare zu identifizieren, darunter: Rainbow Brackets, Subtle Match Brackets, Bracket Highlighter, Blockman und Bracket Lens. Diese Vielfalt an Erweiterungen zeigt, dass ein echtes Bedürfnis von VS Code Benutzern besteht, eine bessere Unterstützung für Klammern zu erhalten.
Das Leistungsproblem
Leider führt die nicht-inkrementelle Natur der Decoration API und der fehlende Zugriff auf die Token-Informationen von VS Code dazu, dass die Bracket Pair Colorizer Erweiterung bei großen Dateien langsam ist: beim Einfügen einer einzelnen Klammer am Anfang der checker.ts Datei des TypeScript-Projekts, die über 42.000 Codezeilen hat, dauert es etwa 10 Sekunden, bis die Farben aller Klammerpaare aktualisiert sind. Während dieser 10 Sekunden Verarbeitungszeit läuft der Extension Host Prozess mit 100% CPU-Auslastung, und alle von Erweiterungen angetriebenen Funktionen wie Autovervollständigung oder Diagnostik hören auf zu funktionieren. Glücklicherweise stellt die Architektur von VS Code sicher, dass die Benutzeroberfläche reaktionsfähig bleibt und Dokumente weiterhin auf die Festplatte gespeichert werden können.
CoenraadS war sich dieses Leistungsproblems bewusst und investierte in Version 2 der Erweiterung viel Aufwand, um Geschwindigkeit und Genauigkeit zu erhöhen, indem er die Token- und Parser-Engine von VS Code wiederverwendete. VS Codes API und Erweiterungsarchitektur waren jedoch nicht darauf ausgelegt, eine Hochleistungs-Klammerpaar-Kolorierung bei Hunderttausenden von Klammerpaaren zu ermöglichen. So dauert es auch in Bracket Pair Colorizer 2 eine Weile, bis die Farben die neuen Verschachtelungsebenen nach dem Einfügen von { am Anfang der Datei widerspiegeln.
