Das Language Server Index Format (LSIF)
19. Februar 2019 von Dirk Bäumer
Umfangreiche Code-Navigation ohne Checkout
Als Entwickler verbringen Sie viel Zeit mit dem Lesen und Überprüfen von Code und nicht unbedingt mit dem Erstellen von neuem Quellcode. Sie möchten beispielsweise eine bestehende Codebasis in einem Repository wie GitHub durchsuchen oder den Pull Request eines Kollegen überprüfen.
Normalerweise würden Sie einen Branch auschecken oder ein Repository klonen, den Quellcode auf Ihren lokalen Rechner herunterladen, Ihr bevorzugtes Entwicklungstool öffnen und dann können Sie den Code lesen und navigieren. Wäre es nicht cool, wenn Sie das tun könnten, ohne das Repo zuerst klonen zu müssen? Stellen Sie sich vor, Sie erhalten intelligente Codefunktionen wie Hover-Informationen, "Gehe zu Definition" und "Finde alle Referenzen", ohne Quellcode herunterladen zu müssen. Der Blogbeitrag Erster Einblick in eine umfassende Code-Navigationserfahrung veranschaulicht dieses Szenario für eine Pull Request-Überprüfung.
Das Ziel des Language Server Index Format (LSIF, ausgesprochen wie "else if") ist die Unterstützung einer umfassenden Code-Navigation in Entwicklungstools oder einer Web-Benutzeroberfläche, ohne dass eine lokale Kopie des Quellcodes erforderlich ist. Das Format ist im Geiste dem Language Server Protocol (LSP) ähnlich, das die Integration von umfassenden Code-Bearbeitungsfunktionen in ein Entwicklungstool vereinfacht.
Warum nicht einfach einen bestehenden LSP-Sprachserver verwenden? LSP bietet umfangreiche Code-Erstellungsfunktionen wie Autovervollständigung, Typformatierung und umfassende Code-Navigation. Um diese Funktionen effizient bereitzustellen, benötigt ein Sprachserver Zugriff auf alle Quellcodedateien auf einer lokalen Festplatte. LSP-Sprachserver können auch Teile oder alle Dateien in den Speicher laden und abstrakte Syntaxbäume berechnen, um diese Funktionen zu ermöglichen. Das Ziel des Language Server Index Format ist es, das LSP-Protokoll zu erweitern, um umfassende Code-Navigationsfunktionen ohne diese Anforderungen zu unterstützen. LSIF definiert ein Standardformat, mit dem Sprachserver oder andere Programmiertools ihr Wissen über einen Code-Workspace veröffentlichen können. Diese gespeicherten Informationen können später verwendet werden, um LSP-Anfragen für denselben Workspace zu beantworten, ohne einen Sprachserver ausführen zu müssen.
Language Server Index Format
LSIF baut auf LSP auf und verwendet dieselben Datentypen wie in LSP definiert. Auf hoher Ebene modelliert LSIF die Daten, die von Sprachserveranfragen zurückgegeben werden. Wie LSP enthält LSIF keine Informationen über Programmelemente und LSIF definiert auch keine Semantik von Elementen (z. B. was die Definition eines Elements ausmacht oder ob eine Methode eine andere überschreibt). LSIF definiert daher keine Symbol-Datenbank, was dem LSP-Ansatz entspricht.
Die Verwendung der bestehenden LSP-Datentypen als Basis für LSIF hat einen weiteren Vorteil, da LSIF leicht in Tools oder Server integriert werden kann, die LSP bereits verstehen.
Werfen wir einen Blick auf ein Beispiel. Wir beginnen mit einer einfachen TypeScript-Datei namens sample.ts mit dem folgenden Inhalt
function bar(): void {}
Das Überfahren von bar() mit der Maus zeigt folgende Hover-Informationen in Visual Studio Code
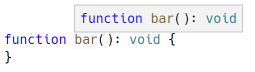
Diese Hover-Informationen werden in LSP mit dem Hover-Typ ausgedrückt
export interface Hover {
/**
* The hover's content
*/
contents: MarkupContent | MarkedString | MarkedString[];
/**
* An optional range
*/
range?: Range;
}
Im obigen Beispiel ist der konkrete Wert
{
contents: [{ language: 'typescript', value: 'function bar(): void' }];
}
Ein Client-Tool würde den Hover-Inhalt von einem Sprachserver abrufen, indem es eine textDocument/hover-Anfrage für das Dokument file:///Users/username/sample.ts an der Position {line: 0, character: 10} sendet.
LSIF definiert ein Format, das Sprachserver oder eigenständige Tools veröffentlichen, um zu beschreiben, dass das Tupel ['textDocument/hover', 'file:///Users/username/sample.ts', {line: 0, character: 10}] zu dem obigen Hover aufgelöst wird. Die Daten können dann in eine Datenbank übernommen und gespeichert werden.
LSP-Anfragen basieren auf Positionen, jedoch variieren die Ergebnisse oft nur für Bereiche und nicht für einzelne Positionen. Im obigen Hover-Beispiel ist der Hover-Wert für alle Positionen des Identifikators bar gleich. Das bedeutet, dass derselbe Hover-Wert zurückgegeben wird, wenn ein Benutzer mit der Maus über b in bar oder über r in bar fährt. Um die ausgegebenen Daten kompakter zu gestalten, verwendet LSIF Bereiche (Ranges) anstelle von Positionen. Für dieses Beispiel gibt ein LSIF-Tool das Tupel ['textDocument/hover', 'file:///Users/username/sample.ts', { start: { line: 0, character: 9 }, end: { line: 0, character: 12 }] aus, das Bereichsinformationen enthält.
