Syntaxhervorhebungsleitfaden
Die Syntaxhervorhebung bestimmt die Farbe und den Stil des Quellcodes, der im Visual Studio Code-Editor angezeigt wird. Sie ist dafür verantwortlich, Schlüsselwörter wie if oder for in JavaScript anders zu färben als Zeichenfolgen, Kommentare und Variablennamen.
Es gibt zwei Komponenten der Syntaxhervorhebung
- Tokenisierung: Aufteilen von Text in eine Liste von Tokens
- Theming: Verwenden von Themes oder Benutzereinstellungen, um die Tokens bestimmten Farben und Stilen zuzuordnen
Bevor Sie sich mit den Details befassen, ist es ein guter Anfang, mit dem Scope Inspector-Tool zu experimentieren und zu untersuchen, welche Tokens in einer Quelldatei vorhanden sind und welche Theme-Regeln sie abgleichen. Um sowohl semantische als auch Syntax-Tokens anzuzeigen, verwenden Sie ein integriertes Theme (z. B. Dark+) für eine TypeScript-Datei.
Tokenisierung
Bei der Tokenisierung von Text geht es darum, den Text in Segmente zu zerlegen und jedes Segment mit einem Token-Typ zu klassifizieren.
Die Tokenisierungs-Engine von VS Code wird von TextMate-Grammatiken angetrieben. TextMate-Grammatiken sind eine strukturierte Sammlung von regulären Ausdrücken und werden als Plist- (XML) oder JSON-Dateien geschrieben. VS Code-Erweiterungen können Grammatiken über den grammars-Beitragspunkt beitragen.
Die TextMate-Tokenisierungs-Engine läuft im selben Prozess wie die Renderer-Engine, und Tokens werden aktualisiert, während der Benutzer tippt. Tokens werden für die Syntaxhervorhebung verwendet, aber auch, um den Quellcode in Bereiche wie Kommentare, Zeichenfolgen und Regex zu klassifizieren.
Seit Version 1.43 ermöglicht VS Code Erweiterungen auch, die Tokenisierung über einen semantischen Token-Provider bereitzustellen. Semantische Provider werden typischerweise von Sprachservern implementiert, die ein tieferes Verständnis der Quelldatei haben und Symbole im Kontext des Projekts auflösen können. Beispielsweise kann ein konstanter Variablenname mit einer konstanten Hervorhebung im gesamten Projekt gerendert werden, nicht nur an der Stelle seiner Deklaration.
Die Hervorhebung auf Basis semantischer Tokens wird als Ergänzung zur TextMate-basierten Syntaxhervorhebung betrachtet. Semantische Hervorhebung baut auf der Syntaxhervorhebung auf. Da das Laden und Analysieren eines Projekts durch Sprachserver einige Zeit dauern kann, kann die Hervorhebung semantischer Tokens nach einer kurzen Verzögerung erscheinen.
Dieser Artikel konzentriert sich auf die TextMate-basierte Tokenisierung. Semantische Tokenisierung und Theming werden im Leitfaden zur semantischen Hervorhebung erläutert.
TextMate-Grammatiken
VS Code verwendet TextMate-Grammatiken als Syntax-Tokenisierungs-Engine. Sie wurden für den TextMate-Editor erfunden und aufgrund der großen Anzahl von Sprachpaketen, die von der Open-Source-Community erstellt und gepflegt werden, von vielen anderen Editoren und IDEs übernommen.
TextMate-Grammatiken basieren auf Oniguruma-RegulärExpressionsausdrücken und werden typischerweise als Plist oder JSON geschrieben. Eine gute Einführung in TextMate-Grammatiken finden Sie hier, und Sie können sich bestehende TextMate-Grammatiken ansehen, um mehr darüber zu erfahren, wie sie funktionieren.
TextMate-Tokens und -Scopes
Tokens sind ein oder mehrere Zeichen, die zu demselben Programmelement gehören. Beispiel-Tokens sind Operatoren wie + und *, Variablennamen wie myVar oder Zeichenfolgen wie "my string".
Jedes Token ist mit einem Scope verbunden, der den Kontext des Tokens definiert. Ein Scope ist eine punktgetrennte Liste von Bezeichnern, die den Kontext des aktuellen Tokens angeben. Die +-Operation in JavaScript hat beispielsweise den Scope keyword.operator.arithmetic.js.
Themes ordnen Scopes Farben und Stilen zu, um die Syntaxhervorhebung bereitzustellen. TextMate bietet eine Liste gängiger Scopes, die von vielen Themes angesprochen werden. Um Ihre Grammatik so breit wie möglich unterstützen zu lassen, versuchen Sie, auf bestehenden Scopes aufzubauen, anstatt neue zu definieren.
