Neuer Textpuffer: Neuimplementierung
23. März 2018 von Peng Lyu, @njukidreborn
Das Release 1.21 von Visual Studio Code enthält eine brandneue Implementierung des Textpuffers, die deutlich leistungsfähiger ist, sowohl in Bezug auf Geschwindigkeit als auch auf Speicherverbrauch. In diesem Blogbeitrag möchte ich die Geschichte erzählen, wie wir die Datenstrukturen und Algorithmen ausgewählt und entworfen haben, die zu diesen Verbesserungen geführt haben.
Leistungsdiskussionen über JavaScript-Programme beinhalten normalerweise die Diskussion darüber, wie viel in nativem Code implementiert werden sollte. Für den VS Code-Textpuffer begannen diese Diskussionen vor über einem Jahr. Während einer eingehenden Untersuchung stellten wir fest, dass eine C++-Implementierung des Textpuffers zu erheblichen Speichereinsparungen führen könnte, aber wir sahen nicht die erhofften Leistungssteigerungen. Das Konvertieren von Zeichenfolgen zwischen einer benutzerdefinierten nativen Darstellung und V8s Zeichenfolgen ist kostspielig und beeinträchtigte in unserem Fall jede Leistung, die durch die Implementierung von Textpufferoperationen in C++ erzielt wurde. Wir werden dies ausführlicher am Ende dieses Beitrags besprechen.
Da wir uns nicht für die native Implementierung entschieden haben, mussten wir Wege finden, unseren JavaScript/TypeScript-Code zu verbessern. Inspirierende Blogbeiträge wie dieser von Vyacheslav Egorov zeigen Wege auf, eine JavaScript-Engine an ihre Grenzen zu bringen und so viel Leistung wie möglich herauszuholen. Selbst ohne Low-Level-Engine-Tricks ist es immer noch möglich, die Geschwindigkeit um eine oder mehrere Größenordnungen zu verbessern, indem besser geeignete Datenstrukturen und schnellere Algorithmen verwendet werden.
Vorherige Datenstruktur des Textpuffers
Das mentale Modell eines Editors ist zeilenbasiert. Entwickler lesen und schreiben Quellcode Zeile für Zeile, Compiler liefern zeilen-/spaltenbasierte Diagnosen, Stack-Traces enthalten Zeilennummern, Tokenizer-Engines laufen Zeile für Zeile usw. Obwohl einfach, hatte die Textpufferimplementierung, die VS Code antreibt, seit dem ersten Tag, an dem wir das Monaco-Projekt gestartet haben, nicht viel geändert. Wir verwendeten ein Array von Zeilen, und es funktionierte ziemlich gut, da typische Textdokumente relativ klein sind. Wenn der Benutzer tippte, fanden wir die zu ändernde Zeile im Array und ersetzten sie. Beim Einfügen einer neuen Zeile fügten wir ein neues Zeilenobjekt in das Zeilenarray ein und die JavaScript-Engine erledigte die Hauptarbeit für uns.
Wir erhielten jedoch weiterhin Berichte, dass das Öffnen bestimmter Dateien zu Out-Of-Memory-Abstürzen in VS Code führte. Zum Beispiel konnte ein Benutzer eine 35 MB-Datei nicht öffnen. Die Ursache war, dass die Datei zu viele Zeilen hatte, nämlich 13,7 Millionen. Wir würden für jede Zeile ein ModelLine-Objekt erstellen, und jedes Objekt verbrauchte etwa 40-60 Bytes, sodass das Zeilenarray etwa 600 MB Speicher zum Speichern des Dokuments verbrauchte. Das ist etwa das 20-fache der ursprünglichen Dateigröße!
Ein weiteres Problem mit der Zeilenarray-Darstellung war die Geschwindigkeit beim Öffnen einer Datei. Um das Zeilenarray zu erstellen, mussten wir den Inhalt nach Zeilenumbrüchen aufteilen, so dass wir pro Zeile ein Zeichenkettenobjekt erhielten. Das Aufteilen selbst beeinträchtigt die Leistung, wie Sie in den folgenden Benchmarks sehen werden.
Finden einer neuen Textpufferimplementierung
Die alte Zeilenarray-Darstellung kann viel Zeit für die Erstellung benötigen und viel Speicher verbrauchen, bietet aber eine schnelle Zeilensuche. In einer perfekten Welt würden wir nur den Text der Datei und keine zusätzlichen Metadaten speichern. Daher begannen wir, nach Datenstrukturen zu suchen, die weniger Metadaten benötigen. Nach der Überprüfung verschiedener Datenstrukturen stellte ich fest, dass Piece Table ein guter Kandidat zum Anfang sein könnte.
Vermeidung von zu vielen Metadaten durch Verwendung eines Piece Table
Ein Piece Table ist eine Datenstruktur, die zur Darstellung einer Reihe von Bearbeitungen an einem Textdokument (Quellcode in TypeScript) verwendet wird.