LSIF verwendet Graphen zur Ausgabe dieser Informationen. Im Graphen wird eine LSP-Anfrage durch eine Kante dargestellt. Dokumente, Bereiche oder Anfrageergebnisse (z. B. der Hover) werden durch Knoten dargestellt. Dieses Format hat folgende Vorteile
- Für einen bestimmten Codebereich kann es unterschiedliche Ergebnisse geben. Für einen bestimmten Identifikationsbereich ist ein Benutzer am Hover-Wert, am Speicherort der Definition oder an "Finde alle Referenzen" interessiert. LSIF verknüpft diese Ergebnisse daher mit dem Bereich.
- Die Erweiterung des Formats um zusätzliche Anfragearten oder Ergebnisse kann einfach durch Hinzufügen neuer Kanten- oder Knotentypen erfolgen.
- Es ist möglich, Daten auszugeben, sobald sie verfügbar sind. Dies ermöglicht Streaming, anstatt große Datenmengen im Speicher speichern zu müssen. Zum Beispiel sollte die Ausgabe von Daten für ein Dokument für jede Datei erfolgen, während die Verarbeitung fortschreitet.
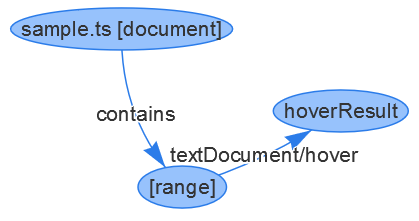
Für das Hover-Beispiel sehen die ausgegebenen LSIF-Graphdaten wie folgt aus
// a vertex representing the document
{ id: 1, type: "vertex", label: "document", uri: "file:///Users/username/sample.ts", languageId: "typescript" }
// a vertex representing the range for the identifier bar
{ id: 4, type: "vertex", label: "range", start: { line: 0, character: 9}, end: { line: 0, character: 12 } }
// an edge saying that the document with id 1 contains the range with id 4
{ id: 5, type: "edge", label: "contains", outV: 1, inV: 4}
// a vertex representing the actual hover result
{ id: 6, type: "vertex", label: "hoverResult",
result: {
contents: [
{ language: "typescript", value: "function bar(): void" }
]
}
}
// an edge linking the hover result to the range.
{ id: 7, type: "edge", label: "textDocument/hover", outV: 4, inV: 6 }
Der entsprechende Graph sieht so aus
LSP unterstützt auch Anfragen, die nur ein Dokument als Parameter nehmen (sie sind nicht positionsbasiert). Beispielanfragen, die für das Codeverständnis nützlich sind, sind eine Liste aller Dokumentsymbole oder die Berechnung aller Faltungsbereiche (folding ranges). Diese Anfragen werden in LSIF in der Form [Anfrage, Dokument] -> Ergebnis modelliert.
Schauen wir uns ein weiteres Beispiel an
function bar(): void {
console.log('Hello World!');
}
Das Ergebnis der Faltungsbereiche für das Dokument, das die obige Funktion bar enthält, wird wie folgt ausgegeben
// a vertex representing the document
{ id: 1, type: "vertex", label: "document", uri: "file:///Users/username/sample.ts", languageId: "typescript" }
// a vertex representing the folding result
{ id: 2, type: "vertex", label: "foldingRangeResult", result: [ { startLine: 0, startCharacter: 20, endLine: 2, endCharacter: 1 } ] }
// an edge connecting the folding result to the document.
{ id: 3, type: "edge", label: "textDocument/foldingRange", outV: 1, inV: 2 }

Dies sind nur zwei Beispiele für LSP-Anfragen, die von LSIF unterstützt werden. Die aktuelle Version der LSIF-Spezifikation unterstützt auch Dokumentsymbole, Dokumentenlinks, "Gehe zu Definition", "Gehe zu Deklaration", "Gehe zu Typdefinition", "Finde alle Referenzen" und "Gehe zu Implementierung".
Wir brauchen Ihr Feedback!
Wir haben gute Fortschritte bei der LSIF-Spezifikation gemacht und möchten die Diskussion mit der Community öffnen, damit Sie erfahren können, woran wir arbeiten. Für Feedback kommentieren Sie bitte das Issue Language Server Index Format.
Erste Schritte
Um mit LSIF zu beginnen, können Sie sich die folgenden Ressourcen ansehen
- Die LSIF-Spezifikation - Das Dokument beschreibt auch einige zusätzliche Optimierungen, die vorgenommen wurden, um die ausgegebenen Daten kompakt zu halten.
- LSIF Index für TypeScript - Ein Tool, das LSIF für TypeScript generiert. Die README-Datei enthält Anleitungen zur Verwendung des Tools.
- Visual Studio Code Erweiterung für LSIF - Eine Erweiterung für VS Code, die Sprachverständnisfunktionen mithilfe eines LSIF JSON-Dumps bereitstellt. Wenn Sie einen neuen LSIF-Generator implementieren, können Sie diese Erweiterung verwenden, um ihn mit beliebiger Quellcode zu validieren.