Scopes sind verschachtelt, so dass jedes Token auch mit einer Liste von übergeordneten Scopes verbunden ist. Das folgende Beispiel verwendet den Scope Inspector, um die Scope-Hierarchie für den +-Operator in einer einfachen JavaScript-Funktion anzuzeigen. Der spezifischste Scope wird oben aufgeführt, mit allgemeineren übergeordneten Scopes darunter
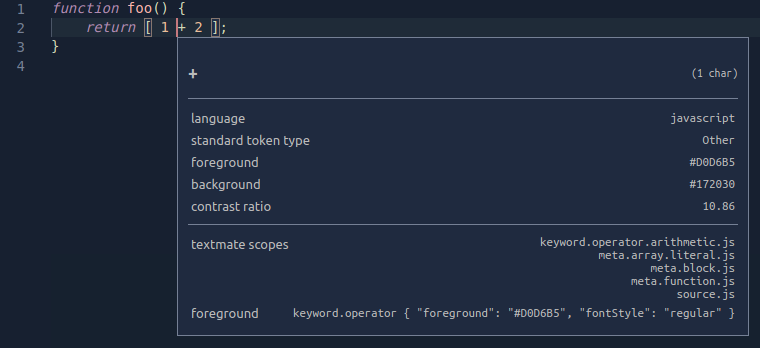
Übergeordnete Scope-Informationen werden auch für das Theming verwendet. Wenn ein Theme einen Scope anspricht, werden alle Tokens mit diesem übergeordneten Scope eingefärbt, es sei denn, das Theme bietet auch eine spezifischere Einfärbung für ihre individuellen Scopes.
Beitragen einer grundlegenden Grammatik
VS Code unterstützt JSON-TextMate-Grammatiken. Diese werden über den grammars-Beitragspunkt beigesteuert.
Jeder Grammatikbeitrag gibt an: die Kennung der Sprache, für die die Grammatik gilt, den Scope-Namen der obersten Ebene für die Tokens der Grammatik und den relativen Pfad zu einer Grammatikdatei. Das folgende Beispiel zeigt einen Grammatikbeitrag für eine fiktive Sprache abc
{
"contributes": {
"languages": [
{
"id": "abc",
"extensions": [".abc"]
}
],
"grammars": [
{
"language": "abc",
"scopeName": "source.abc",
"path": "./syntaxes/abc.tmGrammar.json"
}
]
}
}
Die Grammatikdatei selbst besteht aus einer Regel der obersten Ebene. Diese ist typischerweise in einen patterns-Abschnitt unterteilt, der die Elemente der obersten Ebene des Programms auflistet, und ein repository, das jedes der Elemente definiert. Andere Regeln in der Grammatik können Elemente aus dem repository über { "include": "#id" } referenzieren.
Das Beispiel abc-Grammatik markiert die Buchstaben a, b und c als Schlüsselwörter und Klammerverschachtelungen als Ausdrücke.
{
"scopeName": "source.abc",
"patterns": [{ "include": "#expression" }],
"repository": {
"expression": {
"patterns": [{ "include": "#letter" }, { "include": "#paren-expression" }]
},
"letter": {
"match": "a|b|c",
"name": "keyword.letter"
},
"paren-expression": {
"begin": "\\(",
"end": "\\)",
"beginCaptures": {
"0": { "name": "punctuation.paren.open" }
},
"endCaptures": {
"0": { "name": "punctuation.paren.close" }
},
"name": "expression.group",
"patterns": [{ "include": "#expression" }]
}
}
}
Die Grammatik-Engine versucht, die expression-Regel nacheinander auf den gesamten Text im Dokument anzuwenden. Für ein einfaches Programm wie
a
(
b
)
x
(
(
c
xyz
)
)
(
a
Die Beispielgrammatik erzeugt die folgenden Scopes (links nach rechts von spezifischstem zu am wenigsten spezifischem Scope aufgelistet)
a keyword.letter, source.abc
( punctuation.paren.open, expression.group, source.abc
b keyword.letter, expression.group, source.abc
) punctuation.paren.close, expression.group, source.abc
x source.abc
( punctuation.paren.open, expression.group, source.abc
( punctuation.paren.open, expression.group, expression.group, source.abc
c keyword.letter, expression.group, expression.group, source.abc
xyz expression.group, expression.group, source.abc
) punctuation.paren.close, expression.group, expression.group, source.abc
) punctuation.paren.close, expression.group, source.abc
( punctuation.paren.open, expression.group, source.abc
a keyword.letter, expression.group, source.abc
Beachten Sie, dass Text, der nicht von einer der Regeln übereinstimmt, wie z. B. die Zeichenfolge xyz, in den aktuellen Scope aufgenommen wird. Die letzte Klammer am Ende der Datei ist Teil des expression.group, auch wenn die end-Regel nicht übereinstimmt, da das end-of-document vor der end-Regel gefunden wurde.
