Optimierungen bei der Syntaxhervorhebung
8. Februar 2017 - Alexandru Dima
Die Visual Studio Code-Version 1.9 enthält eine interessante Leistungsverbesserung, an der wir gearbeitet haben, und ich möchte Ihnen die Geschichte dazu erzählen.
TL;DR TextMate-Themes werden in VS Code 1.9 besser so aussehen, wie ihre Autoren es beabsichtigt haben, und gleichzeitig schneller und mit geringerem Speicherverbrauch gerendert.
Syntaxhervorhebung
Die Syntaxhervorhebung besteht normalerweise aus zwei Phasen. Quellcode wird mit Tokens versehen und dann von einem Theme ausgewählt, dem Farben zugewiesen werden, und voilà, Ihr Quellcode wird mit Farben gerendert. Es ist die einzige Funktion, die einen Texteditor in einen Code-Editor verwandelt.
Die Tokenisierung in VS Code (und im Monaco Editor) läuft zeilenweise, von oben nach unten, in einem einzigen Durchgang. Ein Tokenizer kann am Ende einer tokenisierten Zeile einen Zustand speichern, der beim Tokenisieren der nächsten Zeile zurückgegeben wird. Dies ist eine Technik, die von vielen Tokenisierungs-Engines, einschließlich TextMate-Grammatiken, verwendet wird und es einem Editor ermöglicht, nur einen kleinen Teil der Zeilen neu zu tokenisieren, wenn der Benutzer Bearbeitungen vornimmt.
Meistens führt das Tippen in einer Zeile dazu, dass nur diese Zeile neu tokenisiert wird, da der Tokenizer denselben Endzustand zurückgibt und der Editor davon ausgehen kann, dass die folgenden Zeilen keine neuen Tokens erhalten.
Seltener führt das Tippen in einer Zeile zu einer Neu-Tokenisierung/Neuzeigung der aktuellen Zeile und einiger darunterliegenden Zeilen (bis ein gleicher Endzustand erreicht wird).
Wie wir Tokens bisher dargestellt haben
Der Code für den Editor in VS Code wurde lange vor der Existenz von VS Code geschrieben. Er wurde in Form des Monaco Editors in verschiedenen Microsoft-Projekten ausgeliefert, einschließlich der F12-Tools von Internet Explorer. Eine unserer Anforderungen war es, den Speicherverbrauch zu reduzieren.
Früher haben wir Tokenizer von Hand geschrieben (es gibt auch heute noch keine praktikable Möglichkeit, TextMate-Grammatiken im Browser zu interpretieren, aber das ist eine andere Geschichte). Für die folgende Zeile würden wir die folgenden Tokens von unseren handgeschriebenen Tokenizern erhalten

tokens = [
{ startIndex: 0, type: 'keyword.js' },
{ startIndex: 8, type: '' },
{ startIndex: 9, type: 'identifier.js' },
{ startIndex: 11, type: 'delimiter.paren.js' },
{ startIndex: 12, type: 'delimiter.paren.js' },
{ startIndex: 13, type: '' },
{ startIndex: 14, type: 'delimiter.curly.js' }
];
Das Beibehalten dieses Tokens-Arrays verbraucht in Chrome 648 Bytes, daher ist das Speichern eines solchen Objekts in Bezug auf den Speicheraufwand ziemlich teuer (jede Objektinstanz muss Speicherplatz für die Verweise auf ihren Prototyp, ihre Eigenschaftenliste usw. reservieren). Unsere aktuellen Maschinen verfügen über viel RAM, aber das Speichern von 648 Bytes für eine 15 Zeichen lange Zeile ist inakzeptabel.
Also haben wir uns damals ein Binärformat zum Speichern der Tokens ausgedacht, ein Format, das bis einschließlich VS Code 1.8 verwendet wurde. Da es doppelte Token-Typen geben würde, sammelten wir sie in einer separaten Map (pro Datei) und machten etwas wie das Folgende
// 0 1 2 3 4
map = ['', 'keyword.js', 'identifier.js', 'delimiter.paren.js', 'delimiter.curly.js'];
tokens = [
{ startIndex: 0, type: 1 },
{ startIndex: 8, type: 0 },
{ startIndex: 9, type: 2 },
{ startIndex: 11, type: 3 },
{ startIndex: 12, type: 3 },
{ startIndex: 13, type: 0 },
{ startIndex: 14, type: 4 }
];
Dann würden wir den startIndex (32 Bit) und den type (16 Bit) in 48 Bits von den 53 Mantissen-Bits eines JavaScript-Numbers kodieren. Unser Tokens-Array würde dann so aussehen, und die Map-Array würde für die gesamte Datei wiederverwendet werden.
tokens = [
// type startIndex
4294967296, // 0000000000000001 00000000000000000000000000000000
8, // 0000000000000000 00000000000000000000000000001000
8589934601, // 0000000000000010 00000000000000000000000000001001
12884901899, // 0000000000000011 00000000000000000000000000001011
12884901900, // 0000000000000011 00000000000000000000000000001100
13, // 0000000000000000 00000000000000000000000000001101
17179869198 // 0000000000000100 00000000000000000000000000001110
];
Dieses Tokens-Array verbraucht in Chrome 104 Bytes. Die Elemente selbst sollten nur 56 Bytes verbrauchen (7 x 64-Bit-Nummern), und der Rest wird wahrscheinlich durch V8 erklärt, das andere Metadaten mit dem Array speichert oder wahrscheinlich den Backing Store in Zweierpotenzen zuweist. Die Speicherersparnis ist jedoch offensichtlich und wird mit mehr Tokens pro Zeile noch besser. Wir waren mit diesem Ansatz zufrieden und haben diese Darstellung seitdem verwendet.