class PieceTable {
original: string; // original contents
added: string; // user added contents
nodes: Node[];
}
class Node {
type: NodeType;
start: number;
length: number;
}
enum NodeType {
Original,
Added
}
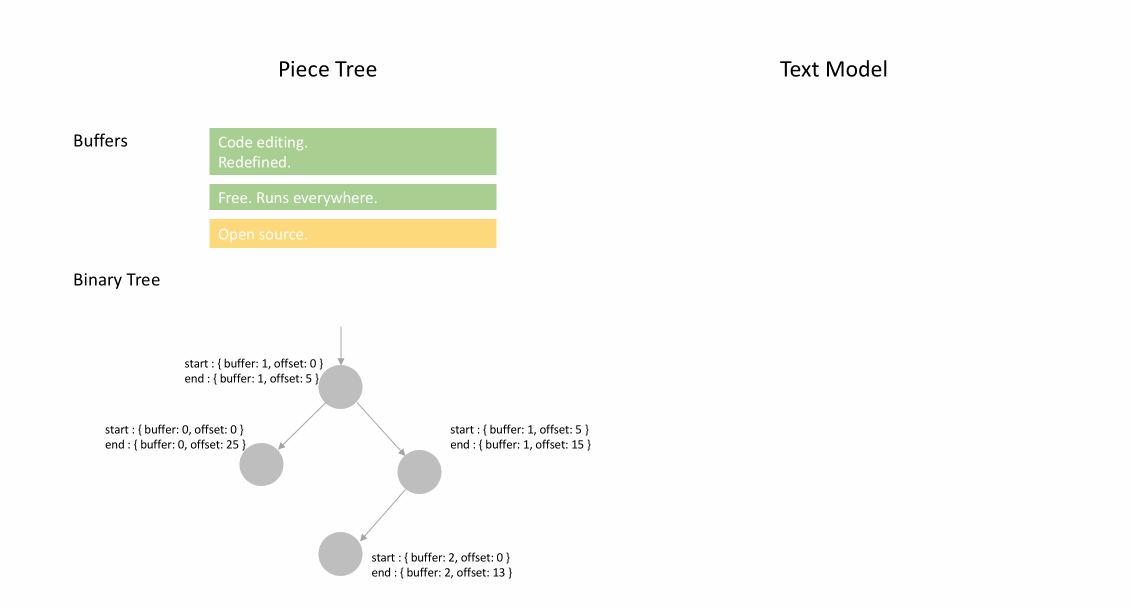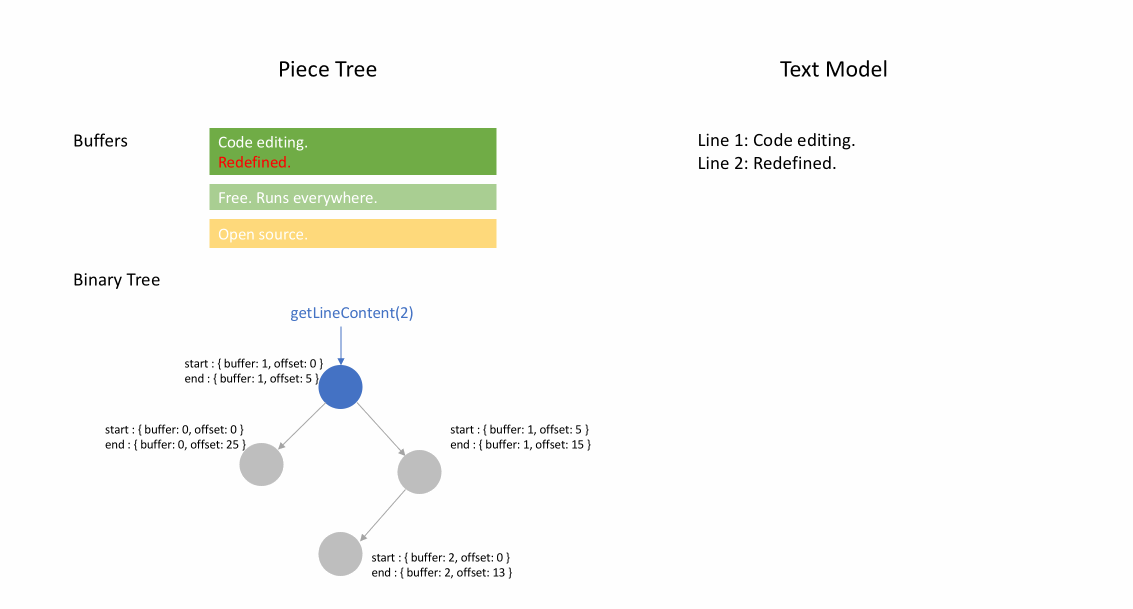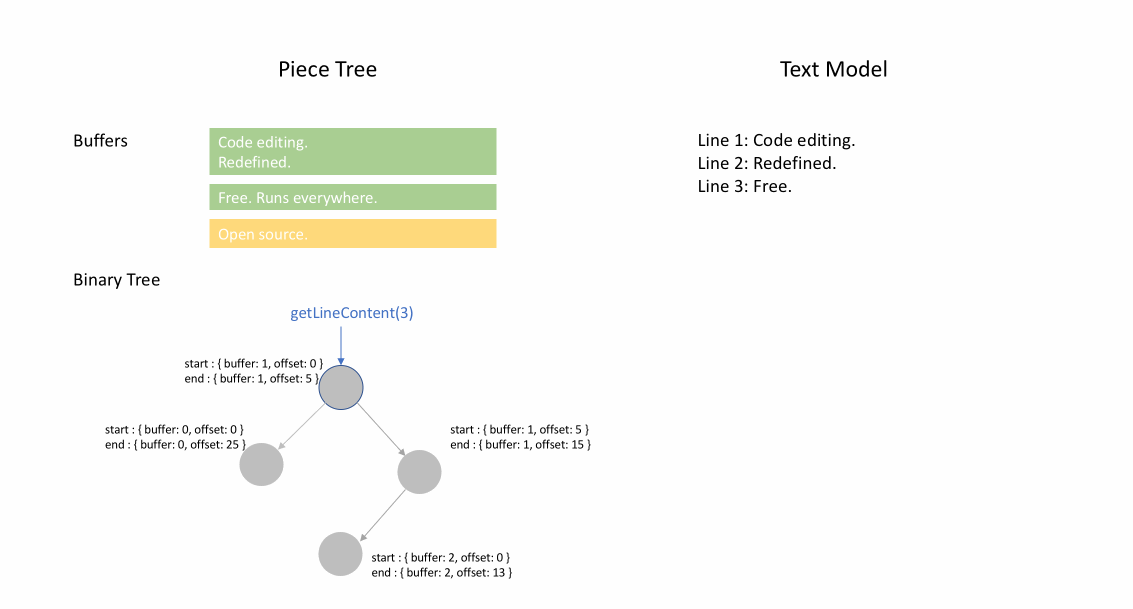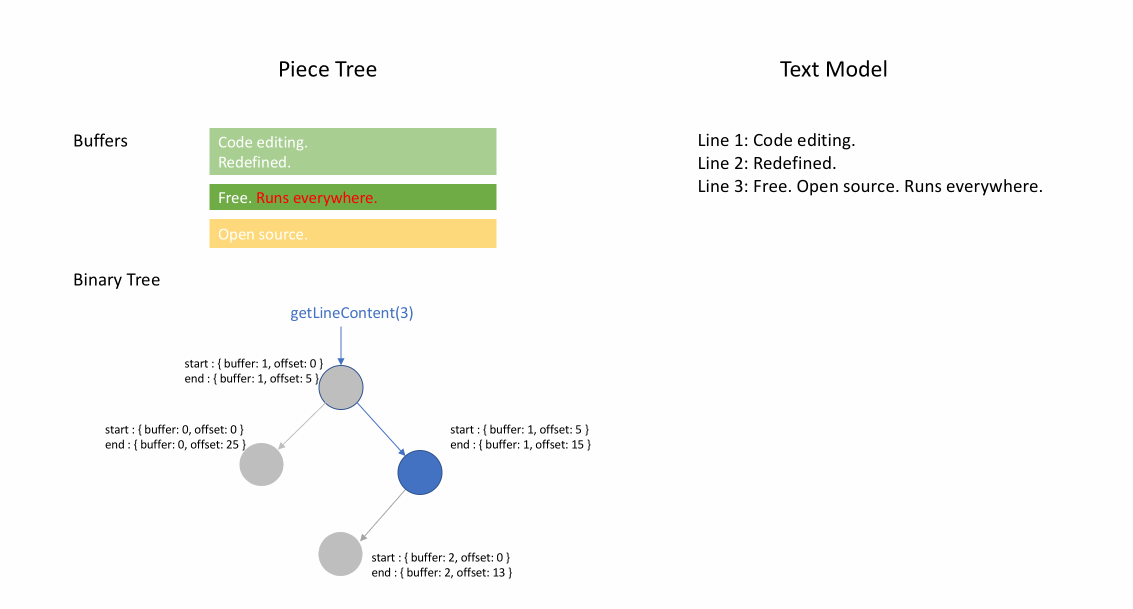
Nachdem die Datei initial geladen wurde, enthält der Piece Table den gesamten Dateiinhalt im original-Feld. Das added-Feld ist leer. Es gibt einen einzelnen Knoten vom Typ NodeType.Original. Wenn ein Benutzer am Ende einer Datei tippt, fügen wir den neuen Inhalt an das added-Feld an und fügen am Ende der Knoteliste einen neuen Knoten vom Typ NodeType.Added ein. Ebenso, wenn ein Benutzer Bearbeitungen in der Mitte eines Knotens vornimmt, teilen wir diesen Knoten auf und fügen bei Bedarf einen neuen ein.