Eingebettete Sprachen
Wenn Ihre Grammatik eingebettete Sprachen innerhalb der übergeordneten Sprache enthält, wie z. B. CSS-Stilblöcke in HTML, können Sie den Beitragspunkt embeddedLanguages verwenden, um VS Code mitzuteilen, dass die eingebettete Sprache als eigenständig von der übergeordneten Sprache behandelt werden soll. Dies stellt sicher, dass Klammerung, Kommentierung und andere grundlegende Sprachfunktionen in der eingebetteten Sprache wie erwartet funktionieren.
Der Beitragspunkt embeddedLanguages ordnet einem Scope in der eingebetteten Sprache einen Sprach-Scope der obersten Ebene zu. Im folgenden Beispiel werden alle Tokens im Scope meta.embedded.block.javascript als JavaScript-Inhalt behandelt
{
"contributes": {
"grammars": [
{
"path": "./syntaxes/abc.tmLanguage.json",
"scopeName": "source.abc",
"embeddedLanguages": {
"meta.embedded.block.javascript": "javascript"
}
}
]
}
}
Wenn Sie nun versuchen, Code zu kommentieren oder Snippets innerhalb einer Menge von Tokens auszulösen, die als meta.embedded.block.javascript markiert sind, erhalten sie den richtigen JavaScript-Stilkommentar // und die richtigen JavaScript-Snippets.
Entwickeln einer neuen Grammatik-Erweiterung
Um schnell eine neue Grammatik-Erweiterung zu erstellen, verwenden Sie die VS Code Yeoman-Vorlagen, führen Sie yo code aus und wählen Sie die Option New Language
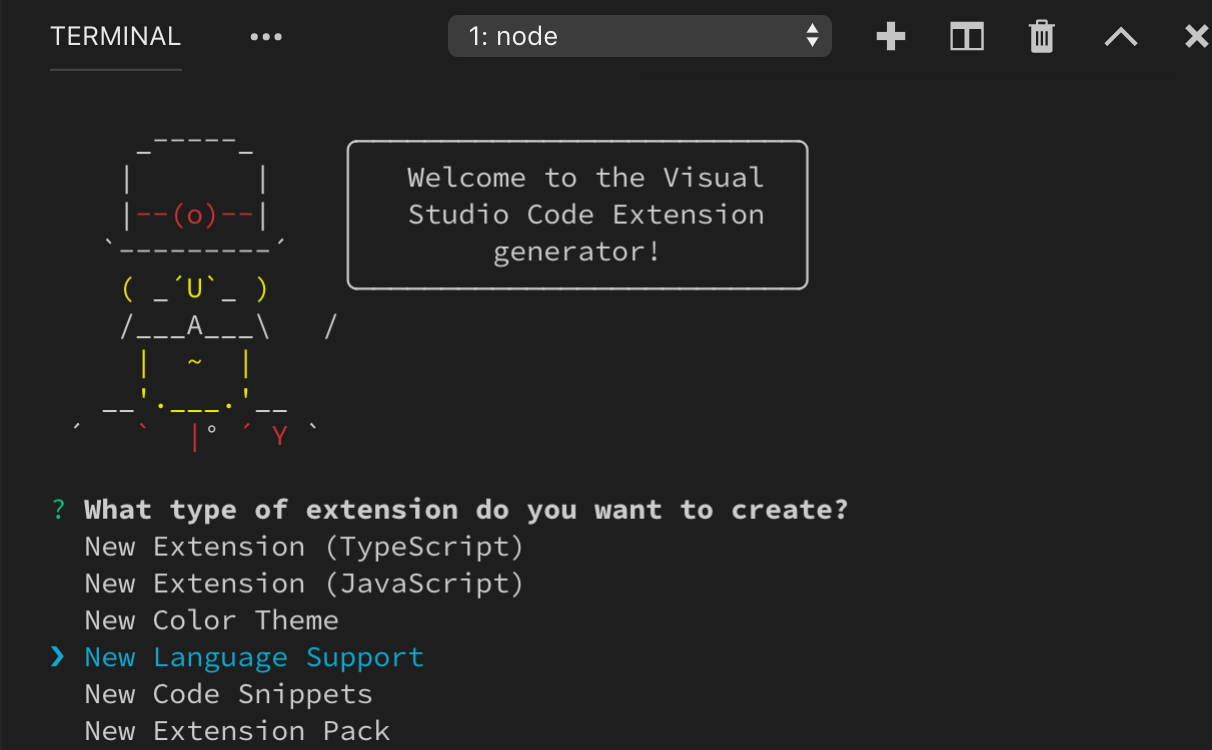
Yeoman führt Sie durch einige grundlegende Fragen, um die neue Erweiterung zu erstellen. Die wichtigen Fragen zur Erstellung einer neuen Grammatik sind
Language id- Eine eindeutige Kennung für Ihre Sprache.Language name- Ein für Menschen lesbarer Name für Ihre Sprache.Scope names- Der TextMate-Scope-Name der obersten Ebene für Ihre Grammatik.