Obwohl wir die Leistung der Erweiterung gerne einfach verbessert hätten (was sicherlich die Einführung fortgeschrittenerer APIs erfordert hätte, die für Hochleistungs-Szenarien optimiert sind), schränkt die asynchrone Kommunikation zwischen Renderer und Extension Host stark ein, wie schnell die Klammerpaar-Kolorierung als Erweiterung implementiert werden kann. Diese Grenze kann nicht überwunden werden. Insbesondere sollten Klammerfarben nicht asynchron angefordert werden, sobald sie im Viewport erscheinen, da dies beim Scrollen durch große Dateien zu sichtbarem Flackern geführt hätte. Eine Diskussion hierzu findet sich in Issue #128465.
Was wir getan haben
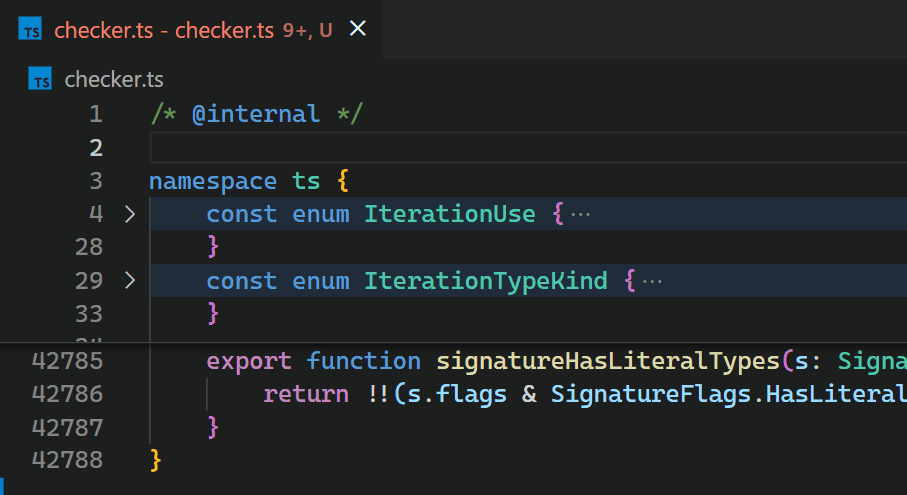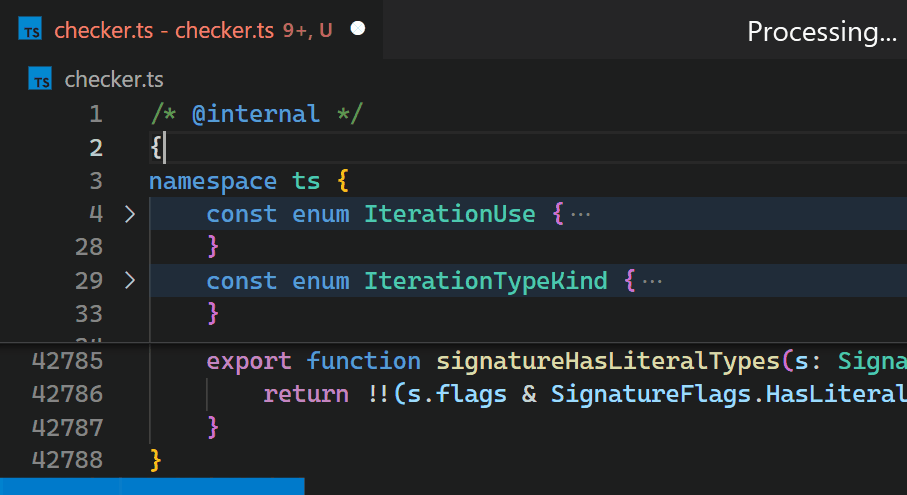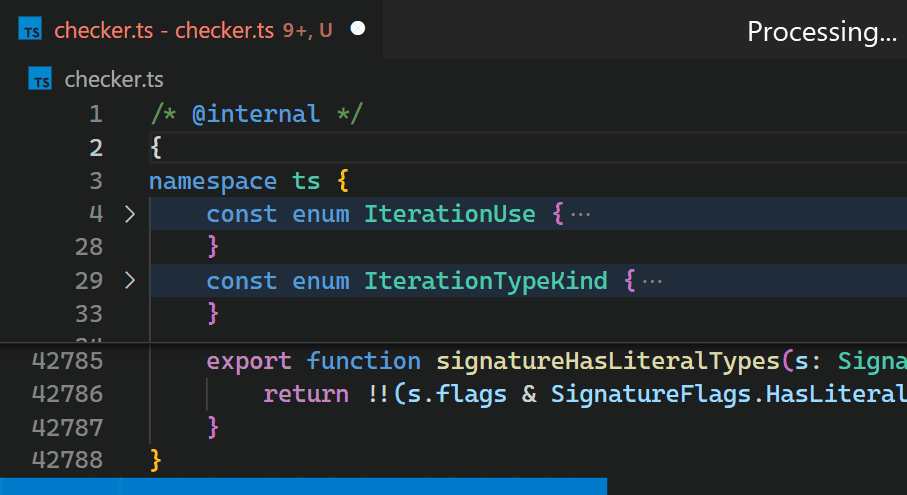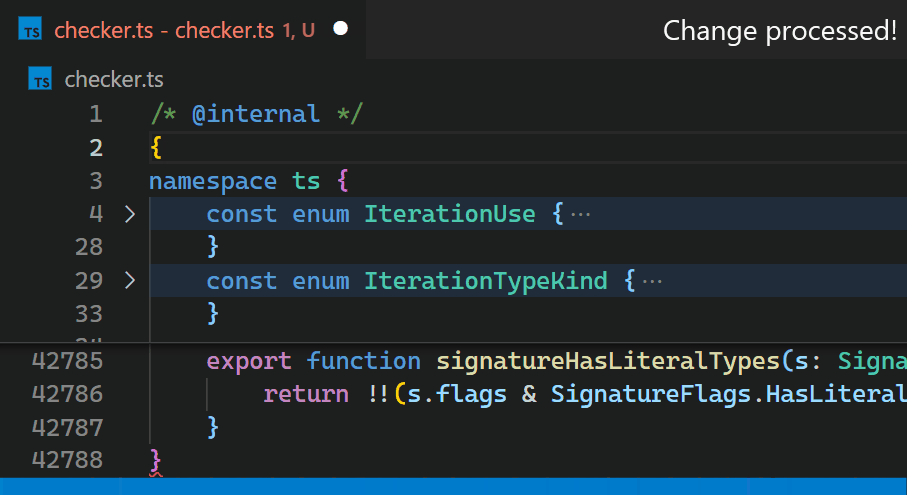
Stattdessen haben wir in Update 1.60 die Erweiterung in den Kern von VS Code neu implementiert und diese Zeit auf weniger als eine Millisekunde reduziert – in diesem speziellen Beispiel ist das mehr als 10.000 Mal schneller.
Das Feature kann aktiviert werden, indem die Einstellung "editor.bracketPairColorization.enabled": true hinzugefügt wird.
Jetzt sind Updates nicht mehr spürbar, selbst bei Dateien mit Hunderttausenden von Klammerpaaren. Beachten Sie, wie die Klammerfarbe in Zeile 42.788 die neue Verschachtelungsebene unmittelbar nach dem Tippen von { in Zeile 2 widerspiegelt.