Die folgende Animation zeigt, wie auf das Dokument Zeile für Zeile in einer Piece-Table-Struktur zugegriffen wird. Sie hat zwei Puffer (original und added) und drei Knoten (was durch eine Einfügung in der Mitte des original-Inhalts verursacht wird).
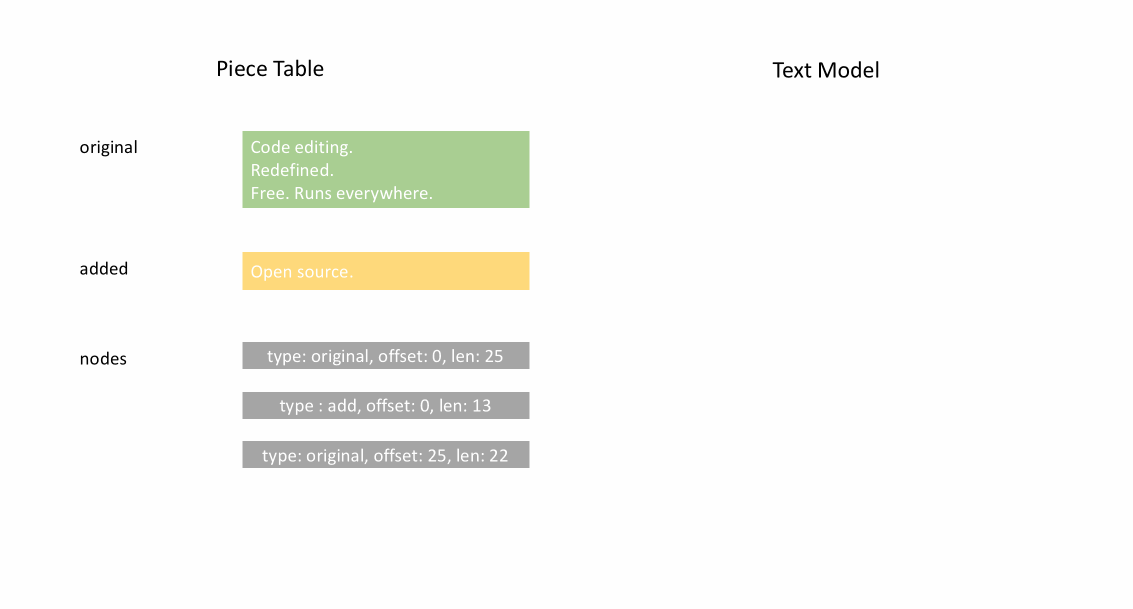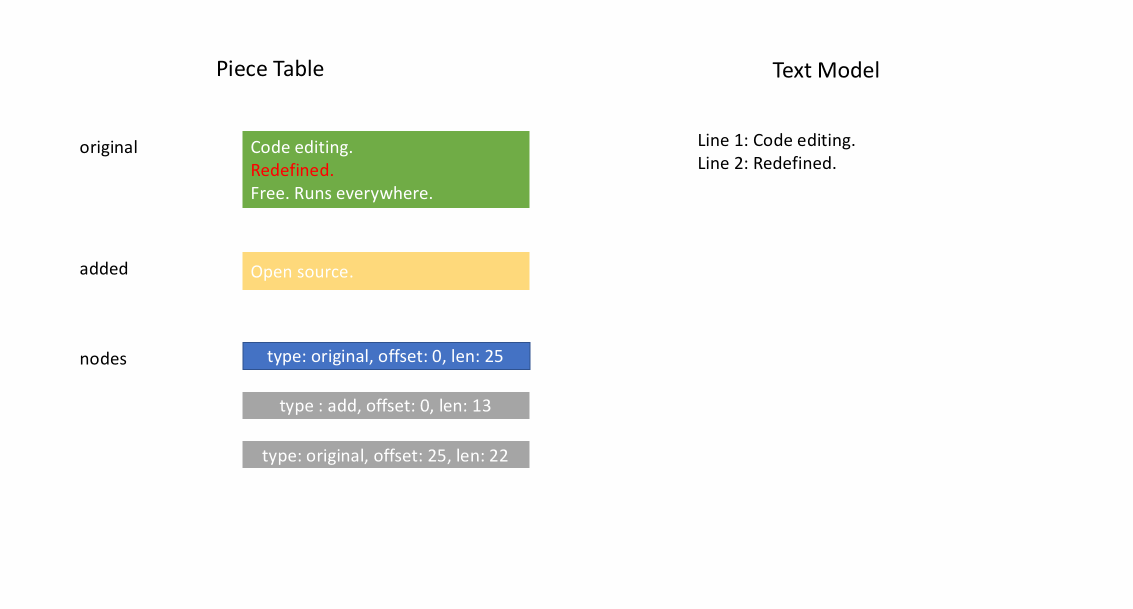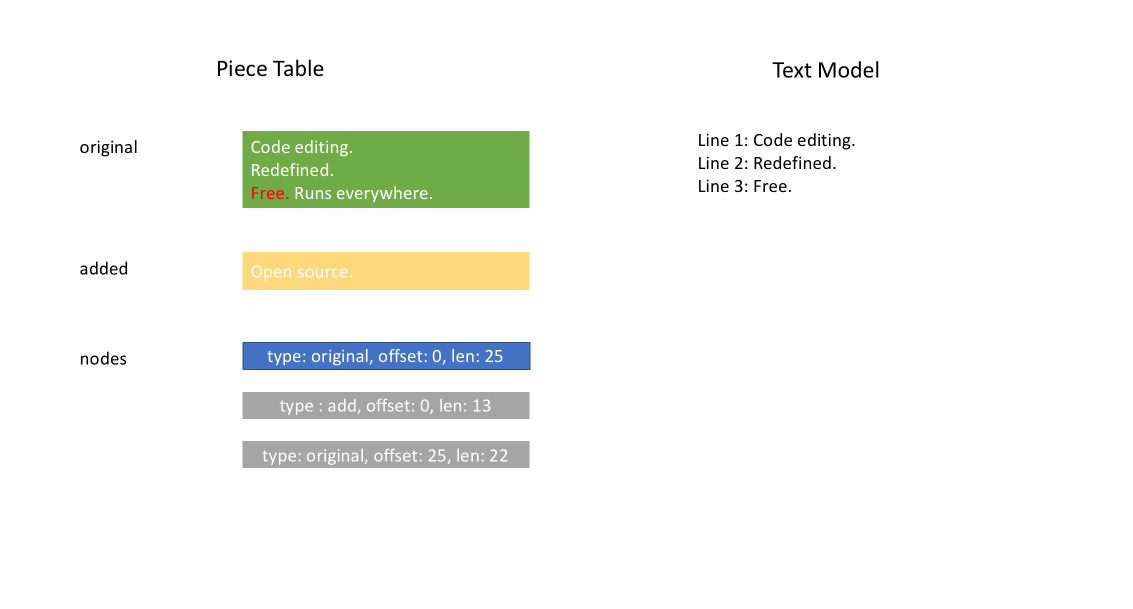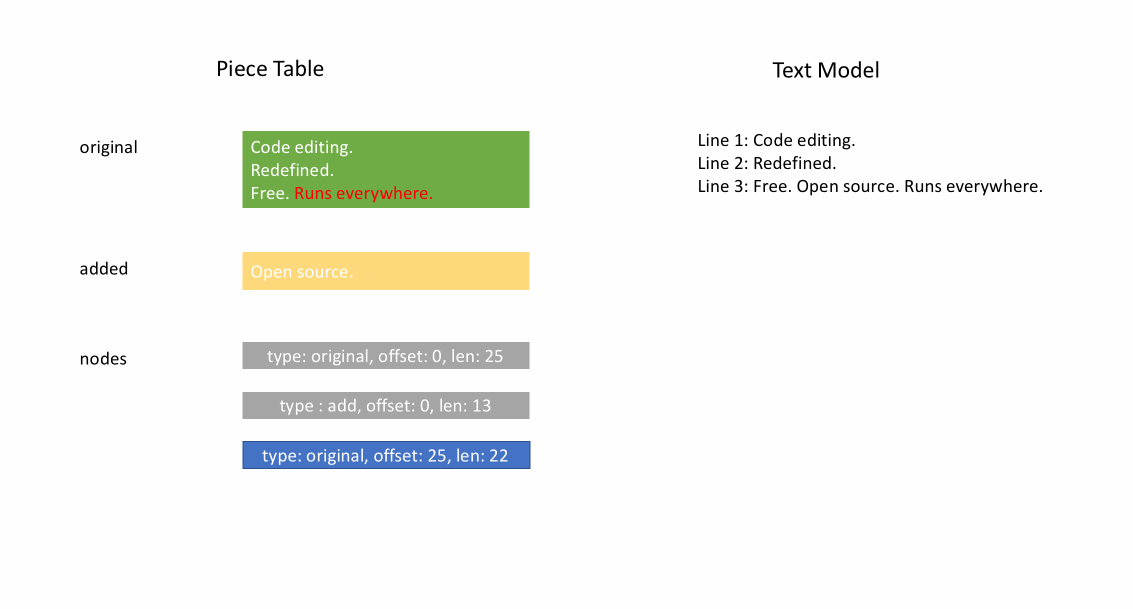
Die anfängliche Speichernutzung eines Piece Tables liegt nahe an der Größe des Dokuments, und der für Modifikationen benötigte Speicher ist proportional zur Anzahl der Bearbeitungen und des hinzugefügten Textes. Daher ist ein Piece Table typischerweise speichereffizient. Der Preis für die geringe Speichernutzung ist jedoch, dass der Zugriff auf eine logische Zeile langsam ist. Wenn Sie beispielsweise den Inhalt der 1000. Zeile abrufen möchten, ist der einzige Weg, über jedes Zeichen vom Anfang des Dokuments aus zu iterieren, die ersten 999 Zeilenumbrüche zu finden und jedes Zeichen bis zum nächsten Zeilenumbruch zu lesen.
Verwendung von Caching für schnellere Zeilensuche