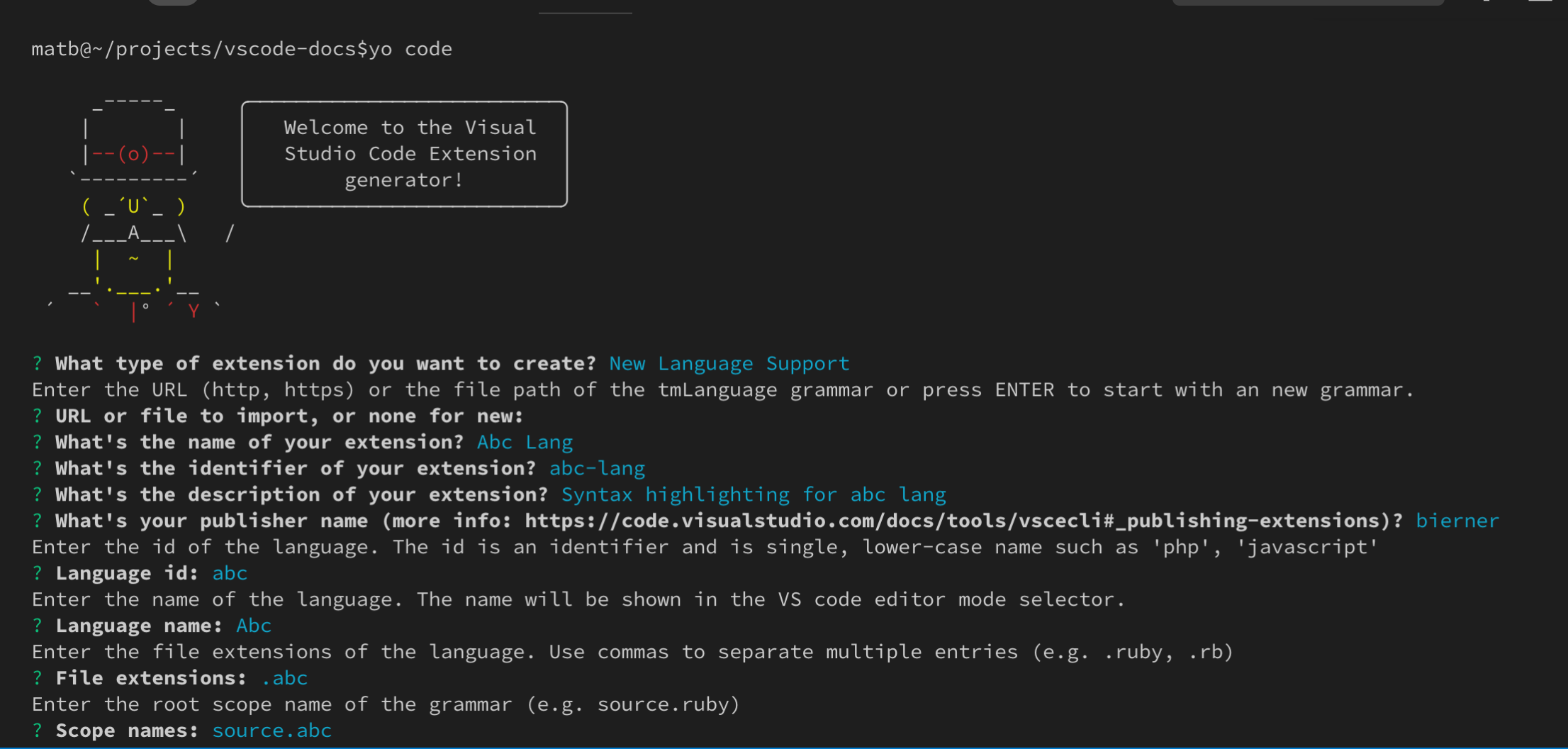
Der Generator geht davon aus, dass Sie sowohl eine neue Sprache als auch eine neue Grammatik für diese Sprache definieren möchten. Wenn Sie eine Grammatik für eine bereits vorhandene Sprache erstellen, füllen Sie diese einfach mit den Informationen Ihrer Zielsprache aus und stellen Sie sicher, dass Sie den languages-Beitragspunkt in der generierten package.json löschen.