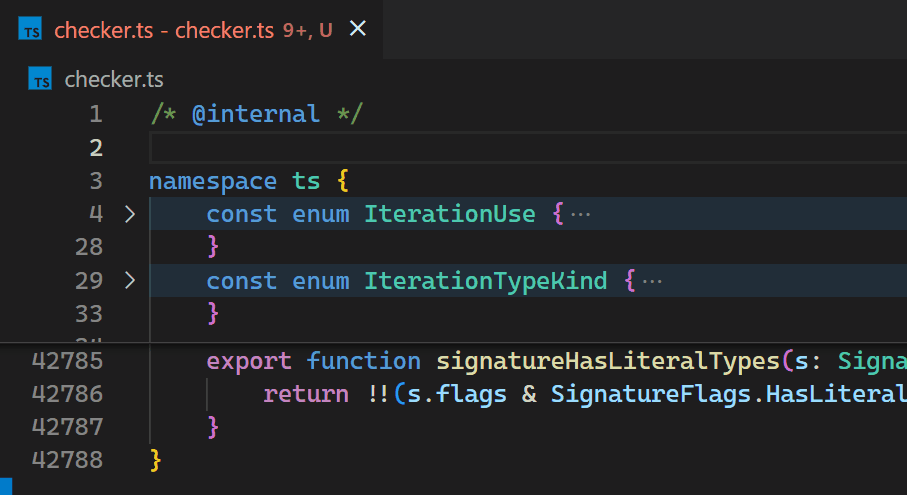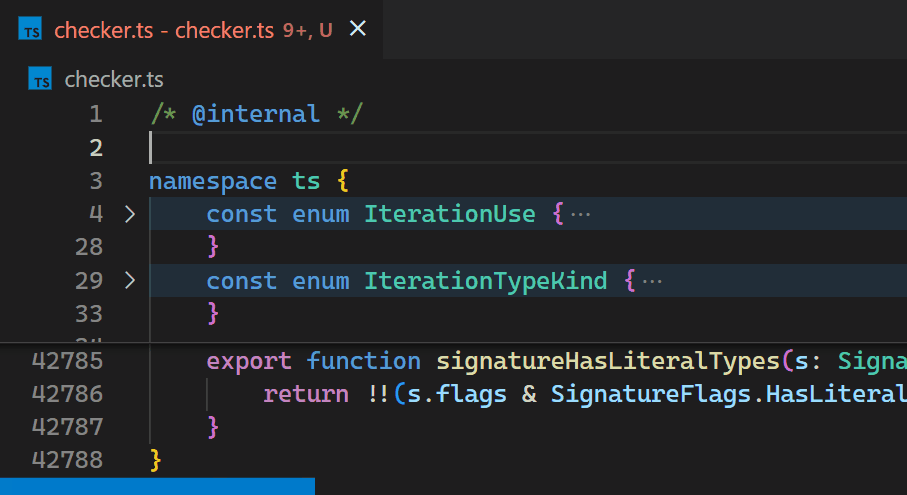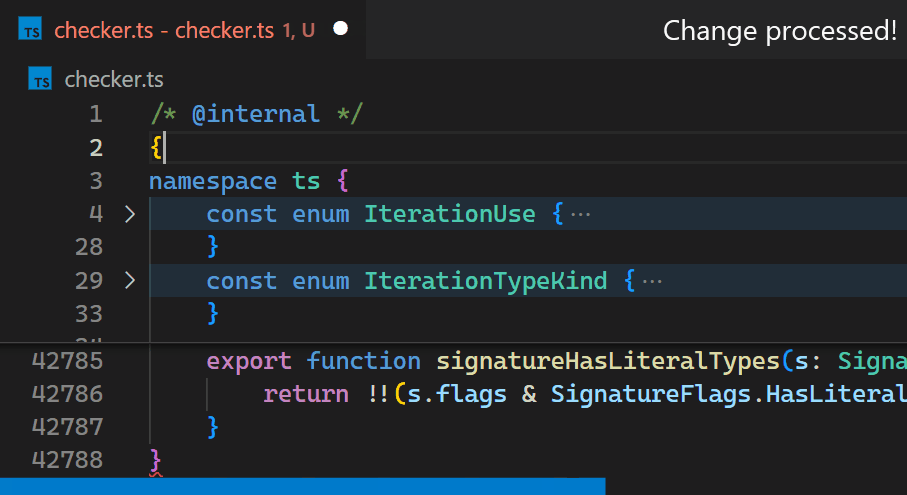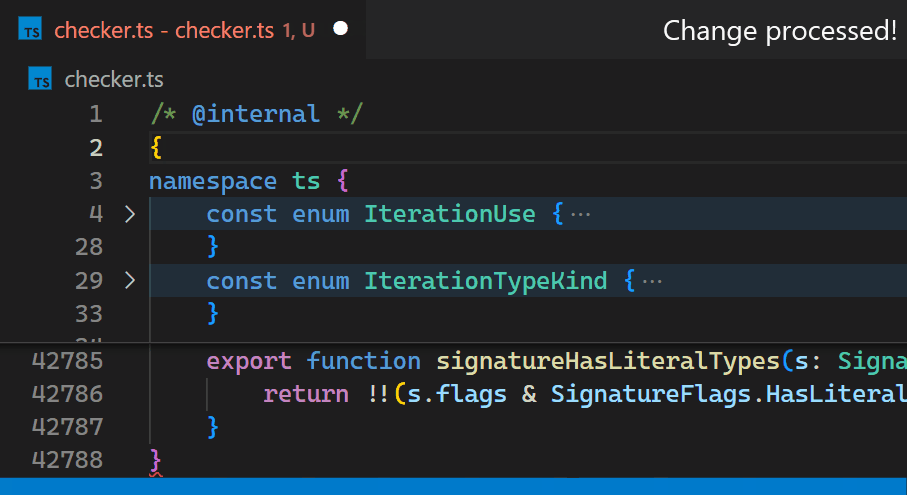
Als wir uns entschieden, es in den Kern zu verlagern, nutzten wir auch die Gelegenheit, uns anzusehen, wie wir es so schnell wie möglich machen können. Wer würde eine algorithmische Herausforderung nicht lieben?
Ohne durch das Design der öffentlichen API eingeschränkt zu sein, konnten wir (2,3)-Bäume, rekursionsfreie Baumtraversierung, Bit-Arithmetik, inkrementelle Analyse und andere Techniken verwenden, um die Worst-Case-Update-Zeitkomplexität der Erweiterung (d.h. die Zeit, die für die Verarbeitung von Benutzereingaben benötigt wird, wenn ein Dokument bereits geöffnet wurde) zu reduzieren von
Zusätzlich haben wir durch die Wiederverwendung der vorhandenen Tokens aus dem Renderer und dessen inkrementellen Token-Update-Mechanismus eine weitere massive (aber konstante) Beschleunigung erzielt.
VS Code für das Web
Abgesehen davon, dass die neue Implementierung leistungsfähiger ist, wird sie auch in VS Code für das Web unterstützt, was Sie mit vscode.dev und github.dev in Aktion sehen können. Aufgrund der Art und Weise, wie Bracket Pair Colorizer 2 die VS Code Token-Engine wiederverwendet, war es nicht möglich, die Erweiterung zu dem zu migrieren, was wir eine Web-Erweiterung nennen.
Unsere neue Implementierung funktioniert nicht nur in VS Code für das Web, sondern auch direkt im Monaco Editor!