Hinweis: Es mag kompaktere Möglichkeiten geben, Tokens zu speichern, aber sie in einem binär suchbaren linearen Format zu haben, bietet uns den besten Kompromiss in Bezug auf Speicherverbrauch und Zugriffleistung.
Tokens <-> Theme-Abgleich
Wir dachten, es wäre eine gute Idee, bewährte Praktiken des Browsers zu befolgen, wie z. B. das Auslagern des Stylings an CSS. Beim Rendern der obigen Zeile würden wir die binären Tokens mit der map dekodieren und sie dann mit den Token-Typen wie folgt rendern.
<span class="token keyword js">function</span>
<span class="token"> </span>
<span class="token identifier js">f1</span>
<span class="token delimiter paren js">(</span>
<span class="token delimiter paren js">)</span>
<span class="token"> </span>
<span class="token delimiter curly js">{</span>
Und wir würden unsere Themes in CSS schreiben (zum Beispiel das Visual Studio-Theme).
...
.monaco-editor.vs .token.delimiter { color: #000000; }
.monaco-editor.vs .token.keyword { color: #0000FF; }
.monaco-editor.vs .token.keyword.flow { color: #AF00DB; }
...
Das Ergebnis war ganz gut, wir konnten irgendwo einen Klassennamen umdrehen und sofort ein neues Theme im Editor anwenden lassen.
TextMate-Grammatiken
Zum Zeitpunkt der Veröffentlichung von VS Code hatten wir etwa 10 handgeschriebene Tokenizer, hauptsächlich für Web-Sprachen, was für einen Allzweck-Desktop-Code-Editor definitiv nicht ausreichen würde. Hier kommen TextMate-Grammatiken ins Spiel, eine beschreibende Form der Spezifikation von Tokenisierungsregeln, die in zahlreichen Editoren übernommen wurde. Es gab jedoch ein Problem: TextMate-Grammatiken funktionierten nicht ganz so wie unsere handgeschriebenen Tokenizer.
TextMate-Grammatiken können durch die Verwendung von Begin/End-Zuständen oder While-Zuständen Scopes pushen, die mehrere Tokens umfassen können. Hier ist dasselbe Beispiel unter einer JavaScript-TextMate-Grammatik (der Kürze halber ohne Leerzeichen).

TextMate-Grammatiken in VS Code 1.8
Wenn wir einen Schnitt durch den Scope-Stack machen würden, erhält jedes Token im Grunde ein Array von Scope-Namen, und wir würden vom Tokenizer etwas wie das Folgende zurückbekommen.
tokens = [
{ startIndex: 0, scopes: ['source.js', 'meta.function.js', 'storage.type.function.js'] },
{ startIndex: 8, scopes: ['source.js', 'meta.function.js'] },
{
startIndex: 9,
scopes: [
'source.js',
'meta.function.js',
'meta.definition.function.js',
'entity.name.function.js'
]
},
{
startIndex: 11,
scopes: [
'source.js',
'meta.function.js',
'meta.parameters.js',
'punctuation.definition.parameters.js'
]
},
{ startIndex: 13, scopes: ['source.js', 'meta.function.js'] },
{
startIndex: 14,
scopes: [
'source.js',
'meta.function.js',
'meta.block.js',
'punctuation.definition.block.js'
]
}
];
Alle Token-Typen waren Strings und unser Code war nicht darauf vorbereitet, String-Arrays zu verarbeiten, ganz zu schweigen von den Auswirkungen auf die binäre Kodierung von Tokens. Wir haben uns daher entschlossen, das Array von Scopes mit der folgenden Strategie in einen einzelnen String zu "approximieren" *.
- Ignorieren Sie den am wenigsten spezifischen Scope (z. B.
source.js); er fügte selten einen Wert hinzu. - Teilen Sie jeden verbleibenden Scope bei
".". - Entfernen Sie Duplikate.
- Sortieren Sie die verbleibenden Teile mit einer stabilen Sortierfunktion (nicht unbedingt lexikographisch).
- Fügen Sie die Teile mit
"."zusammen.
tokens = [
{ startIndex: 0, type: 'meta.function.js.storage.type' },
{ startIndex: 9, type: 'meta.function.js' },
{ startIndex: 9, type: 'meta.function.js.definition.entity.name' },
{ startIndex: 11, type: 'meta.function.js.definition.parameters.punctuation' },
{ startIndex: 13, type: 'meta.function.js' },
{ startIndex: 14, type: 'meta.function.js.definition.punctuation.block' }
];
*: Was wir taten, war schlichtweg falsch und "approximieren" ist ein sehr nettes Wort dafür. :)
Diese Tokens würden dann "passen" und denselben Code-Pfad wie die manuell geschriebenen Tokenizer durchlaufen (binär kodiert) und dann auch auf dieselbe Weise gerendert werden.
<span class="token meta function js storage type">function</span>
<span class="token meta function js"> </span>
<span class="token meta function js definition entity name">f1</span>
<span class="token meta function js definition parameters punctuation">()</span>
<span class="token meta function js"> </span>
<span class="token meta function js definition punctuation block">{</span>
TextMate-Themes
TextMate-Themes arbeiten mit Scope-Selektoren, die Tokens mit bestimmten Scopes auswählen und ihnen Theming-Informationen wie Farbe, Fettdruck usw. zuweisen.