Nachdem Sie alle Fragen beantwortet haben, erstellt Yeoman eine neue Erweiterung mit der folgenden Struktur
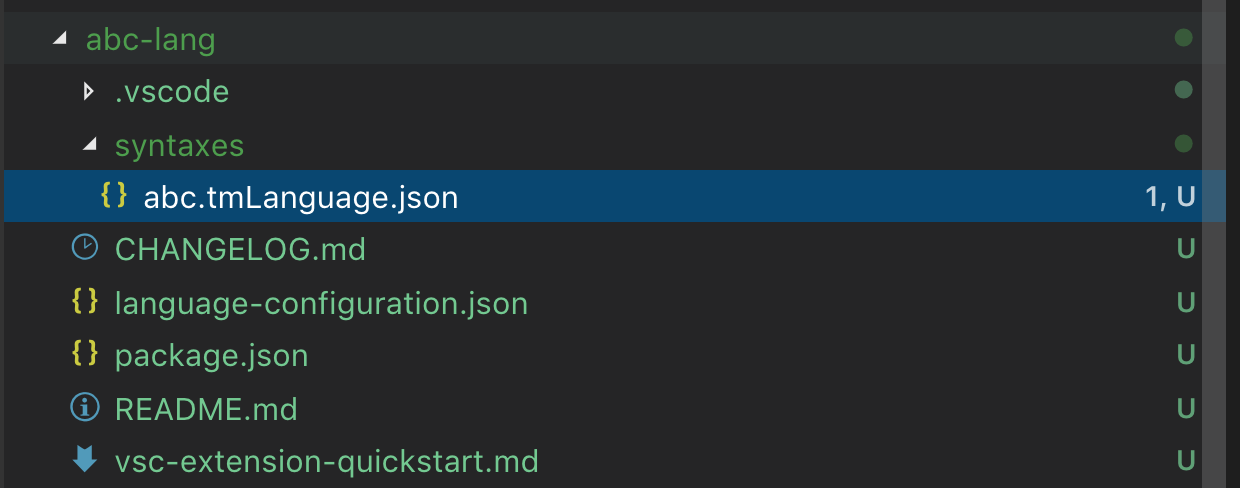
Denken Sie daran: Wenn Sie eine Grammatik für eine Sprache beisteuern, die VS Code bereits kennt, stellen Sie sicher, dass Sie den languages-Beitragspunkt in der generierten package.json löschen.
Konvertieren einer bestehenden TextMate-Grammatik
yo code kann auch helfen, eine bestehende TextMate-Grammatik in eine VS Code-Erweiterung zu konvertieren. Beginnen Sie erneut, indem Sie yo code ausführen und Language extension auswählen. Wenn Sie nach einer bestehenden Grammatikdatei gefragt werden, geben Sie den vollständigen Pfad zu einer .tmLanguage- oder .json-TextMate-Grammatikdatei an
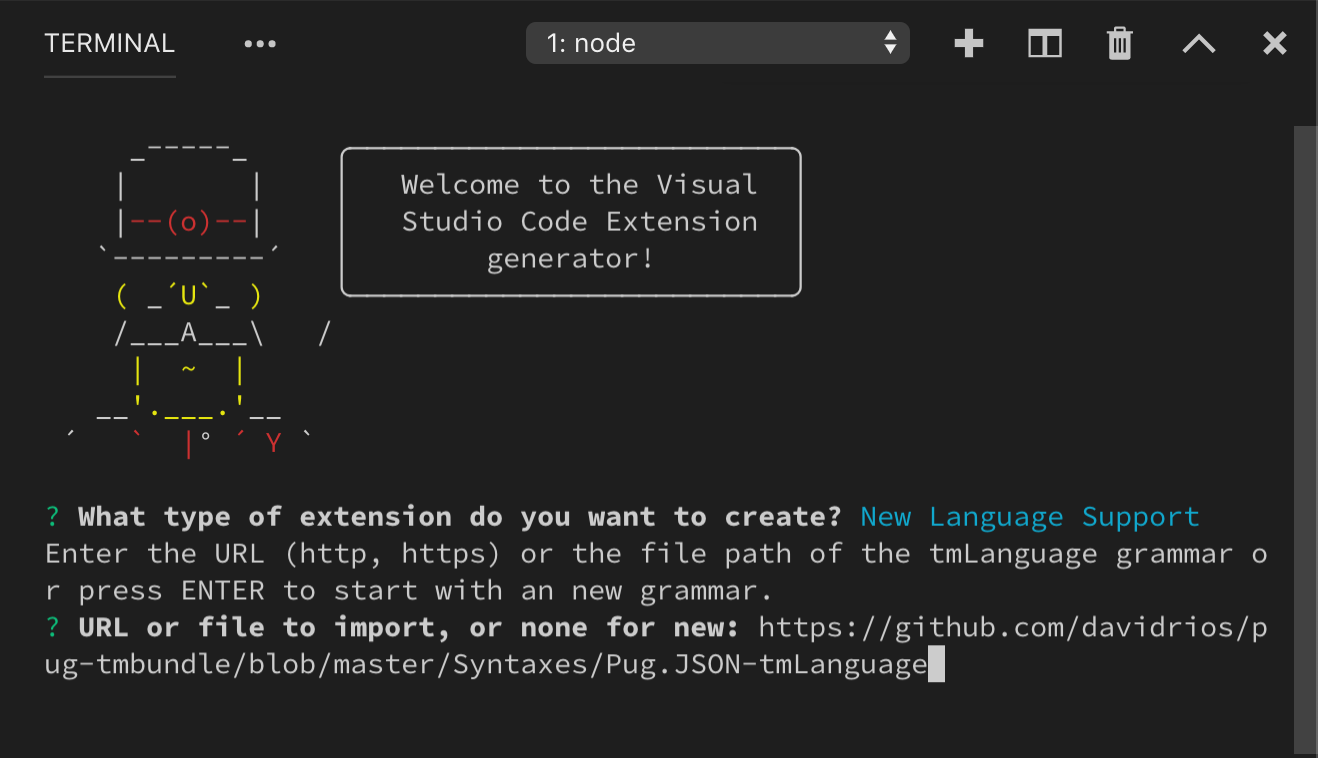
Verwenden von YAML zum Schreiben einer Grammatik
Wenn eine Grammatik komplexer wird, kann es schwierig werden, sie als JSON zu verstehen und zu pflegen. Wenn Sie feststellen, dass Sie komplexe reguläre Ausdrücke schreiben oder Kommentare hinzufügen müssen, um Aspekte der Grammatik zu erklären, sollten Sie stattdessen YAML verwenden, um Ihre Grammatik zu definieren.