Die traditionellen Piece-Table-Knoten enthalten nur Offsets, aber wir können Zeilenumbruchinformationen hinzufügen, um den Zeileninhalt schneller abzurufen. Der intuitive Weg, Zeilenumbruchpositionen zu speichern, ist die Speicherung der Offsets für jeden Zeilenumbruch, der im Text eines Knotens gefunden wird.
class PieceTable {
original: string;
added: string;
nodes: Node[];
}
class Node {
type: NodeType;
start: number;
length: number;
lineStarts: number[];
}
enum NodeType {
Original,
Added
}
Wenn Sie beispielsweise auf die zweite Zeile einer gegebenen Node-Instanz zugreifen möchten, können Sie node.lineStarts[0] und node.lineStarts[1] lesen, was die relativen Offsets liefert, an denen eine Zeile beginnt und endet. Da wir wissen, wie viele Zeilenumbrüche ein Knoten hat, ist der Zugriff auf eine beliebige Zeile im Dokument geradlinig: Lesen Sie jeden Knoten beginnend mit dem ersten, bis wir den Zielzeilenumbruch finden.
Der Algorithmus bleibt einfach und funktioniert besser als zuvor, da wir nun ganze Textblöcke überspringen können, anstatt Zeichen für Zeichen zu iterieren. Wir werden später sehen, dass wir es noch besser machen können.