Die Herausforderung der Klammerpaar-Kolorierung
Bei der Klammerpaar-Kolorierung geht es darum, schnell alle Klammern und ihre (absolute) Verschachtelungsebene im Viewport zu bestimmen. Der Viewport kann als ein Bereich im Dokument in Bezug auf Zeilen- und Spaltennummern beschrieben werden und ist normalerweise nur ein winziger Bruchteil des gesamten Dokuments.
Leider hängt die Verschachtelungsebene einer Klammer von *allen* ihr vorangehenden Zeichen ab: das Ersetzen eines beliebigen Zeichens durch die öffnende Klammer "{" erhöht normalerweise die Verschachtelungsebene aller folgenden Klammern.
Daher muss bei der anfänglichen Kolorierung von Klammern am Ende eines Dokuments jedes einzelne Zeichen des gesamten Dokuments verarbeitet werden.

Die Implementierung in der Bracket Pair Colorizer-Erweiterung geht diese Herausforderung an, indem das gesamte Dokument jedes Mal neu verarbeitet wird, wenn eine einzelne Klammer eingefügt oder entfernt wird (was für kleine Dokumente sehr vernünftig ist). Die Farben müssen dann entfernt und mit der VS Code Decoration API neu angewendet werden, die alle Farbdekorationen an den Renderer sendet.
Wie bereits gezeigt, ist dies bei großen Dokumenten mit Hunderttausenden von Klammerpaaren und damit ebenso vielen Farbdekorationen langsam. Da Erweiterungen Dekorationen nicht inkrementell aktualisieren können und sie alle auf einmal ersetzen müssen, kann die Bracket Pair Colorizer-Erweiterung auch nicht viel besser abschneiden. Dennoch organisiert der Renderer all diese Dekorationen auf clevere Weise (unter Verwendung eines sogenannten Intervallbaums), sodass das Rendern immer schnell ist, nachdem (potenziell Hunderttausende von) Dekorationen empfangen wurden.
Unser Ziel ist es, nicht bei jedem Tastendruck das gesamte Dokument neu verarbeiten zu müssen. Stattdessen soll die Zeit, die zur Verarbeitung einer einzelnen Textänderung benötigt wird, nur (poly) logarithmisch mit der Dokumentlänge wachsen.
Wir möchten jedoch immer noch in der Lage sein, alle Klammern und ihre Verschachtelungsebene im Viewport in (poly) logarithmischer Zeit abzufragen, so wie es bei der Verwendung der VS Code Dekorations-API der Fall wäre (die den erwähnten Intervallbaum verwendet).
Algorithmenkomplexitäten
Sie können die Abschnitte über algorithmische Komplexitäten gerne überspringen.
Im Folgenden
Wir erlauben jedoch eine Initialisierungszeitkomplexität von
Sprachsemantik erschwert die Klammerpaar-Kolorierung
Was die Klammerpaar-Kolorierung wirklich schwierig macht, ist die Erkennung tatsächlicher Klammern, wie sie von der Dokumentsprache definiert werden. Insbesondere wollen wir keine öffnenden oder schließenden Klammern in Kommentaren oder Strings erkennen, wie das folgende C-Beispiel zeigt.
{ /* } */ char str[] = "}"; }
Nur das dritte Vorkommen von "}" schließt das Klammerpaar.
Das wird für Sprachen, bei denen die Token-Sprache nicht regulär ist, wie z. B. TypeScript mit JSX, noch schwieriger.

Passt die Klammer bei [1] zur Klammer bei [2] oder bei [3]? Dies hängt von der Länge des Template-Literals-Ausdrucks ab, die nur ein Tokenizer mit unbegrenztem Zustand (ein nicht-regulärer Tokenizer) korrekt bestimmen kann.
Tokens zur Rettung
Glücklicherweise muss die Syntaxhervorhebung ein ähnliches Problem lösen: Sollte die Klammer bei [2] im obigen Code-Snippet als String oder als einfacher Text gerendert werden?
Es stellt sich heraus, dass das Ignorieren von Klammern in Kommentaren und Strings, wie sie von der Syntaxhervorhebung identifiziert werden, für die meisten Klammerpaare gut genug funktioniert. < ... > ist das einzige problematische Paar, das wir bisher gefunden haben, da diese Klammern üblicherweise sowohl für Vergleiche als auch als Paar für generische Typen verwendet werden, aber denselben Token-Typ haben.
VS Code verfügt bereits über einen effizienten und synchronen Mechanismus zur Pflege von Token-Informationen für die Syntaxhervorhebung, und wir können diesen wiederverwenden, um öffnende und schließende Klammern zu identifizieren.
Dies ist eine weitere Herausforderung der Bracket Pair Colorization-Erweiterung, die die Leistung negativ beeinflusst: Sie hat keinen Zugriff auf diese Tokens und muss sie selbst neu berechnen. Wir haben lange darüber nachgedacht, wie wir Token-Informationen effizient und zuverlässig für Erweiterungen verfügbar machen könnten, kamen aber zu dem Schluss, dass wir dies nicht ohne viele Implementierungsdetails tun können, die in die Erweiterungs-API durchsickern. Da die Erweiterung immer noch eine Liste von Farbdekorationen für jede Klammer im Dokument senden muss, würde eine solche API allein das Leistungsproblem nicht lösen.
Nebenbei bemerkt: Wenn am Anfang eines Dokuments eine Bearbeitung angewendet wird, die alle folgenden Tokens ändert (wie das Einfügen von /* für C-ähnliche Sprachen), wird VS Code keine langen Dokumente auf einmal, sondern in Teilen über die Zeit neu tokenisieren. Dies stellt sicher, dass die Benutzeroberfläche nicht einfriert, obwohl die Tokenisierung synchron im Renderer erfolgt.