YAML-Grammatiken haben die exakt gleiche Struktur wie JSON-basierte Grammatiken, erlauben Ihnen aber die Verwendung der prägnanteren Syntax von YAML, zusammen mit Funktionen wie mehrzeiligen Zeichenfolgen und Kommentaren.
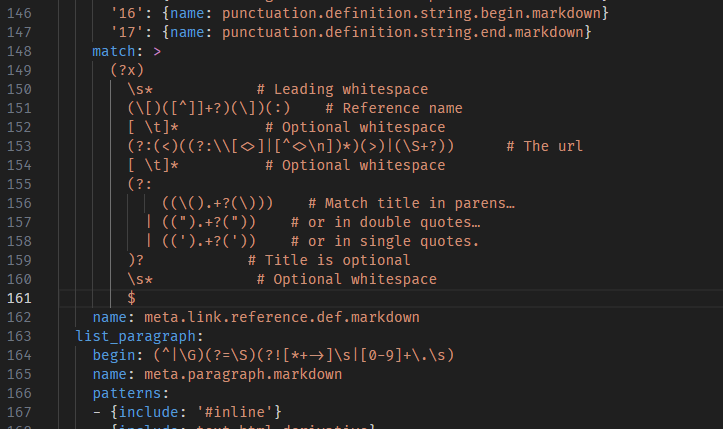
VS Code kann nur JSON-Grammatiken laden, daher müssen YAML-basierte Grammatiken in JSON konvertiert werden. Das js-yaml-Paket und das Befehlszeilentool machen dies einfach.
# Install js-yaml as a development only dependency in your extension
$ npm install js-yaml --save-dev
# Use the command-line tool to convert the yaml grammar to json
$ npx js-yaml syntaxes/abc.tmLanguage.yaml > syntaxes/abc.tmLanguage.json
Injektionsgrammatiken
Injektionsgrammatiken ermöglichen es Ihnen, eine bestehende Grammatik zu erweitern. Eine Injektionsgrammatik ist eine reguläre TextMate-Grammatik, die in einen bestimmten Scope innerhalb einer bestehenden Grammatik injiziert wird. Beispielanwendungen von Injektionsgrammatiken
- Hervorheben von Schlüsselwörtern wie
TODOin Kommentaren. - Hinzufügen spezifischerer Scope-Informationen zu einer bestehenden Grammatik.