Vermeiden der String-Konkatenationsfalle
Der Piece Table hält zwei Puffer, einen für den ursprünglichen Inhalt, der von der Festplatte geladen wurde, und einen für Benutzerbearbeitungen. In VS Code laden wir Textdateien mit Node.js fs.readFile, das Inhalte in 64-KB-Blöcken liefert. Wenn die Datei groß ist, zum Beispiel 64 MB, erhalten wir 1000 Blöcke. Nachdem wir alle Blöcke erhalten haben, können wir sie zu einer großen Zeichenkette verketten und im original-Feld des Piece Tables speichern.
Das klingt vernünftig, bis V8 Ihnen in die Quere kommt. Ich habe versucht, eine 500-MB-Datei zu öffnen und erhielt eine Ausnahme, da in der von mir verwendeten V8-Version die maximale Zeichenkettenlänge 256 MB beträgt. Dieses Limit wird in zukünftigen Versionen von V8 auf 1 GB angehoben, aber das löst das Problem nicht wirklich.
Anstatt eines original- und eines added-Puffers können wir eine Liste von Puffern halten. Wir können versuchen, diese Liste kurz zu halten, oder wir können uns davon inspirieren lassen, was wir von fs.readFile zurückbekommen, und jegliche Zeichenkettenverkettung vermeiden. Jedes Mal, wenn wir einen 64-KB-Block von der Festplatte erhalten, fügen wir ihn direkt zum buffers-Array hinzu und erstellen einen Knoten, der auf diesen Puffer verweist.
class PieceTable {
buffers: string[];
nodes: Node[];
}
class Node {
bufferIndex: number;
start: number; // start offset in buffers[bufferIndex]
length: number;
lineStarts: number[];
}
Verbesserung der Zeilensuche durch Verwendung eines balancierten Binärbaums
Nachdem die Zeichenkettenverkettung wegfällt, können wir nun große Dateien öffnen, aber das führt uns zu einem weiteren potenziellen Leistungsproblem. Nehmen wir an, wir laden eine 64-MB-Datei, der Piece Table hat 1000 Knoten. Auch wenn wir die Zeilenumbruchpositionen in jedem Knoten zwischenspeichern, wissen wir nicht, welche absolute Zeilennummer sich in welchem Knoten befindet. Um den Inhalt einer Zeile abzurufen, müssen wir alle Knoten durchlaufen, bis wir den Knoten finden, der diese Zeile enthält. In unserem Beispiel müssen wir je nach gesuchter Zeilennummer bis zu 1000 Knoten durchlaufen. Somit ist die Zeitkomplexität des Worst-Case O(N) (N ist die Anzahl der Knoten).
Das Zwischenspeichern der absoluten Zeilennummern in jedem Knoten und die Verwendung der binären Suche in der Liste der Knoten beschleunigt die Suchgeschwindigkeit, aber wann immer wir einen Knoten modifizieren, müssen wir alle folgenden Knoten besuchen, um die Zeilennummer-Delta anzuwenden. Das ist ein No-Go, aber die Idee der binären Suche ist gut. Um denselben Effekt zu erzielen, können wir einen balancierten Binärbaum nutzen.
Nun müssen wir entscheiden, welche Metadaten wir als Schlüssel für den Vergleich von Baumknoten verwenden sollen. Wie bereits erwähnt, führt die Verwendung des Knotens-Offsets im Dokument oder der absoluten Zeilennummer zu einer Zeitkomplexität von Bearbeitungsoperationen von O(N). Wenn wir eine Zeitkomplexität von O(log n) wünschen, benötigen wir etwas, das nur mit dem Teilbaum eines Baumknotens zusammenhängt. Daher berechnen wir bei der Bearbeitung von Text durch einen Benutzer die Metadaten für die geänderten Knoten neu und leiten dann die Metadatenänderung über die übergeordneten Knoten bis zur Wurzel weiter.
Wenn ein Node nur vier Eigenschaften hat (bufferIndex, start, length, lineStarts), dauert die Suche nach dem Ergebnis Sekunden. Um schneller zu werden, können wir auch die Textlänge und die Anzahl der Zeilenumbrüche des linken Teilbaums eines Knotens speichern. Auf diese Weise kann die Suche nach Offset oder Zeilennummer vom Wurzel des Baums aus effizient sein. Das Speichern von Metadaten des rechten Teilbaums ist dasselbe, aber wir müssen nicht beide zwischenspeichern.
Die Klassen sehen jetzt so aus
class PieceTable {
buffers: string[];
rootNode: Node;
}
class Node {
bufferIndex: number;
start: number;
length: number;
lineStarts: number[];
left_subtree_length: number;
left_subtree_lfcnt: number;
left: Node;
right: Node;
parent: Node;
}
Unter allen verschiedenen Arten von balancierten Binärbäumen wählen wir den Rot-Schwarz-Baum, weil er "bearbeitungsfreundlicher" ist.
Reduzierung der Objektallokation
Angenommen, wir speichern die Zeilenumbruch-Offsets in jedem Knoten. Jedes Mal, wenn wir den Knoten ändern, müssen wir möglicherweise die Zeilenumbruch-Offsets aktualisieren. Wenn wir beispielsweise einen Knoten haben, der 999 Zeilenumbrüche enthält, hat das lineStarts-Array 1000 Elemente. Wenn wir den Knoten gleichmäßig aufteilen, erstellen wir zwei Knoten, von denen jeder ein Array mit etwa 500 Elementen hat. Da wir nicht direkt auf linearem Speicherplatz arbeiten, ist das Aufteilen eines Arrays in zwei mehr Aufwand als nur das Verschieben von Zeigern.
Die gute Nachricht ist, dass die Puffer in einem Piece Table entweder schreibgeschützt (Originalpuffer) oder anhängbar (geänderte Puffer) sind, sodass sich die Zeilenumbrüche innerhalb eines Puffers nicht verschieben. Node kann einfach zwei Referenzen auf die Zeilenumbruch-Offsets in seinem entsprechenden Puffer halten. Weniger tun wir, desto besser ist die Leistung. Unsere Benchmarks zeigten, dass die Anwendung dieser Änderung die Textpufferoperationen in unserer Implementierung dreimal schneller machte. Aber mehr über die tatsächliche Implementierung später.
class Buffer {
value: string;
lineStarts: number[];
}
class BufferPosition {
index: number; // index in Buffer.lineStarts
remainder: number;
}
class PieceTable {
buffers: Buffer[];
rootNode: Node;
}
class Node {
bufferIndex: number;
start: BufferPosition;
end: BufferPosition;
...