Der grundlegende Algorithmus
Die Kernidee ist die Verwendung eines rekursiven Abstiegs-Parsers, um einen abstrakten Syntaxbaum (AST) zu erstellen, der die Struktur aller Klammerpaare beschreibt. Wenn eine Klammer gefunden wird, wird die Token-Information geprüft und die Klammer übersprungen, wenn sie sich in einem Kommentar oder String befindet. Ein Tokenizer ermöglicht es dem Parser, solche Klammer- oder Text-Tokens zu inspizieren und zu lesen.
Der Trick besteht nun darin, nur die Länge jedes Knotens zu speichern (und auch Textknoten für alles zu haben, was keine Klammer ist, um die Lücken zu füllen), anstatt absolute Start-/Endpositionen zu speichern. Mit nur Längenangaben kann ein Klammerknoten an einer gegebenen Position weiterhin effizient im AST gefunden werden.
Das folgende Diagramm zeigt einen beispielhaften AST mit Längenanmerkungen.

Vergleichen Sie dies mit der klassischen AST-Darstellung mit absoluten Start-/Endpositionen.

Beide ASTs beschreiben dasselbe Dokument, aber beim Durchlaufen des ersten AST müssen die absoluten Positionen zur Laufzeit berechnet werden (was kostengünstig ist), während sie im zweiten bereits vorab berechnet sind.
Wenn jedoch ein einzelnes Zeichen in den ersten Baum eingefügt wird, müssen nur die Längen des Knotens selbst und aller seiner übergeordneten Knoten aktualisiert werden – alle anderen Längen bleiben gleich.
Wenn absolute Positionen wie im zweiten Baum gespeichert sind, muss die Position *jedes* nachfolgenden Knotens im Dokument erhöht werden.
Außerdem können durch die Nichtspeicherung von absoluten Offsets Blattknoten mit gleicher Länge geteilt werden, um Allokationen zu vermeiden.
So könnte der AST mit Längenanmerkungen in TypeScript definiert werden:
type Length = ...;
type AST = BracketAST | BracketPairAST | ListAST | TextAST;
/** Describes a single bracket, such as `{`, `}` or `begin` */
class BracketAST {
constructor(public length: Length) {}
}
/** Describes a matching bracket pair and the node in between, e.g. `{...}` */
class BracketPairAST {
constructor(
public openingBracket: BracketAST;
public child: BracketPairAST | ListAST | TextAST;
public closingBracket: BracketAST;
) {}
length = openingBracket.length + child.length + closingBracket.length;
}
/** Describes a list of bracket pairs or text nodes, e.g. `()...()` */
class ListAST {
constructor(
public items: Array<BracketPairAST | TextAST>
) {}
length = items.sum(item => item.length);
}
/** Describes text that has no brackets in it. */
class TextAST {
constructor(public length: Length) {}
}
Die Abfrage eines solchen AST zur Auflistung aller Klammern und ihrer Verschachtelungsebene im Viewport ist relativ einfach: Führen Sie eine Tiefensuche durch, berechnen Sie die absolute Position des aktuellen Knotens zur Laufzeit (durch Addition der Längen früherer Knoten) und überspringen Sie Kinder von Knoten, die vollständig vor oder nach dem angeforderten Bereich liegen.
Dieser grundlegende Algorithmus funktioniert bereits, wirft aber einige offene Fragen auf:
- Wie können wir sicherstellen, dass die Abfrage aller Klammern in einem gegebenen Bereich die gewünschte logarithmische Leistung erzielt?
- Wie können wir beim Tippen vermeiden, einen neuen AST von Grund auf neu zu erstellen?
- Wie können wir Token-Chunk-Updates verarbeiten? Beim Öffnen eines großen Dokuments sind Tokens zunächst nicht verfügbar, sondern kommen chunkweise herein.
Sicherstellen, dass die Abfragezeit logarithmisch ist
Was die Leistung bei der Abfrage von Klammern in einem bestimmten Bereich beeinträchtigt, sind wirklich lange Listen: Wir können keine schnelle binäre Suche auf ihren Kindern durchführen, um alle irrelevanten, nicht überlappenden Knoten zu überspringen, da wir die Länge jedes Knotens summieren müssen, um die absolute Position zur Laufzeit zu berechnen. Im schlimmsten Fall müssen wir sie alle durchlaufen.
Im folgenden Beispiel müssen wir 13 Knoten (in Blau) betrachten, bis wir die Klammer an Position 24 finden.

Wir könnten zwar Längensummen berechnen und cachen, um die binäre Suche zu ermöglichen, aber das hat dasselbe Problem wie das Speichern absoluter Positionen: Wir müssten sie alle neu berechnen, wenn sich ein einzelner Knoten wächst oder schrumpft, was bei sehr langen Listen kostspielig ist.
Stattdessen erlauben wir Listen, andere Listen als Kinder zu haben.
class ListAST {
constructor(public items: Array<ListAST | BracketPairAST | TextAST>) {}
length = items.sum(item => item.length);
}
Wie verbessert das die Situation?
Wenn wir sicherstellen können, dass jede Liste nur eine begrenzte Anzahl von Kindern hat und einem balancierten Baum mit logarithmischer Höhe ähnelt, dann reicht dies aus, um die gewünschte logarithmische Leistung für die Abfrage von Klammern zu erzielen.
Listenbäume balanciert halten
Wir verwenden (2,3)-Bäume, um sicherzustellen, dass diese Listen balanciert sind: Jede Liste muss mindestens 2 und höchstens 3 Kinder haben, und alle Kinder einer Liste müssen in dem balancierten Listenbaum dieselbe Höhe haben. Beachten Sie, dass ein Klammerpaar als Blatt der Höhe 0 im balancierten Baum gilt, aber im AST Kinder haben kann.