Bei einem Token mit den folgenden Scopes
// C B A
scopes = ['source.js', 'meta.definition.function.js', 'entity.name.function.js'];
Hier sind einige einfache Selektoren, die übereinstimmen würden, sortiert nach ihrem Rang (absteigend).
| Selektor | C | B | A |
|---|---|---|---|
| source | source.js | meta.definition.function.js | entity.name.function.js |
| source.js | source.js | meta.definition.function.js | entity.name.function.js |
| meta | source.js | meta.definition.function.js | entity.name.function.js |
| meta.definition | source.js | meta.definition.function.js | entity.name.function.js |
| meta.definition.function | source.js | meta.definition.function.js | entity.name.function.js |
| entity | source.js | meta.definition.function.js | entity.name.function.js |
| entity.name | source.js | meta.definition.function.js | entity.name.function.js |
| entity.name.function | source.js | meta.definition.function.js | entity.name.function.js |
| entity.name.function.js | source.js | meta.definition.function.js | entity.name.function.js |
Beobachtung:
entitygewinnt gegenmeta.definition.function, weil es einen spezifischeren Scope (AgegenüberB) abgleicht.
Beobachtung:
entity.namegewinnt gegenentity, weil beide denselben Scope (A) abgleichen, aberentity.nameist spezifischer alsentity.
Elternselektoren
Um die Sache etwas komplizierter zu machen, unterstützen TextMate-Themes auch Elterselektoren. Hier sind einige Beispiele für die Verwendung von einfachen Selektoren und Elterselektoren (wieder absteigend nach Rang sortiert).
| Selektor | C | B | A |
|---|---|---|---|
| meta | source.js | meta.definition.function.js | entity.name.function.js |
| source meta | source.js | meta.definition.function.js | entity.name.function.js |
| source.js meta | source.js | meta.definition.function.js | entity.name.function.js |
| meta.definition | source.js | meta.definition.function.js | entity.name.function.js |
| source meta.definition | source.js | meta.definition.function.js | entity.name.function.js |
| entity | source.js | meta.definition.function.js | entity.name.function.js |
| source entity | source.js | meta.definition.function.js | entity.name.function.js |
| meta.definition entity | source.js | meta.definition.function.js | entity.name.function.js |
| entity.name | source.js | meta.definition.function.js | entity.name.function.js |
| source entity.name | source.js | meta.definition.function.js | entity.name.function.js |
Beobachtung:
source entitygewinnt gegenentity, weil beide denselben Scope (A) abgleichen, abersource entitystimmt auch mit einem Elterscope (C) überein.
Beobachtung:
entity.namegewinnt gegensource entity, weil beide denselben Scope (A) abgleichen, aberentity.nameist spezifischer alsentity.
Hinweis: Es gibt eine dritte Art von Selektoren, die Scopes ausschließen, über die wir hier nicht sprechen werden. Wir haben keine Unterstützung dafür hinzugefügt und festgestellt, dass sie in der Praxis selten verwendet wird.
TextMate-Themes in VS Code 1.8
Hier sind zwei Monokai-Theme-Regeln (hier als JSON zur Kürze; das Original ist in XML).
...
// Function name
{ "scope": "entity.name.function", "fontStyle": "", "foreground":"#A6E22E" }
...
// Class name
{ "scope": "entity.name.class", "fontStyle": "underline", "foreground":"#A6E22E" }
...
In VS Code 1.8 würden wir zur Übereinstimmung mit unseren "approximierten" Scopes die folgenden dynamischen CSS-Regeln generieren.
...
/* Function name */
.entity.name.function { color: #A6E22E; }
...
/* Class name */
.entity.name.class { color: #A6E22E; text-decoration: underline; }
...
Dann würden wir CSS die "approximierten" Scopes mit den "approximierten" Regeln abgleichen lassen. Aber die CSS-Abgleichregeln unterscheiden sich von den TextMate-Selektor-Abgleichregeln, insbesondere wenn es um die Rangfolge geht. Die CSS-Rangfolge basiert auf der Anzahl der übereinstimmenden Klassennamen, während die TextMate-Selektor-Rangfolge klare Regeln bezüglich der Scope-Spezifität hat.
Deshalb sahen TextMate-Themes in VS Code zwar OK aus, aber nie ganz so, wie ihre Autoren es beabsichtigt hatten. Manchmal waren die Unterschiede gering, aber manchmal veränderten diese Unterschiede das Gefühl eines Themes komplett.
Einige Sterne richten sich aus
Im Laufe der Zeit haben wir unsere handgeschriebenen Tokenizer ausgemustert (der letzte, für HTML, erst vor ein paar Monaten). In VS Code heute werden alle Dateien mit TextMate-Grammatiken tokenisiert. Für den Monaco Editor haben wir auf Monarch (eine beschreibende Tokenisierungs-Engine, die im Wesentlichen TextMate-Grammatiken ähnelt, aber etwas ausdrucksstärker ist und im Browser ausgeführt werden kann) für die meisten unterstützten Sprachen umgestellt und einen Wrapper für manuelle Tokenizer hinzugefügt. Alles in allem bedeutet die Unterstützung eines neuen Tokenisierungsformats, dass 3 Token-Provider (TextMate, Monarch und der manuelle Wrapper) und nicht mehr als 10 geändert werden müssten.