- Hinzufügen von Hervorhebungen für eine neue Sprache zu Markdown-Codeblöcken.
Erstellen einer grundlegenden Injektionsgrammatik
Injektionsgrammatiken werden über die package.json beigesteuert, genau wie reguläre Grammatiken. Anstatt jedoch eine language anzugeben, verwendet eine Injektionsgrammatik injectTo, um eine Liste von Zielsprach-Scopes anzugeben, in die die Grammatik injiziert werden soll.
Für dieses Beispiel erstellen wir eine einfache Injektionsgrammatik, die TODO als Schlüsselwort in JavaScript-Kommentaren hervorhebt. Um unsere Injektionsgrammatik in JavaScript-Dateien anzuwenden, verwenden wir den Zielsprach-Scope source.js in injectTo
{
"contributes": {
"grammars": [
{
"path": "./syntaxes/injection.json",
"scopeName": "todo-comment.injection",
"injectTo": ["source.js"]
}
]
}
}
Die Grammatik selbst ist eine Standard-TextMate-Grammatik, mit Ausnahme des Top-Level-Eintrags injectionSelector. Der injectionSelector ist ein Scope-Selektor, der angibt, in welchen Scopes die injizierte Grammatik angewendet werden soll. Für unser Beispiel möchten wir das Wort TODO in allen //-Kommentaren hervorheben. Mit dem Scope Inspector finden wir heraus, dass die doppelte Schrägstrich-Kommentare von JavaScript den Scope comment.line.double-slash haben, daher ist unser Injection Selector L:comment.line.double-slash
{
"scopeName": "todo-comment.injection",
"injectionSelector": "L:comment.line.double-slash",
"patterns": [
{
"include": "#todo-keyword"
}
],
"repository": {
"todo-keyword": {
"match": "TODO",
"name": "keyword.todo"
}
}
}
Das L: im Injection Selector bedeutet, dass die Injektion links von den bestehenden Grammatikregeln hinzugefügt wird. Dies bedeutet im Wesentlichen, dass die Regeln unserer injizierten Grammatik vor allen bestehenden Grammatikregeln angewendet werden.
Eingebettete Sprachen
Injektionsgrammatiken können auch eingebettete Sprachen zu ihrer übergeordneten Grammatik beisteuern. Genau wie bei einer normalen Grammatik kann eine Injektionsgrammatik embeddedLanguages verwenden, um Scopes aus der eingebetteten Sprache einem Sprach-Scope der obersten Ebene zuzuordnen.
Eine Erweiterung, die SQL-Abfragen in JavaScript-Zeichenfolgen hervorhebt, kann beispielsweise embeddedLanguages verwenden, um sicherzustellen, dass alle Tokens innerhalb der Zeichenfolge, die als meta.embedded.inline.sql markiert ist, als SQL für grundlegende Sprachfunktionen wie Klammerung und Snippet-Auswahl behandelt werden.
{
"contributes": {
"grammars": [
{
"path": "./syntaxes/injection.json",
"scopeName": "sql-string.injection",
"injectTo": ["source.js"],
"embeddedLanguages": {
"meta.embedded.inline.sql": "sql"
}
}
]
}
}
Token-Typen und eingebettete Sprachen
Es gibt eine zusätzliche Komplikation für Injektionssprachen und eingebettete Sprachen: Standardmäßig behandelt VS Code alle Tokens innerhalb einer Zeichenfolge als Zeichenfolgeninhalt und alle Tokens mit einem Kommentar als Tokeninhalt. Da Funktionen wie Klammerung und automatische Vervollständigung von Paaren innerhalb von Zeichenfolgen und Kommentaren deaktiviert sind, werden diese Funktionen auch in der eingebetteten Sprache deaktiviert, wenn die eingebettete Sprache innerhalb einer Zeichenfolge oder eines Kommentars erscheint.
Um dieses Verhalten zu überschreiben, können Sie einen meta.embedded.*-Scope verwenden, um die Markierung von Tokens als Zeichenfolgen- oder Kommentarinhalt durch VS Code zurückzusetzen. Es ist eine gute Idee, eingebettete Sprachen immer in einen meta.embedded.*-Scope zu verpacken, um sicherzustellen, dass VS Code die eingebettete Sprache ordnungsgemäß behandelt.