Beim Erstellen des AST von Grund auf während der Initialisierung sammeln wir zunächst alle Kinder und wandeln sie dann in einen solchen balancierten Baum um. Dies kann in linearer Zeit erfolgen.
Ein möglicher (2,3)-Baum des vorherigen Beispiels könnte wie folgt aussehen. Beachten Sie, dass wir jetzt nur noch 8 Knoten (in Blau) betrachten müssen, um das Klammerpaar an Position 24 zu finden, und dass es etwas Freiheit gibt, ob eine Liste 2 oder 3 Kinder hat.

Worst-Case-Komplexitätsanalyse
Sie können die Abschnitte über algorithmische Komplexitäten gerne überspringen.
Vorerst gehen wir davon aus, dass jede Liste einem (2,3)-Baum ähnelt und somit höchstens 3 Kinder hat.
Um die Abfragezeit zu maximieren, betrachten wir ein Dokument, das
{
{
... O(log N) many nested bracket pairs
{
{} [1]
}
...
}
}
hat. Noch sind keine Listen beteiligt, aber wir müssen bereits
Nun füllen wir für den Worst-Case das Dokument auf, bis es die Größe
{}{}{}{}{}{}{}{}... O(N / log N) many
{
{}{}{}{}{}{}{}{}... O(N / log N) many
{
... O(log N) many nested bracket pairs
{
{}{}{}{}{}{}{}{}... O(N / log N) many
{} [1]
}
...
}
}
Jede Liste von Klammern auf derselben Verschachtelungsebene erzeugt einen Baum der Höhe
Daher müssen wir, um den Knoten bei [1] zu finden,
Somit ist die Worst-Case-Zeitkomplexität der Abfrage von Klammerpaaren
Dies zeigt auch, dass der AST eine maximale Höhe von
Inkrementelle Aktualisierungen
Die interessanteste Frage der performanten Klammerpaarfärbung bleibt offen: Wie aktualisieren wir effizient den Baum, um eine Textänderung zu reflektieren, gegeben den aktuellen (ausgeglichenen) AST und eine Textänderung, die einen bestimmten Bereich ersetzt?
Die Idee ist, den für die Initialisierung verwendeten rekursiven Abstiegs-Parser wiederzuverwenden und eine Caching-Strategie hinzuzufügen, sodass Knoten, die von der Textänderung nicht betroffen sind, wiederverwendet und übersprungen werden können.
Wenn der rekursive Abstiegs-Parser eine Liste von Klammerpaaren an Position
Das folgende Beispiel zeigt, welche Knoten (in Grün) wiederverwendet werden können, wenn ein einzelnes öffnendes Klammerzeichen eingefügt wird (einzelne Klammerknoten werden weggelassen)

Nach der Verarbeitung der Textänderung durch erneutes Parsen der Knoten, die Änderungen enthalten, und Wiederverwendung aller unveränderten Knoten sieht der aktualisierte AST wie folgt aus. Beachten Sie, dass alle 11 wiederverwendbaren Knoten wiederverwendet werden können, indem die 3 Knoten B, H und G konsumiert werden und nur 4 Knoten neu erstellt werden mussten (in Orange).

Wie dieses Beispiel zeigt, machen ausgeglichene Listen nicht nur die Abfrage schnell, sondern helfen auch, riesige Teile von Knoten auf einmal wiederzuverwenden.
Algorithmische Komplexität
Sie können die Abschnitte über algorithmische Komplexitäten gerne überspringen.
Gehen wir davon aus, dass die Textänderung einen Bereich der Größe bis zu
Wir müssen nur Knoten neu parsen, die den Änderungsbereich schneiden. Daher höchstens
Selbstverständlich, wenn ein Knoten den Änderungsbereich nicht schneidet, dann auch keines seiner Kinder. Daher müssen wir nur wiederverwendbare Knoten berücksichtigen, die den Änderungsbereich nicht schneiden, deren Elternknoten aber schon (dies wird implizit alle Knoten wiederverwenden, bei denen weder der Knoten noch sein Elternteil den Änderungsbereich schneiden). Außerdem können solche Elternknoten nicht vollständig vom Änderungsbereich abgedeckt werden, sonst würden alle ihre Kinder den Änderungsbereich schneiden. Allerdings hat jede Ebene im AST höchstens zwei Knoten, die den Änderungsbereich teilweise schneiden. Da ein AST höchstens
Somit müssen wir zur Konstruktion des aktualisierten Baumes höchstens
Dies würde auch die Zeitkomplexität der Update-Operation bestimmen, aber es gibt einen Vorbehalt.
Wie balancieren wir den AST neu?
Leider ist der Baum im letzten Beispiel nicht mehr ausgeglichen.
Beim Kombinieren eines wiederverwendeten Listen-Knotens mit einem neu geparsten Knoten müssen wir einige Arbeit leisten, um die (2,3)-Baum-Eigenschaft zu erhalten. Wir wissen, dass sowohl wiederverwendete als auch neu geparste Knoten bereits (2,3)-Bäume sind, aber sie können unterschiedliche Höhen haben - daher können wir nicht einfach übergeordnete Knoten erstellen, da alle Kinder eines (2,3)-Baum-Knotens die gleiche Höhe haben müssen.
Wie können wir all diese Knoten unterschiedlicher Höhen effizient zu einem einzigen (2,3)-Baum zusammenfügen?