Vor ein paar Monaten haben wir den gesamten Code im VS Code-Kern, der Token-Typen liest, überprüft und festgestellt, dass diese Konsumenten nur an Strings, regulären Ausdrücken oder Kommentaren interessiert waren. Zum Beispiel ignoriert die Klammerabgleichlogik Tokens, die den Scope "string", "comment" oder "regex" enthalten.
Kürzlich haben wir die Zusage von unseren internen Partnern (anderen Teams innerhalb von Microsoft, die den Monaco Editor nutzen) erhalten, dass sie keine Unterstützung mehr für IE9 und IE10 im Monaco Editor benötigen.
Wahrscheinlich am wichtigsten ist, dass die am häufigsten gewünschte Funktion für den Editor die Minimap-Unterstützung ist. Um eine Minimap in angemessener Zeit zu rendern, können wir keine DOM-Knoten und CSS-Abgleiche verwenden. Wir werden wahrscheinlich eine Canvas verwenden und müssen die Farbe jedes Tokens in JavaScript kennen, um diese winzigen Buchstaben mit den richtigen Farben malen zu können.
Vielleicht der größte Durchbruch, den wir erzielt haben, ist, dass wir **keine Tokens oder deren Scopes speichern müssen**, da Tokens nur Effekte in Bezug auf ein sie abgleichendes Theme oder einen Klammerabgleich, der Strings überspringt, erzeugen.
Schließlich, was ist neu in VS Code 1.9
Darstellung eines TextMate-Themes
So könnte ein sehr einfaches Theme aussehen.
theme = [
{ "foreground": "#F8F8F2" },
{ "scope": "var", "foreground": "#F8F8F2" },
{ "scope": "var.identifier", "foreground": "#00FF00", "fontStyle": "bold" },
{ "scope": "meta var.identifier", "foreground": "#0000FF" },
{ "scope": "constant", "foreground": "#100000", "fontStyle": "italic" },
{ "scope": "constant.numeric", "foreground": "#200000" },
{ "scope": "constant.numeric.hex", "fontStyle": "bold" },
{ "scope": "constant.numeric.oct", "fontStyle": "underline" },
{ "scope": "constant.numeric.dec", "foreground": "#300000" },
];
Beim Laden generieren wir für jede eindeutige Farbe, die im Theme vorkommt, eine ID und speichern sie in einer Farbzuordnung (ähnlich wie wir es zuvor für Token-Typen getan haben).
// 1 2 3 4 5 6
colorMap = ["reserved", "#F8F8F2", "#00FF00", "#0000FF", "#100000", "#200000", "#300000"]
theme = [
{ "foreground": 1 },
{ "scope": "var", "foreground": 1, },
{ "scope": "var.identifier", "foreground": 2, "fontStyle": "bold" },
{ "scope": "meta var.identifier", "foreground": 3 },
{ "scope": "constant", "foreground": 4, "fontStyle": "italic" },
{ "scope": "constant.numeric", "foreground": 5 },
{ "scope": "constant.numeric.hex", "fontStyle": "bold" },
{ "scope": "constant.numeric.oct", "fontStyle": "underline" },
{ "scope": "constant.numeric.dec", "foreground": 6 },
];
Wir generieren dann eine Trie-Datenstruktur aus den Theme-Regeln, wobei jeder Knoten die aufgelösten Theme-Optionen enthält.
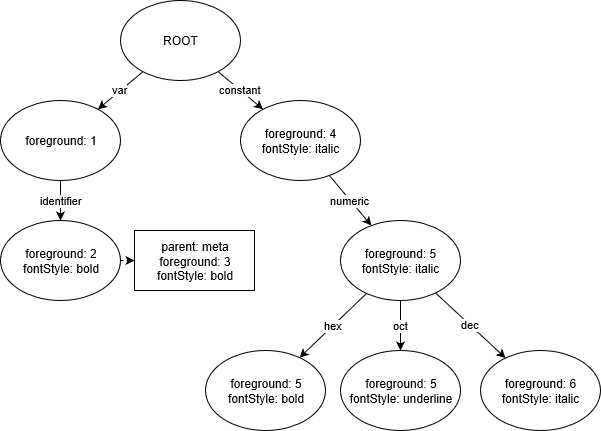
Beobachtung: Die Knoten für
constant.numeric.hexundconstant.numeric.octenthalten die Anweisung, die Vordergrundfarbe auf5zu ändern, da sie diese Anweisung vonconstant.numeric*erben*.
Beobachtung: Der Knoten für
var.identifierenthält die zusätzliche Elterregelmeta var.identifierund wird entsprechend Anfragen beantworten.
Wenn wir herausfinden wollen, wie ein Scope thematisiert werden soll, können wir diese Trie abfragen.
Zum Beispiel
| Abfrage | Ergebnisse |
|---|---|
| constant | Vordergrund auf 4 setzen, fontStyle auf italic |
| constant.numeric | Vordergrund auf 5 setzen, fontStyle auf italic |
| constant.numeric.hex | Vordergrund auf 5 setzen, fontStyle auf bold |
| var | Vordergrund auf 1 setzen |
| var.baz | Vordergrund auf 1 setzen (stimmt mit var überein) |
| baz | nichts tun (keine Übereinstimmung) |
| var.identifier | Wenn ein Elterscope meta vorhanden ist, Vordergrund auf 3 setzen, fontStyle auf bold,andernfalls Vordergrund auf 2 setzen, fontStyle auf bold |
Änderungen an der Tokenisierung
Der gesamte TextMate-Tokenisierungs-Code, der in VS Code verwendet wird, befindet sich in einem separaten Projekt, vscode-textmate, das unabhängig von VS Code verwendet werden kann. Wir haben die Art und Weise geändert, wie wir den Scope-Stack in vscode-textmate darstellen, und zwar als unveränderliche verkettete Liste, die auch die vollständig aufgelösten metadata speichert.