}
Piece Tree
Ich würde diesen Textpuffer gerne **"Mehrpuffer-Piece-Table mit Rot-Schwarz-Baum, optimiert für das Zeilenmodell"** nennen. Aber bei unseren täglichen Stand-ups, wenn jeder nur 90 Sekunden Zeit hat, um zu teilen, was er getan hat, wäre es nicht ratsam, diesen langen Namen mehrmals zu wiederholen. Also habe ich angefangen, ihn einfach **"Piece Tree"** zu nennen, was widerspiegelt, was er ist.
Ein theoretisches Verständnis dieser Datenstruktur zu haben ist eine Sache, reale Leistung eine andere. Die Sprache, die Sie verwenden, die Umgebung, in der der Code ausgeführt wird, die Art und Weise, wie Clients Ihre API aufrufen, und andere Faktoren können das Ergebnis erheblich beeinflussen. Benchmarks können ein umfassendes Bild liefern, also haben wir Benchmarks auf kleinen/mittleren/großen Dateien gegen die ursprüngliche Zeilenarray-Implementierung und die Piece-Tree-Implementierung durchgeführt.
Vorbereitungen
Zur Darstellung der Ergebnisse habe ich nach realistischen Dateien online gesucht
- checker.ts - 1,46 MB, 26k Zeilen.
- sqlite.c - 4,31 MB, 128k Zeilen.
- Russisch-Englisches zweisprachiges Wörterbuch - 14 MB, 552k Zeilen.
und manuell ein paar große Dateien erstellt
- Chromium Heap-Snapshot eines neu geöffneten VS Code Insiders - 54 MB, 3 Mio. Zeilen.
- checker.ts X 128 - 184 MB, 3 Mio. Zeilen.
1. Speichernutzung
Der Speicherverbrauch des Piece Trees unmittelbar nach dem Laden liegt sehr nahe an der ursprünglichen Dateigröße und ist deutlich geringer als bei der alten Implementierung. Erste Runde, Piece Tree gewinnt.
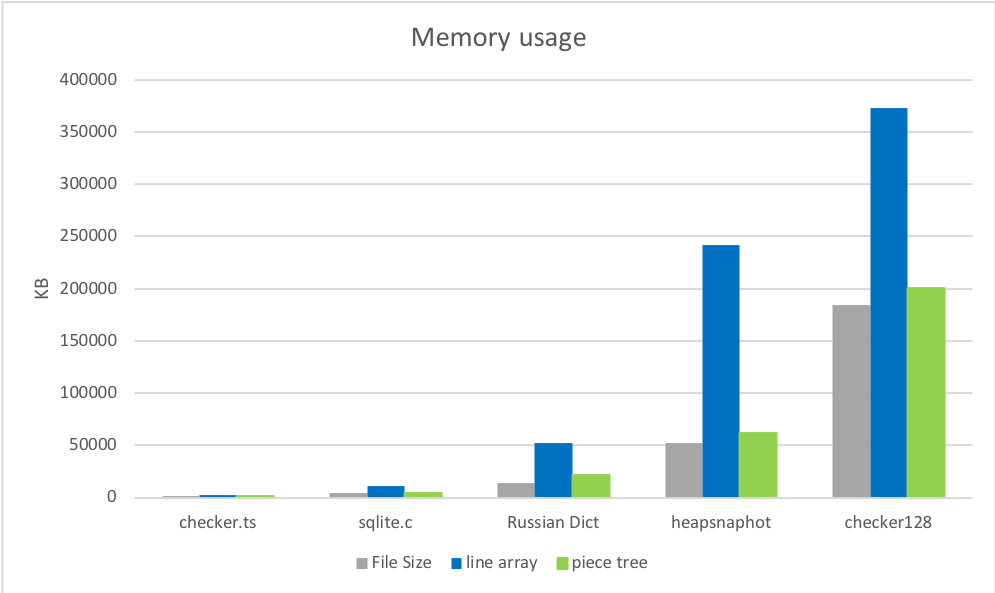
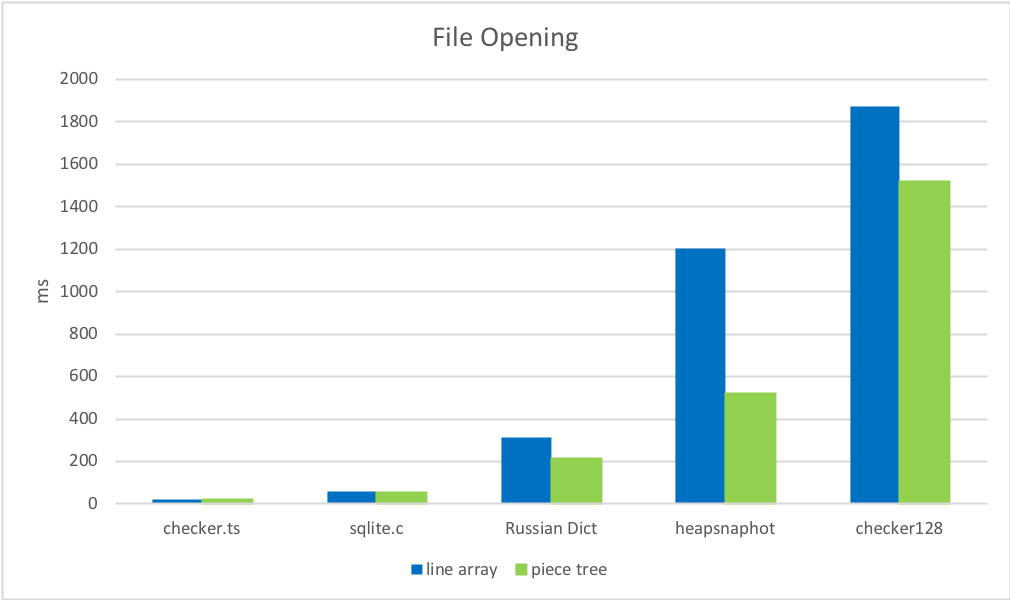
2. Dateieröffnungszeiten
Das Finden und Zwischenspeichern von Zeilenumbrüchen ist viel schneller als das Aufteilen der Datei in ein Array von Zeichenketten.
3. Bearbeitung
Ich habe zwei Workflows simuliert
- Bearbeitungen an zufälligen Positionen im Dokument vornehmen.
- Nacheinander tippen.
Ich habe versucht, diese beiden Szenarien nachzubilden: 1000 zufällige Bearbeitungen anwenden oder 1000 sequentielle Einfügungen in das Dokument vornehmen und dann sehen, wie viel Zeit jeder Textpuffer benötigt.