Dies kann leicht auf das Problem des Voranstellen oder Anhängen eines kleineren Baumes an einen größeren Baum reduziert werden: Wenn zwei Bäume die gleiche Höhe haben, reicht es aus, eine Liste zu erstellen, die beide Kinder enthält. Andernfalls fügen wir den kleineren Baum der Höhe
Da dies eine Laufzeit von
Um die Listen α und γ des vorherigen Beispiels auszugleichen, führen wir die Concat-Operation auf ihren Kindern durch (rote Listen verletzen die (2,3)-Baum-Eigenschaft, orangefarbene Knoten haben unerwartete Höhen, und grüne Knoten werden neu erstellt, während neu balanciert wird).

Da Liste B die Höhe 2 und Klammerpaar β die Höhe 0 im unausgeglichenen Baum hat, müssen wir β an B anhängen und sind mit Liste α fertig. Der verbleibende (2,3)-Baum ist B, daher wird er zur neuen Wurzel und ersetzt Liste α. Weiter mit γ, seine Kinder δ und H haben Höhe 0, während G Höhe 1 hat.
Wir fügen zuerst δ und H zusammen und erstellen einen neuen übergeordneten Knoten Y der Höhe 1 (da δ und H die gleiche Höhe haben). Dann fügen wir Y und G zusammen und erstellen eine neue übergeordnete Liste X (aus demselben Grund). X wird dann zum neuen Kind des übergeordneten Klammerpaares und ersetzt die unausgeglichene Liste γ.
Im Beispiel reduzierte die Balancing-Operation effektiv die Höhe der obersten Liste von 3 auf 2. Die Gesamthöhe des AST erhöhte sich jedoch von 4 auf 5, was sich negativ auf die Worst-Case-Abfragezeit auswirkt. Dies wird durch das Klammerpaar β verursacht, das als Blatt im ausgeglichenen Listenbaum fungiert, aber tatsächlich eine weitere Liste der Höhe 2 enthält.
Die Berücksichtigung der internen AST-Höhe von β beim Ausbalancieren der übergeordneten Liste könnte den Worst-Case verbessern, würde aber die Theorie der (2,3)-Bäume verlassen.
Algorithmische Komplexität
Sie können die Abschnitte über algorithmische Komplexitäten gerne überspringen.
Wir müssen höchstens
Da das Zusammenfügen zweier Knoten unterschiedlicher Höhe eine Zeitkomplexität von
Wie finden wir wiederverwendbare Knoten effizient?
Wir haben zwei Datenstrukturen für diese Aufgabe: den *Before-Edit-Position-Mapper* und den *Node Reader*.
Der Positionsmapper ordnet eine Position im neuen Dokument (nach Anwendung der Änderung) dem alten Dokument (vor Anwendung der Änderung) zu, falls möglich. Er gibt uns auch die Länge zwischen der aktuellen Position und der nächsten Änderung an (oder 0, wenn wir uns in einer Änderung befinden). Dies geschieht in
Wenn eine Textänderung verarbeitet und ein Knoten geparst wird, liefert uns diese Komponente die Position eines Knotens, den wir potenziell wiederverwenden können, und die maximale Länge, die dieser Knoten haben darf – klarerweise muss der wiederzuverwendende Knoten kürzer sein als der Abstand zur nächsten Änderung.
Der Node Reader kann schnell den längsten Knoten finden, der eine gegebene Prädikatsbedingung an einer gegebenen Position in einem AST erfüllt. Um einen wiederverwendbaren Knoten zu finden, verwenden wir den Positionsmapper, um seine alte Position und seine maximal zulässige Länge nachzuschlagen, und dann den Node Reader, um diesen Knoten zu finden. Wenn wir einen solchen Knoten gefunden haben, wissen wir, dass er sich nicht geändert hat, und können ihn wiederverwenden und seine Länge überspringen.
Da der Node Reader mit monoton steigenden Positionen abgefragt wird, muss er nicht jedes Mal von vorne beginnen, sondern kann von seinem Ende des letzten wiederverwendeten Knotens aus fortfahren. Entscheidend dafür ist ein rekursionsfreier Baumtraversierungsalgorithmus, der in Knoten hineintauchen, sie aber auch überspringen oder zum übergeordneten Knoten zurückkehren kann. Wenn ein wiederverwendbarer Knoten gefunden wird, stoppt die Traversierung und setzt mit der nächsten Anfrage an den Node Reader fort.
Die Komplexität der einmaligen Abfrage des Node Readers beträgt bis zu
Token-Updates
Beim Einfügen von /* am Anfang langer C-Style-Dokumente, die den Text */ nicht enthalten, wird das gesamte Dokument zu einem einzigen Kommentar und alle Token ändern sich.
Da Token synchron im Renderer-Prozess berechnet werden, kann die Retokenisierung nicht auf einmal erfolgen, ohne die Benutzeroberfläche einzufrieren.
Stattdessen werden Token in Stapeln über die Zeit aktualisiert, sodass die JavaScript-Event-Schleife nicht zu lange blockiert wird. Während dieser Ansatz die gesamte Blockierungszeit nicht reduziert, verbessert er die Reaktionsfähigkeit der Benutzeroberfläche während des Updates. Derselbe Mechanismus wird auch bei der anfänglichen Tokenisierung eines Dokuments verwendet.
Glücklicherweise können wir dank des inkrementellen Update-Mechanismus des Klammerpaar-AST solche gestapelten Token-Updates sofort anwenden, indem wir das Update als einzelne Textänderung behandeln, die den neu tokenisierten Bereich durch sich selbst ersetzt. Sobald alle Token-Updates eingegangen sind, ist der Klammerpaar-AST garantiert im selben Zustand wie wenn er von Grund auf neu erstellt worden wäre - selbst wenn der Benutzer das Dokument bearbeitet, während die Token-Aktualisierung läuft.