Beim Pushen eines neuen Scopes auf den Scope-Stack suchen wir den neuen Scope in der Theme-Trie. Wir können dann sofort die vollständig aufgelöste gewünschte Vordergrundfarbe oder den Schriftstil für eine Scope-Liste berechnen, basierend auf dem, was wir vom Scope-Stack erben und was die Theme-Trie zurückgibt.
Einige Beispiele
| Scope-Stack | Metadaten |
|---|---|
| ["source.js"] | Vordergrund ist 1, fontStyle ist normal (die Standardregel ohne Scope-Selektor). |
| ["source.js","constant"] | Vordergrund ist 4, fontStyle ist italic |
| ["source.js","constant","baz"] | Vordergrund ist 4, fontStyle ist italic |
| ["source.js","var.identifier"] | Vordergrund ist 2, fontStyle ist bold |
| ["source.js","meta","var.identifier"] | Vordergrund ist 3, fontStyle ist bold |
Beim Poppen aus dem Scope-Stack muss nichts berechnet werden, da wir einfach die Metadaten verwenden können, die mit dem vorherigen Scope-Listen-Element gespeichert sind.
Hier ist die TypeScript-Klasse, die ein Element in der Scope-Liste darstellt.
export class ScopeListElement {
public readonly parent: ScopeListElement;
public readonly scope: string;
public readonly metadata: number;
...
}
Wir speichern 32 Bits an Metadaten.
/**
* - -------------------------------------------
* 3322 2222 2222 1111 1111 1100 0000 0000
* 1098 7654 3210 9876 5432 1098 7654 3210
* - -------------------------------------------
* xxxx xxxx xxxx xxxx xxxx xxxx xxxx xxxx
* bbbb bbbb bfff ffff ffFF FTTT LLLL LLLL
* - -------------------------------------------
* - L = LanguageId (8 bits)
* - T = StandardTokenType (3 bits)
* - F = FontStyle (3 bits)
* - f = foreground color (9 bits)
* - b = background color (9 bits)
*/
Schließlich, anstatt Tokens als Objekte aus der Tokenisierungs-Engine auszugeben.
// These are generated using the Monokai theme.
tokens_before = [
{ startIndex: 0, scopes: ['source.js', 'meta.function.js', 'storage.type.function.js'] },
{ startIndex: 8, scopes: ['source.js', 'meta.function.js'] },
{
startIndex: 9,
scopes: [
'source.js',
'meta.function.js',
'meta.definition.function.js',
'entity.name.function.js'
]
},
{
startIndex: 11,
scopes: [
'source.js',
'meta.function.js',
'meta.parameters.js',
'punctuation.definition.parameters.js'
]
},
{ startIndex: 13, scopes: ['source.js', 'meta.function.js'] },
{
startIndex: 14,
scopes: [
'source.js',
'meta.function.js',
'meta.block.js',
'punctuation.definition.block.js'
]
}
];
// Every even index is the token start index, every odd index is the token metadata.
// We get fewer tokens because tokens with the same metadata get collapsed
tokens_now = [
// bbbbbbbbb fffffffff FFF TTT LLLLLLLL
0,
16926743, // 000000010 000001001 001 000 00010111
8,
16793623, // 000000010 000000001 000 000 00010111
9,
16859159, // 000000010 000000101 000 000 00010111
11,
16793623 // 000000010 000000001 000 000 00010111
];
Und sie werden gerendert mit
<span class="mtk9 mtki">function</span>
<span class="mtk1"> </span>
<span class="mtk5">f1</span>
<span class="mtk1">() {</span>
Die Tokens werden als Uint32Array direkt vom Tokenizer zurückgegeben. Wir halten den zugrunde liegenden ArrayBuffer und für das obige Beispiel verbraucht dieser in Chrome 96 Bytes. Die Elemente selbst sollten nur 32 Bytes verbrauchen (8 x 32-Bit-Nummern), aber auch hier beobachten wir wahrscheinlich einen V8-Metadaten-Overhead.
Einige Zahlen
Um die folgenden Messungen zu erhalten, habe ich drei Dateien mit unterschiedlichen Merkmalen und Grammatiken ausgewählt.
| Dateiname | Dateigröße | Zeilen | Sprache | Beobachtung |
|---|---|---|---|---|
| checker.ts | 1,18 MB | 22,253 | TypeScript | Tatsächliche Quelldatei, die im TypeScript-Compiler verwendet wird. |
| bootstrap.min.css | 118,36 KB | 12 | CSS | Minifizierte CSS-Datei. |
| sqlite3.c | 6,73 MB | 200,904 | C | Verteilungsdatei von SQLite, verkettet. |
Ich habe die Tests auf einem recht leistungsstarken Desktop-Computer unter Windows (der Electron 32-Bit verwendet) durchgeführt.