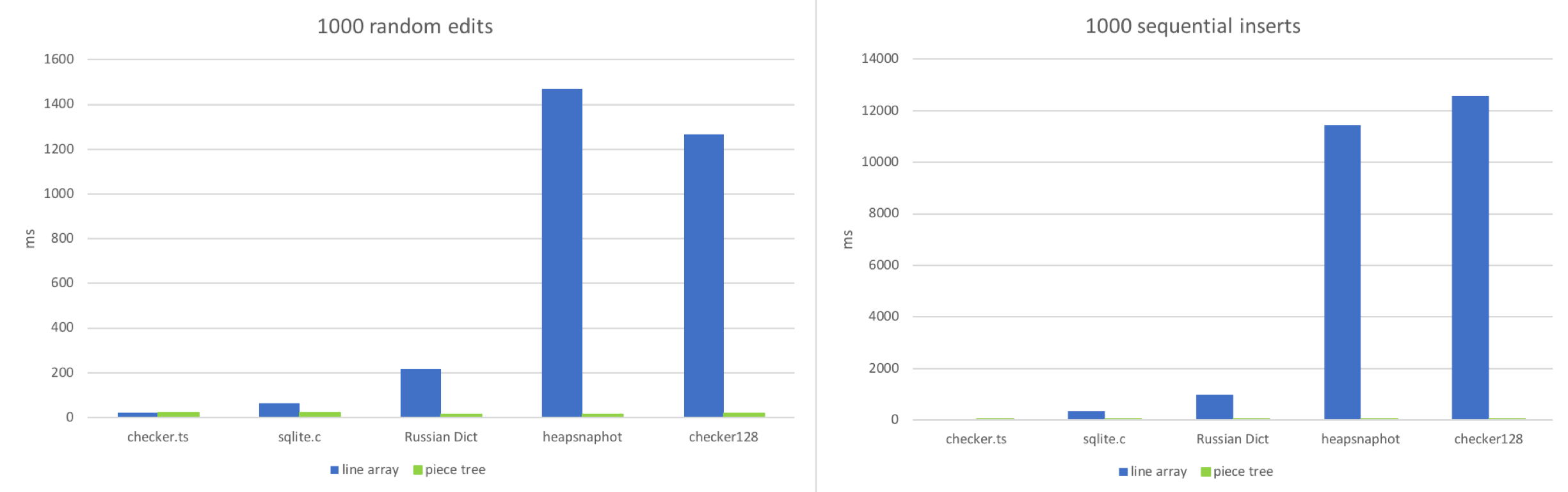
Wie erwartet gewinnt das Zeilenarray bei sehr kleinen Dateien. Der Zugriff auf eine zufällige Position in einem kleinen Array und die Anpassung einer Zeichenkette mit etwa 100-150 Zeichen ist wirklich schnell. Das Zeilenarray beginnt zu versagen, wenn die Datei viele Zeilen hat (100k+). Sequentielle Einfügungen in großen Dateien verschlimmern diese Situation, da die JavaScript-Engine viel Arbeit leistet, um das große Array zu vergrößern. Der Piece Tree verhält sich stabil, da jede Bearbeitung nur ein Anhängen von Zeichenketten und ein paar Rot-Schwarz-Baum-Operationen ist.
4. Lesen
Für unsere Textpuffer ist die am häufigsten aufgerufene Methode getLineContent. Sie wird vom View-Code, vom Tokenizer, vom Link-Detektor und praktisch jeder Komponente aufgerufen, die auf den Dokumentinhalt angewiesen ist. Einige Teile des Codes durchlaufen die gesamte Datei, wie der Link-Detektor, während andere Teile nur ein Fenster von aufeinanderfolgenden Zeilen lesen, wie der View-Code. Also habe ich diese Methode in verschiedenen Szenarien benchmarken lassen.
- Rufen Sie
getLineContentfür alle Zeilen nach 1000 zufälligen Bearbeitungen auf. - Rufen Sie
getLineContentfür alle Zeilen nach 1000 sequentiellen Einfügungen auf. - Lesen Sie 10 verschiedene Zeilenfenster nach 1000 zufälligen Bearbeitungen.
- Lesen Sie 10 verschiedene Zeilenfenster nach 1000 sequentiellen Einfügungen.
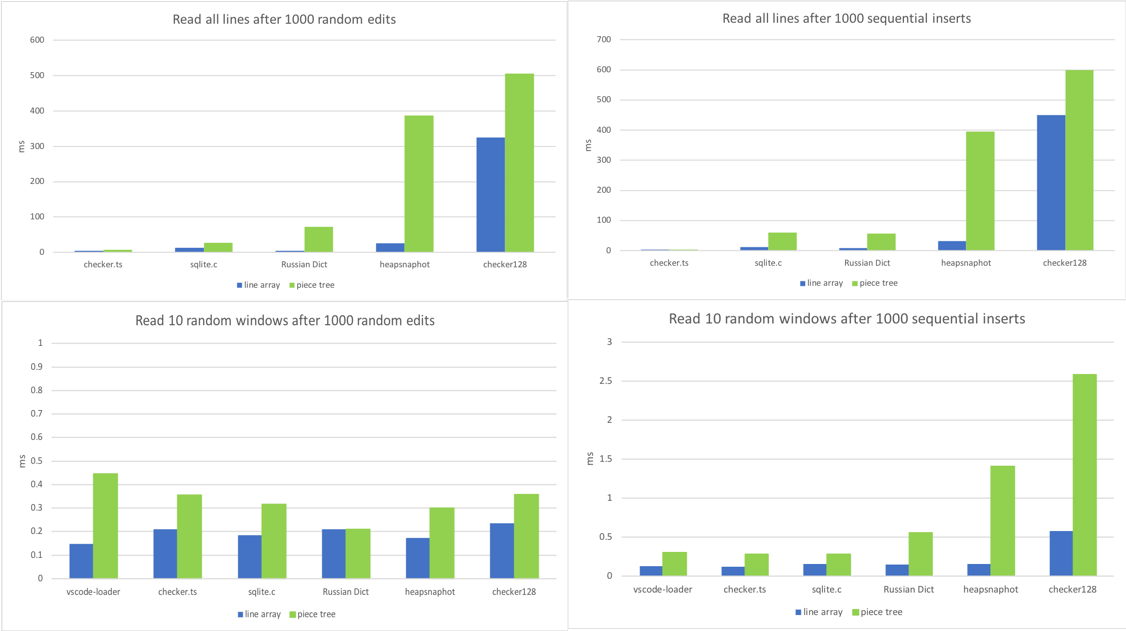
TA DA, wir haben die Achillesferse des Piece Trees gefunden. Eine große Datei mit Tausenden von Bearbeitungen führt zu Tausenden oder Zehntausenden von Knoten. Auch wenn die Suche nach einer Zeile O(log N) ist, wobei N die Anzahl der Knoten ist, ist das deutlich mehr als O(1), das das Zeilenarray bot.