Auf diese Weise ist nicht nur die Tokenisierung performant, auch wenn sich alle Token im Dokument ändern, sondern auch die Klammerpaarfärbung.
Wenn ein Dokument jedoch viele unausgeglichene Klammern in Kommentaren enthält, können die Farben der Klammern am Ende des Dokuments flackern, da der Klammerpaar-Parser erkennt, dass diese Klammern ignoriert werden sollten.
Um das Flackern von Klammerfarben beim Öffnen eines Dokuments und Navigieren zum Ende zu vermeiden, pflegen wir zwei Klammerpaar-ASTs, bis der anfängliche Tokenisierungsprozess abgeschlossen ist. Der erste AST wird ohne Token-Informationen erstellt und erhält keine Token-Updates. Der zweite ist anfangs eine Kopie des ersten ASTs, erhält aber Token-Updates und weicht zunehmend ab, je weiter die Tokenisierung fortschreitet und Token-Updates angewendet werden. Anfangs wird der erste AST zum Abfragen von Klammerpaaren verwendet, aber der zweite übernimmt, sobald das Dokument vollständig tokenisiert ist.
Da Deep Cloning fast so teuer ist wie das erneute Parsen des Dokuments, haben wir Copy-on-Write implementiert, was das Klonen in
Kodierung von Längen
Die Editoransicht beschreibt das Viewport mit Zeilen- und Spaltennummern. Farbdekorationen werden ebenfalls als zeilen-/spaltenbasierte Bereiche erwartet.
Um Konvertierungen zwischen Offset- und Zeilen-/Spalten-basierten Positionen zu vermeiden (was in
Beachten Sie, dass dieser Ansatz erheblich von Datenstrukturen abweicht, die direkt nach Zeilen indiziert sind (wie z.B. die Verwendung eines Zeichenketten-Arrays zur Beschreibung des Zeileninhalts eines Dokuments). Insbesondere kann dieser Ansatz eine einzelne binäre Suche über und innerhalb von Zeilen durchführen.
Das Addieren zweier solcher Längen ist einfach, erfordert jedoch eine Fallunterscheidung: Während die Zeilenzahlen direkt addiert werden, wird die Spaltenzahl der ersten Länge nur berücksichtigt, wenn die zweite Länge null Zeilen umfasst.
Überraschenderweise muss der Großteil des Codes nicht wissen, wie Längen dargestellt werden. Nur der Positionsmapper wurde signifikant komplexer, da darauf geachtet werden musste, dass eine einzelne Zeile mehrere Textänderungen enthalten kann.
Als Implementierungsdetail kodieren wir solche Längen in einer einzigen Zahl, um den Speicherbedarf zu reduzieren. JavaScript unterstützt Ganzzahlen bis zu
Weitere Schwierigkeiten: Ungeöffnete Klammerpaare
Bisher haben wir angenommen, dass alle Klammerpaare ausgeglichen sind. Wir wollen jedoch auch ungeöffnete und ungeschlossene Klammerpaare unterstützen. Die Schönheit eines rekursiven Abstiegs-Parsers ist, dass wir Anker-Sets zur Verbesserung der Fehlerbehebung verwenden können.
Betrachten Sie das folgende Beispiel
( [1]
} [2]
) [3]
Offensichtlich schließt `}` an [2] kein Klammerpaar und stellt eine ungeöffnete Klammer dar. Die Klammern bei [1] und [3] passen gut zusammen. Wenn jedoch `{` am Anfang des Dokuments eingefügt wird, ändert sich die Situation
{ [0]
( [1]
} [2]
) [3]
Jetzt sollten [0] und [2] zusammenpassen, während [1] eine ungeschlossene Klammer und [3] eine ungeöffnete Klammer ist.
Insbesondere sollte [1] eine ungeschlossene Klammer sein, die vor [2] im folgenden Beispiel endet
{
( [1]
} [2]
{}
Andernfalls könnte das Öffnen einer Klammer den Verschachtelungsgrad von nicht verwandten nachfolgenden Klammerpaaren ändern.
Um diese Art von Fehlerbehebung zu unterstützen, können Anker-Sets verwendet werden, um die Menge der erwarteten Token zu verfolgen, mit denen der Aufrufer fortfahren kann. An Position [1] im vorherigen Beispiel wäre das Anker-Set}
Im ersten Beispiel ist das Anker-Set bei [2])
Dies muss bei der Wiederverwendung von Knoten berücksichtigt werden: Das Paar `( } )` kann nicht wiederverwendet werden, wenn es mit `{` vorangestellt wird. Wir verwenden Bit-Sets zur Kodierung von Anker-Sets und berechnen die Menge der enthaltenden ungeöffneten Klammern für jeden Knoten. Wenn sie sich überschneiden, können wir den Knoten nicht wiederverwenden. Glücklicherweise gibt es nur wenige Klammertypen, sodass dies die Leistung nicht zu stark beeinträchtigt.
Weiterführend
Effiziente Klammerpaarfärbung war eine lustige Herausforderung. Mit den neuen Datenstrukturen können wir auch andere Probleme im Zusammenhang mit Klammerpaaren effizienter lösen, wie z. B. allgemeine Klammerpaar-Suche oder farbige Zeilenbereiche anzeigen.
Auch wenn JavaScript vielleicht nicht die beste Sprache für Hochleistungs-Code ist, kann viel Geschwindigkeit durch die Reduzierung der asymptotischen algorithmischen Komplexität gewonnen werden, insbesondere bei großen Eingaben.
Viel Spaß beim Programmieren!
Henning Dieterichs, Mitglied des VS Code Teams @hediet_dev