Ich musste einige Änderungen am Quellcode vornehmen, um Äpfel mit Äpfeln vergleichen zu können, z. B. sicherstellen, dass in beiden VS Code-Versionen exakt dieselben Grammatiken verwendet werden, reiche Sprachfunktionen in beiden Versionen deaktivieren oder die 100-fache Stack-Tiefenbeschränkung in VS Code 1.8 aufheben, die in VS Code 1.9 nicht mehr existiert usw. Ich musste auch bootstrap.min.css in mehrere Zeilen aufteilen, um jede Zeile unter 20.000 Zeichen zu halten.
Tokenisierungszeiten
Die Tokenisierung läuft im UI-Thread schrittweise. Daher musste ich Code hinzufügen, um sie synchron ausführen zu lassen, um die folgenden Zeiten zu messen (Median von 10 Läufen dargestellt).
| Dateiname | Dateigröße | VS Code 1.8 | VS Code 1.9 | Beschleunigung |
|---|---|---|---|---|
| checker.ts | 1,18 MB | 4606,80 ms | 3939,00 ms | 14.50% |
| bootstrap.min.css | 118,36 KB | 776,76 ms | 416,28 ms | 46.41% |
| sqlite3.c | 6,73 MB | 16010,42 ms | 10964,42 ms | 31.52% |
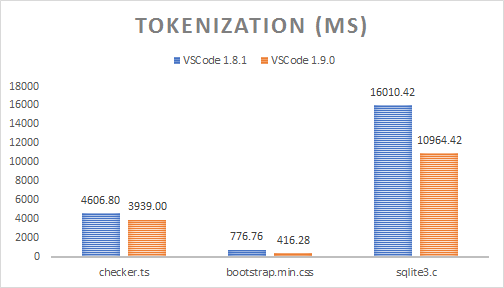
Obwohl die Tokenisierung jetzt auch den Theme-Abgleich durchführt, können die Zeitersparnisse dadurch erklärt werden, dass jede Zeile nur einmal durchlaufen wird. Während es früher einen Tokenisierungsdurchlauf, einen zweiten Durchlauf zur "Approximation" der Scopes zu einem String und einen dritten Durchlauf zur binären Kodierung der Tokens gab, werden die Tokens jetzt direkt binär kodiert aus der TextMate-Tokenisierungs-Engine generiert. Die Menge der zu sammelnden Garbage wurde ebenfalls erheblich reduziert.
Speicherverbrauch
Das Falten verbraucht viel Speicher, besonders bei großen Dateien (das ist eine Optimierung für eine andere Zeit). Daher habe ich die folgenden Heap-Snapshot-Zahlen mit deaktiviertem Falten gesammelt. Dies zeigt den vom Model belegten Speicher, ohne den ursprünglichen Dateistring zu berücksichtigen.
| Dateiname | Dateigröße | VS Code 1.8 | VS Code 1.9 | Speicherersparnis |
|---|---|---|---|---|
| checker.ts | 1,18 MB | 3,37 MB | 2,61 MB | 22.60% |
| bootstrap.min.css | 118,36 KB | 267,00 KB | 201,33 KB | 24.60% |
| sqlite3.c | 6,73 MB | 27,49 MB | 21,22 MB | 22.83% |
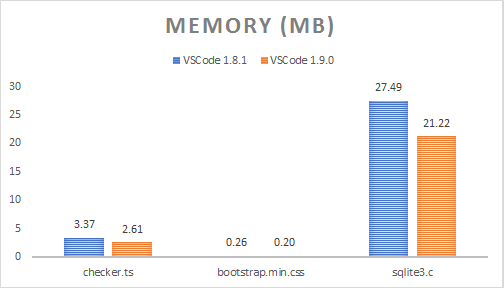
Der reduzierte Speicherverbrauch lässt sich durch das Nicht-Speichern einer Tokens-Map, das Zusammenfassen aufeinanderfolgender Tokens mit denselben Metadaten und die Verwendung von
ArrayBufferals Backing Store erklären. Wir könnten hier weiter verbessern, indem wir Leerzeichen-Tokens immer mit dem vorherigen Token zusammenfassen, da es keine Rolle spielt, welche Farbe Leerzeichen erhalten (Leerzeichen sind unsichtbar).