Wenn Sie Ihrer Grammatik keinen meta.embedded.*-Scope hinzufügen können, können Sie alternativ tokenTypes im Beitragspunkt der Grammatik verwenden, um bestimmte Scopes einem Inhaltsmodus zuzuordnen. Der folgende Abschnitt tokenTypes stellt sicher, dass jeder Inhalt im Scope my.sql.template.string als Quellcode behandelt wird
{
"contributes": {
"grammars": [
{
"path": "./syntaxes/injection.json",
"scopeName": "sql-string.injection",
"injectTo": ["source.js"],
"embeddedLanguages": {
"my.sql.template.string": "sql"
},
"tokenTypes": {
"my.sql.template.string": "other"
}
}
]
}
}
Theming
Theming befasst sich mit der Zuweisung von Farben und Stilen zu Tokens. Theming-Regeln werden in Farbschemata (Color Themes) definiert, aber Benutzer können die Theming-Regeln in den Benutzereinstellungen anpassen.
TextMate-Theming-Regeln werden in tokenColors definiert und haben die gleiche Syntax wie reguläre TextMate-Themes. Jede Regel definiert einen TextMate-Scope-Selektor und die resultierende Farbe und den Stil.
Bei der Auswertung der Farbe und des Stils eines Tokens wird der aktuelle Token-Scope mit dem Selektor der Regel abgeglichen, um die spezifischste Regel für jede Stileigenschaft (Vordergrund, Fett, Kursiv, Unterstrichen) zu finden.
Der Leitfaden zu Farbschemata beschreibt, wie man ein Farbschema erstellt. Theming für semantische Tokens wird im Leitfaden zur semantischen Hervorhebung erläutert.
Scope Inspector
Das integrierte Scope Inspector-Tool von VS Code hilft beim Debuggen von Grammatiken und semantischen Tokens. Es zeigt die Scopes für das Token und die semantischen Tokens an der aktuellen Position in einer Datei an, zusammen mit Metadaten darüber, welche Theme-Regeln auf dieses Token zutreffen.
Aktivieren Sie den Scope Inspector über die Befehlspalette mit dem Befehl Developer: Inspect Editor Tokens and Scopes oder erstellen Sie eine Tastenkombination dafür
{
"key": "cmd+alt+shift+i",
"command": "editor.action.inspectTMScopes"
}
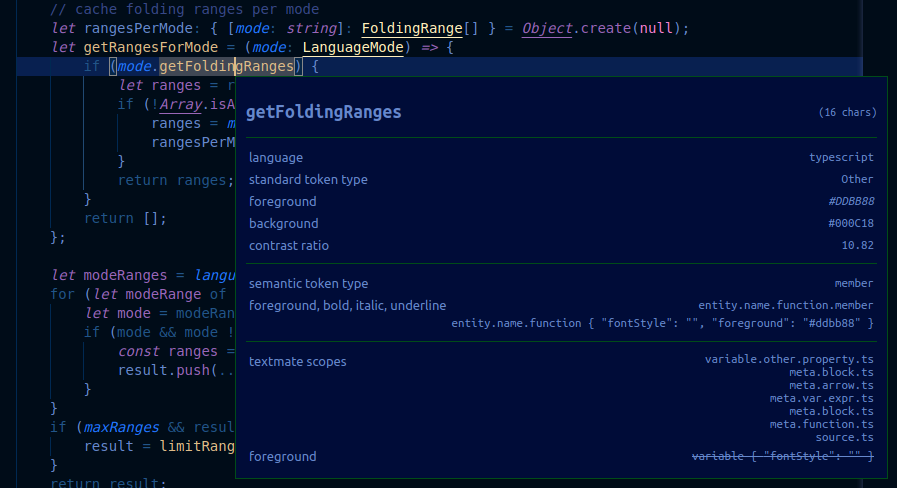
Der Scope Inspector zeigt die folgenden Informationen an
- Das aktuelle Token.
- Metadaten zum Token und Informationen zu seinem berechneten Erscheinungsbild. Wenn Sie mit eingebetteten Sprachen arbeiten, sind die wichtigen Einträge hier
languageundtoken type. - Der Abschnitt für semantische Tokens wird angezeigt, wenn für die aktuelle Sprache ein semantischer Token-Provider verfügbar ist und das aktuelle Theme semantische Hervorhebung unterstützt. Er zeigt den aktuellen semantischen Token-Typ und Modifikatoren zusammen mit den Theme-Regeln an, die dem semantischen Token-Typ und den Modifikatoren entsprechen.
- Der TextMate-Abschnitt zeigt die Scope-Liste für das aktuelle TextMate-Token an, wobei der spezifischste Scope oben steht. Er zeigt auch die spezifischsten Theme-Regeln an, die den Scopes entsprechen. Dies zeigt nur die Theme-Regeln, die für den aktuellen Stil des Tokens verantwortlich sind, nicht überschriebene Regeln. Wenn semantische Tokens vorhanden sind, werden die Theme-Regeln nur angezeigt, wenn sie von der Regel abweichen, die dem semantischen Token entspricht.