Tausende von Bearbeitungen sind relativ selten. Sie können dort nach dem Ersetzen einer häufig vorkommenden Zeichenfolge in einer großen Datei landen. Außerdem sprechen wir hier von Mikrosekunden pro getLineContent-Aufruf, sodass wir uns im Moment keine Sorgen machen müssen. Die meisten getLineContent-Aufrufe stammen aus der View-Renderung und Tokenisierung, und die Nachbearbeitung der Zeileninhalte ist viel zeitaufwendiger. DOM-Konstruktion und -Rendering oder Tokenisierung eines Viewports dauern normalerweise Dutzende von Millisekunden, wobei getLineContent nur weniger als 1 % ausmacht. Dennoch erwägen wir, einen Normalisierungsschritt zu implementieren, bei dem wir Puffer und Knoten neu erstellen würden, wenn bestimmte Bedingungen wie eine hohe Anzahl von Knoten erfüllt sind.
Fazit und Fallstricke
Der Piece Tree übertrifft das Zeilenarray in den meisten Szenarien, mit Ausnahme der zeilenbasierten Suche, was zu erwarten war.
Gelernte Lektionen
- Die wichtigste Lektion, die mir diese Neuimplementierung beigebracht hat, ist, **immer reale Profilerstellung durchzuführen**. Jedes Mal stellte ich fest, dass meine Annahmen darüber, welche Methoden heiß sein würden, nicht mit der Realität übereinstimmten. Als ich mit der Piece-Tree-Implementierung begann, konzentrierte ich mich beispielsweise auf die Optimierung der drei atomaren Operationen:
insert,deleteundsearch. Aber als ich es in VS Code integrierte, waren keine dieser Optimierungen wichtig. Die heißeste Methode wargetLineContent. - **Der Umgang mit
CRLFoder gemischten Zeilenumbruchsequenzen ist ein Albtraum für Programmierer**. Bei jeder Änderung müssen wir prüfen, ob sie eine Carriage Return/Line Feed (CRLF)-Sequenz teilt oder ob sie eine neue CRLF-Sequenz erzeugt. Der Umgang mit allen möglichen Fällen im Kontext eines Baums erforderte mehrere Versuche, bis ich eine Lösung hatte, die korrekt und schnell war. - **GC kann leicht Ihre CPU-Zeit fressen**. Unser Textmodell ging früher davon aus, dass der Puffer in einem Array gespeichert ist, und wir verwenden häufig
getLineContent, auch wenn es manchmal nicht notwendig war. Wenn wir beispielsweise nur den Zeichencode des ersten Zeichens einer Zeile wissen möchten, verwendeten wir zuerstgetLineContentund danncharCodeAt. Mit dem Piece Tree erstelltgetLineContenteinen Unterstring, und nachdem der Zeichencode überprüft wurde, wird der Zeilenunterstring sofort verworfen. Das ist verschwenderisch, und wir arbeiten daran, besser geeignete Methoden zu übernehmen.
Warum nicht nativ?
Ich habe am Anfang versprochen, auf diese Frage zurückzukommen.
**TL;DR**: Wir haben es versucht. Es hat für uns nicht funktioniert.
Wir haben eine Textpufferimplementierung in C++ erstellt und native Node-Modul-Bindings verwendet, um sie in VS Code zu integrieren. Der Textpuffer ist eine beliebte Komponente in VS Code, und daher wurden viele Aufrufe an den Textpuffer gemacht. Als sowohl der Aufrufer als auch die Implementierung in JavaScript geschrieben waren, konnte V8 viele dieser Aufrufe inline schalten. Mit einem nativen Textpuffer gibt es **JavaScript <=> C++**-Roundtrips, und angesichts der Anzahl von Roundtrips verlangsamten sie alles.
Zum Beispiel wird der Befehl **Toggle Line Comment** in VS Code implementiert, indem alle ausgewählten Zeilen durchlaufen und einzeln analysiert werden. Diese Logik ist in JavaScript geschrieben und ruft für jede Zeile TextBuffer.getLineContent auf. Für jeden Aufruf überqueren wir die C++/JavaScript-Grenze und müssen eine JavaScript-string zurückgeben, um die API zu respektieren, auf der all unser Code aufgebaut ist.
Unsere Optionen sind einfach. In C++ können wir entweder bei jedem Aufruf von getLineContent eine neue JavaScript-string zuweisen, was das Kopieren der eigentlichen Zeichenketten-Bytes bedeutet, oder wir nutzen V8s SlicedString- oder ConstString-Typen. V8s Zeichentypen können wir jedoch nur verwenden, wenn unser zugrunde liegender Speicher ebenfalls V8-Zeichenketten verwendet. Leider sind V8-Zeichenketten nicht threadsicher.
Wir hätten versuchen können, dies zu überwinden, indem wir die TextBuffer-API ändern oder mehr und mehr Code nach C++ verschieben, um die Kosten der JavaScript/C++-Grenze zu vermeiden. Wir haben jedoch erkannt, dass wir zwei Dinge gleichzeitig taten: Wir schrieben einen Textpuffer mit einer anderen Datenstruktur als einem Zeilenarray und wir schrieben ihn in C++ anstatt in JavaScript. Anstatt also ein halbes Jahr für etwas auszugeben, von dem wir nicht wussten, ob es sich auszahlen würde, haben wir beschlossen, die Laufzeit des Textpuffers in JavaScript zu belassen und nur die Datenstruktur und die zugehörigen Algorithmen zu ändern. Unserer Meinung nach war das die richtige Entscheidung.
Zukünftige Arbeit
Wir haben noch eine Handvoll Fälle, die optimiert werden müssen. Zum Beispiel läuft der **Find**-Befehl derzeit Zeile für Zeile, sollte es aber nicht. Wir können auch unnötige Aufrufe von getLineContent vermeiden, wenn nur ein Zeilen-Substring benötigt wird. Wir werden diese Optimierungen schrittweise veröffentlichen. Selbst ohne diese weiteren Optimierungen bietet die neue Textpufferimplementierung eine bessere Benutzererfahrung als zuvor und ist jetzt die Standardeinstellung in der neuesten stabilen VS Code-Version.
Viel Spaß beim Programmieren!
Peng Lyu, Mitglied des VS Code-Teams @njukidreborn