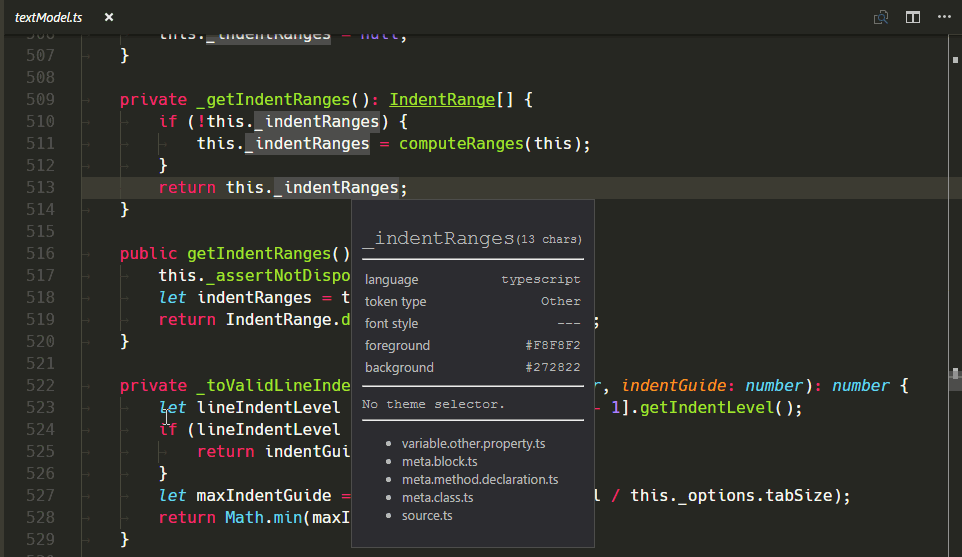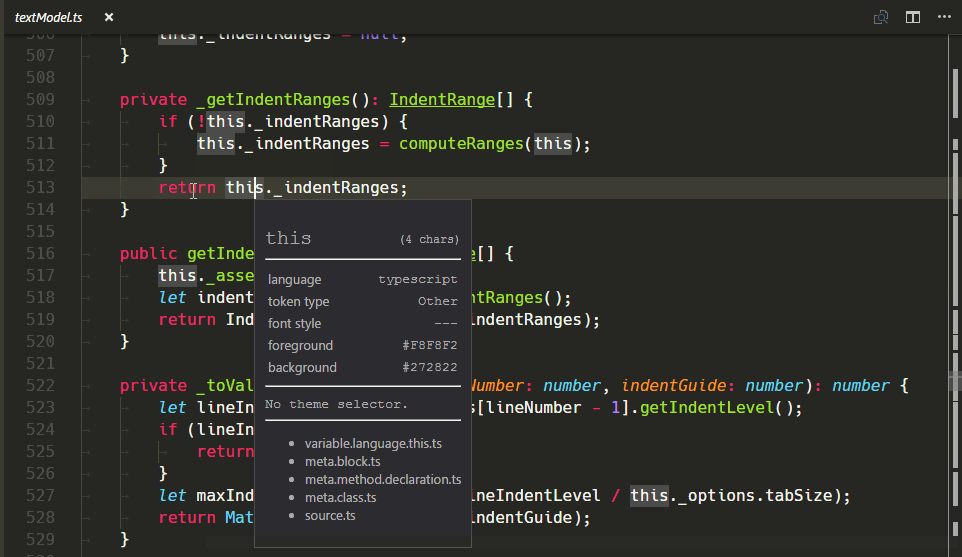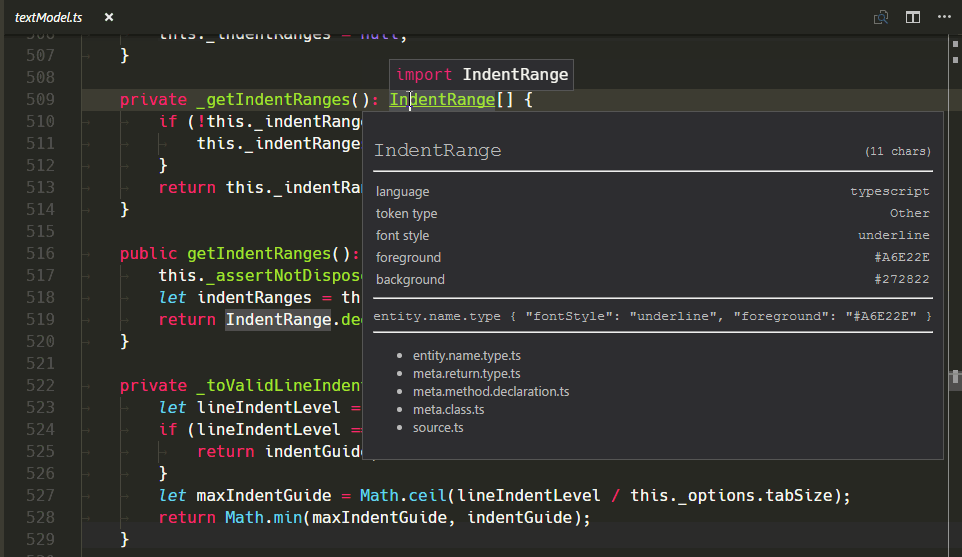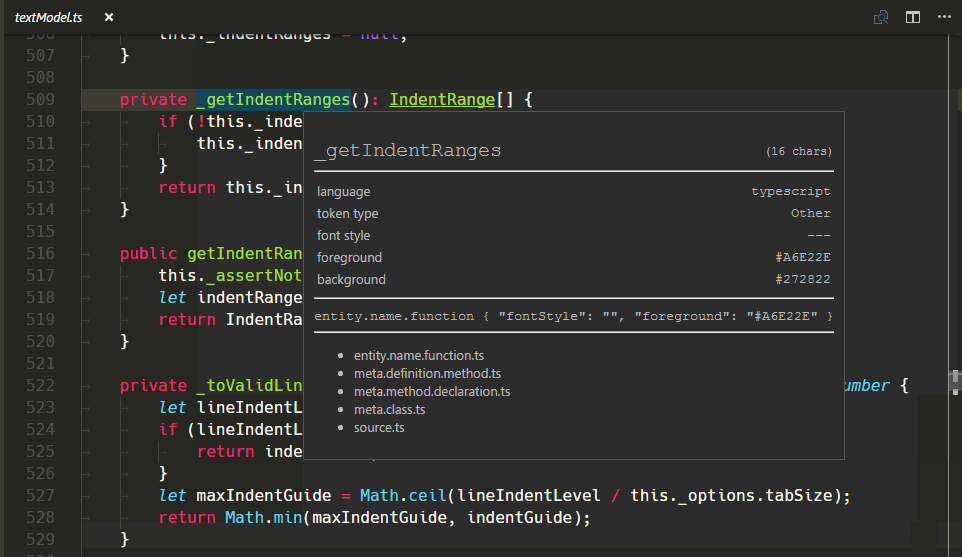
Neues TextMate-Scope-Inspector-Widget
Wir haben ein neues Widget hinzugefügt, das bei der Erstellung und Fehlersuche von Themes oder Grammatiken hilft: Sie können es mit Developer: Inspect Editor Tokens and Scopes in der Command Palette (⇧⌘P (Windows, Linux Ctrl+Shift+P)) ausführen.
Validierung der Änderung
Änderungen an dieser Komponente des Editors stellten ein erhebliches Risiko dar, da jeder Fehler in unserem Ansatz (im neuen Trie-Erstellungscode, im neuen Binärformat usw.) potenziell zu großen, für den Benutzer sichtbaren Unterschieden führen könnte.
In VS Code haben wir eine Integrationssuite, die die Farben für alle Programmiersprachen, die wir über die fünf von uns erstellten Themes (Light, Light+, Dark, Dark+, High Contrast) ausliefern, überprüft. Diese Tests sind sowohl bei Änderungen an einem unserer Themes als auch bei der Aktualisierung einer bestimmten Grammatik sehr hilfreich. Jeder der 73 Integrationstests besteht aus einer Fixture-Datei (z. B. test.c) und den erwarteten Farben für die fünf Themes (test_c.json) und wird bei jedem Commit in unserem CI-Build ausgeführt.
Um die Tokenisierungsänderung zu validieren, haben wir die Colorisierungsresultate dieser Tests für alle 14 mitgelieferten Themes (nicht nur die fünf von uns erstellten) mit dem alten CSS-basierten Ansatz gesammelt. Danach, nach jeder Änderung, haben wir dieselben Tests mit der neuen Trie-basierten Logik ausgeführt und mithilfe eines benutzerdefinierten visuellen Diff- und Patch-Tools jeden einzelnen Farbunterschied untersucht und die Ursache der Farbänderung ermittelt. Mit dieser Technik haben wir mindestens 2 Fehler gefunden und konnten unsere fünf Themes so ändern, dass die Farbänderungen zwischen den VS Code-Versionen minimal waren.
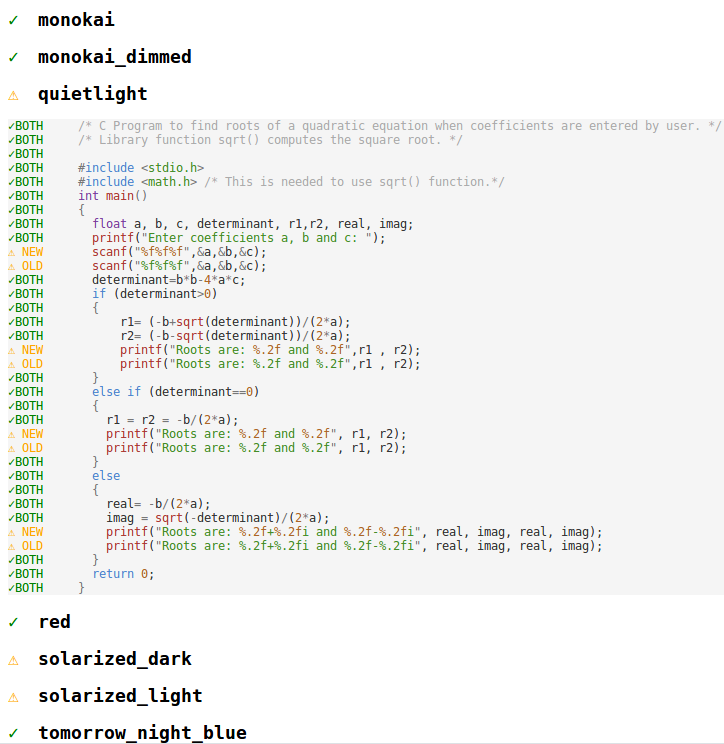
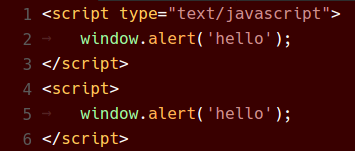
Vorher und Nachher
Unten sind verschiedene Farbthemen zu sehen, wie sie in VS Code 1.8 und jetzt in VS Code 1.9 erschienen sind.
Monokai-Theme
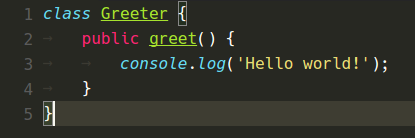
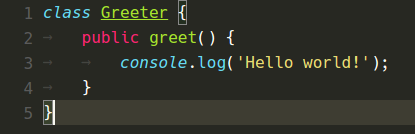
Quiet Light Theme


Red Theme
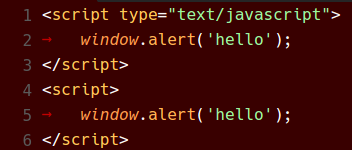
Fazit
Ich hoffe, Sie werden die zusätzliche CPU-Zeit und den RAM, die Sie durch das Upgrade auf VS Code 1.9 erhalten, zu schätzen wissen und dass wir Ihnen weiterhin ermöglichen können, auf effiziente und angenehme Weise zu codieren.
Viel Spaß beim Codieren!
Alexandru Dima, Mitglied des VS Code-Teams @alexdima123